

AI Engineer World's Fair 2026 Wrapped
Alex Lavaee Jul 6, 2026 9 min read
mixture-of-experts ~ blog
$ cat about.md
What’s working for developers, what’s changing in AI, and how to get more from coding agents.
# 59 posts · newest Jul 13, 2026
subscribe --email

$ cat latest.md
Alex Lavaee, Norin Lavaee July 13, 2026 8 min read
Read article$ ls -t blog/
58 articles after the featured dispatch
Alex Lavaee Jul 6, 2026 9 min read

Alex Lavaee, Norin Lavaee Jun 16, 2026 9 min read
$ cat production-agent-loops.md
# Building a Loop Engine
Alex Lavaee, Norin Lavaee Jun 9, 2026 17 min read
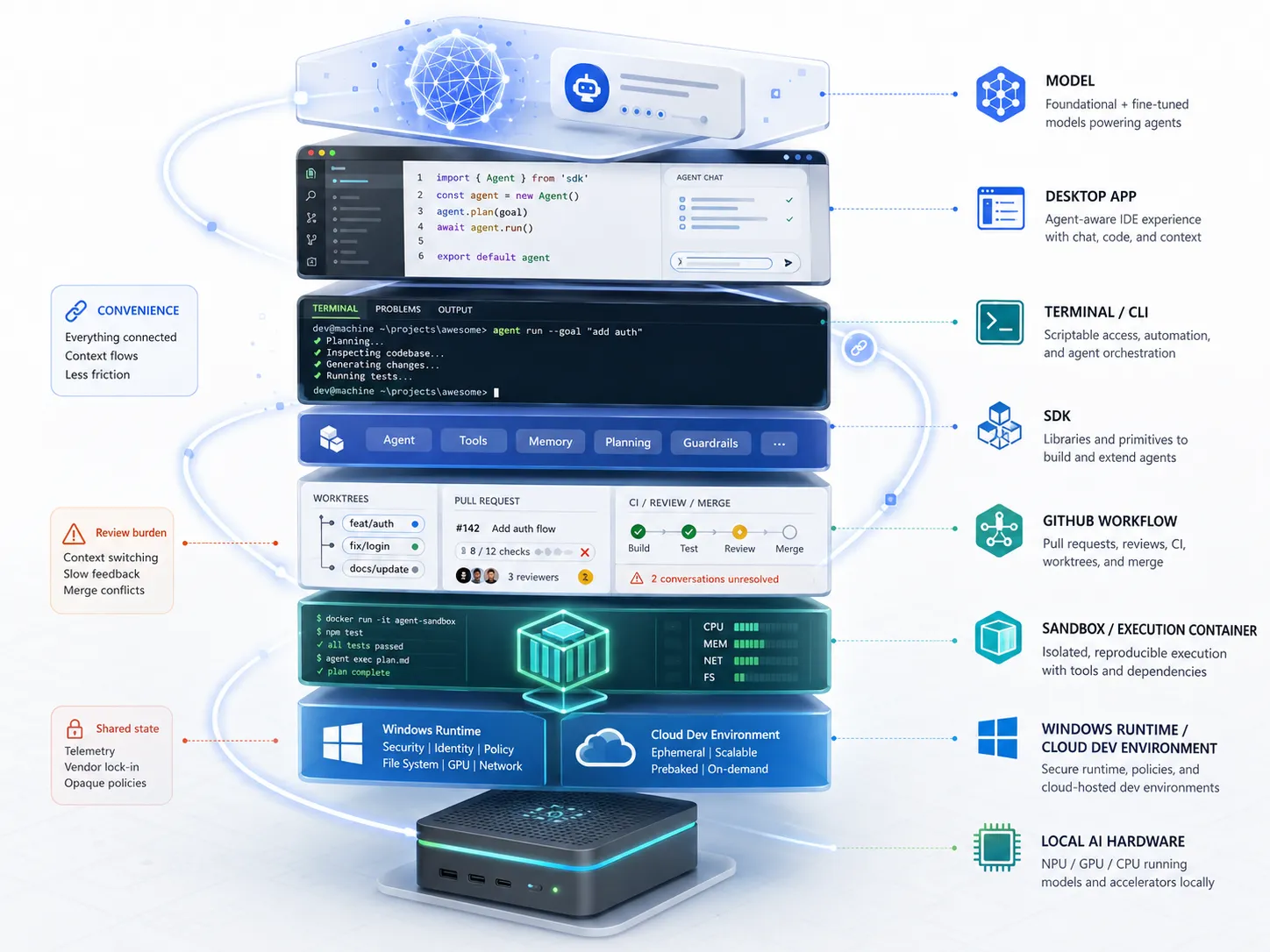
Alex Lavaee, Norin Lavaee Jun 3, 2026 6 min read
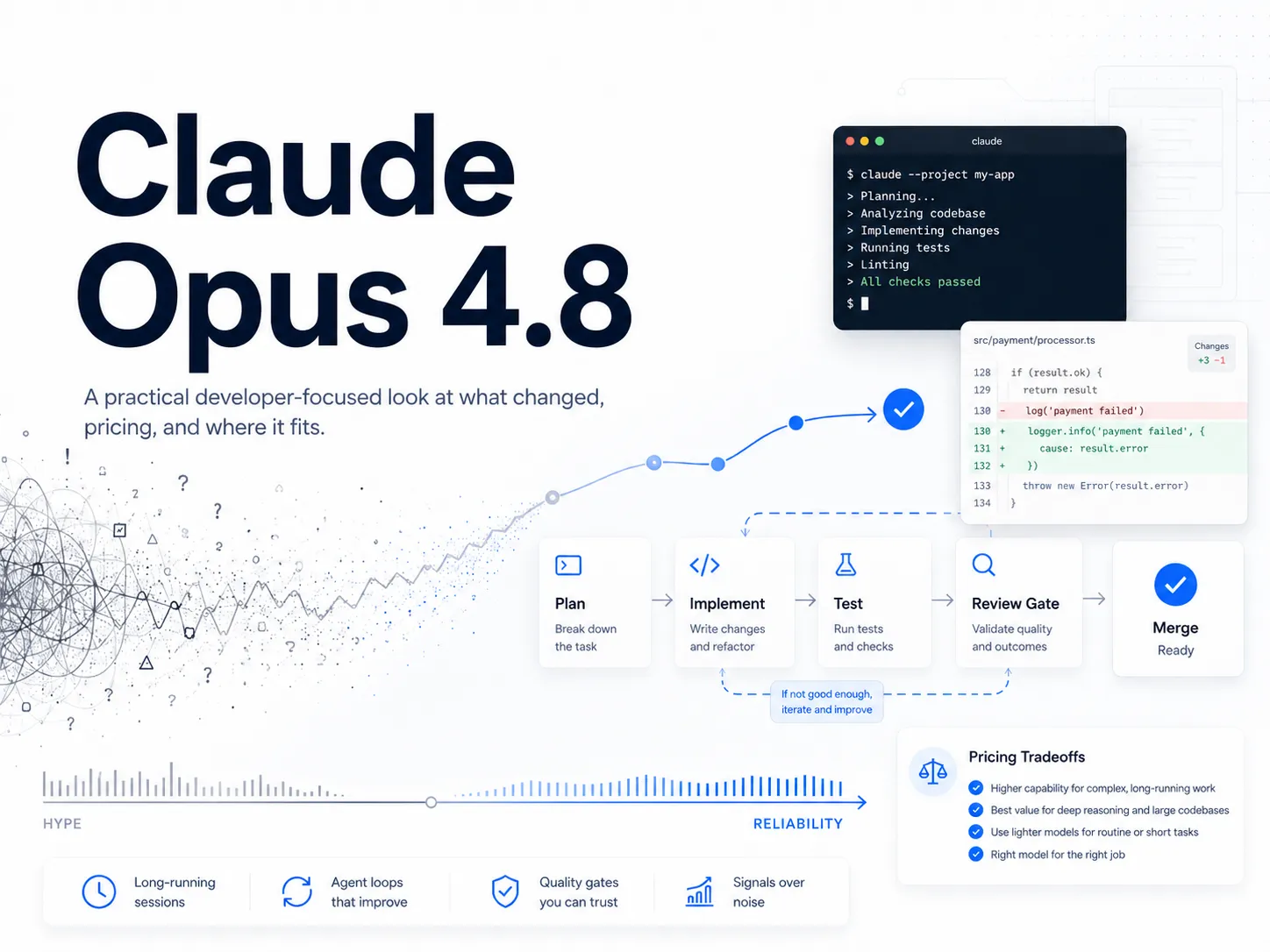
Alex Lavaee, Norin Lavaee May 29, 2026 7 min read
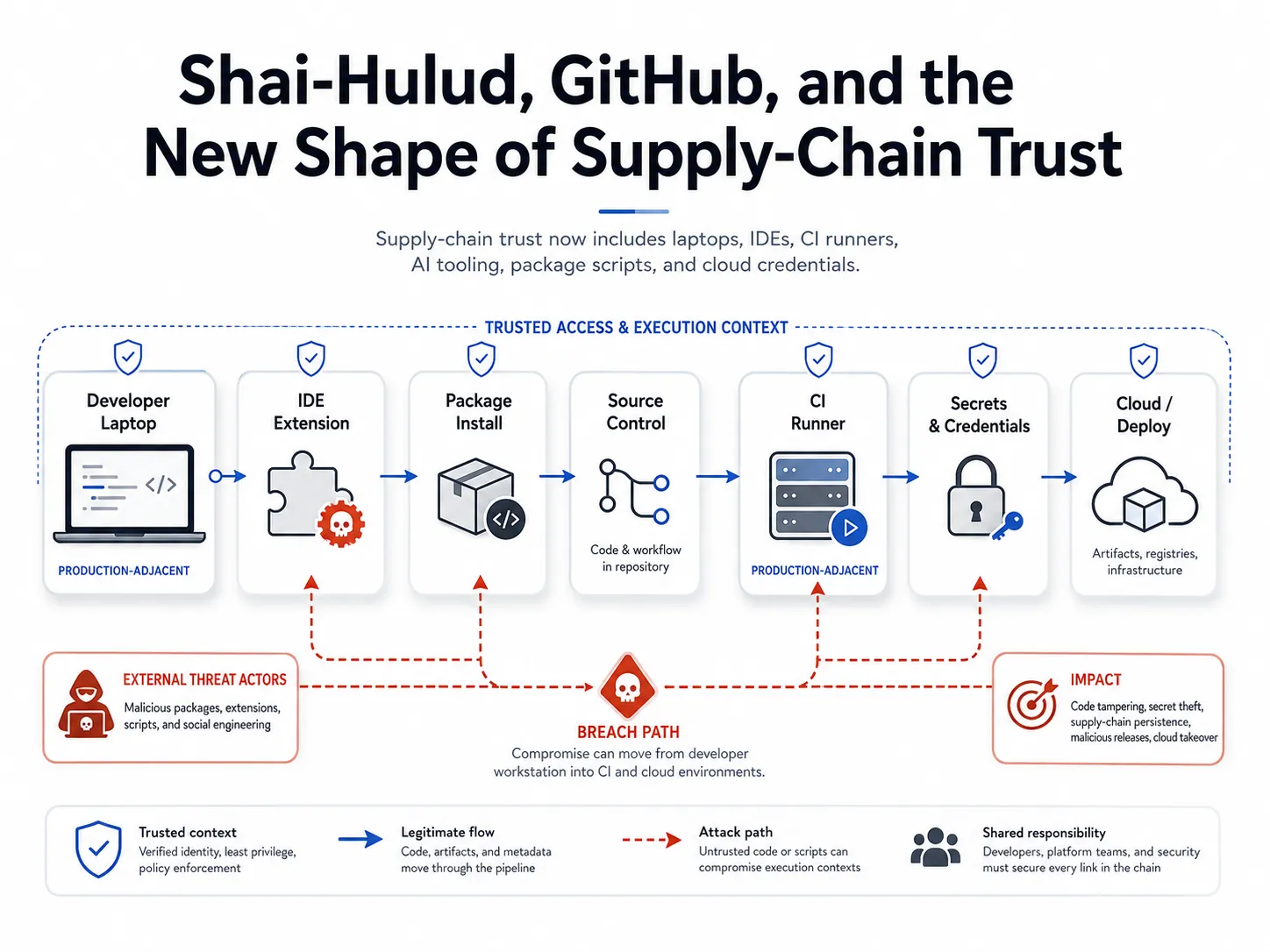
Alex Lavaee, Norin Lavaee May 28, 2026 6 min read
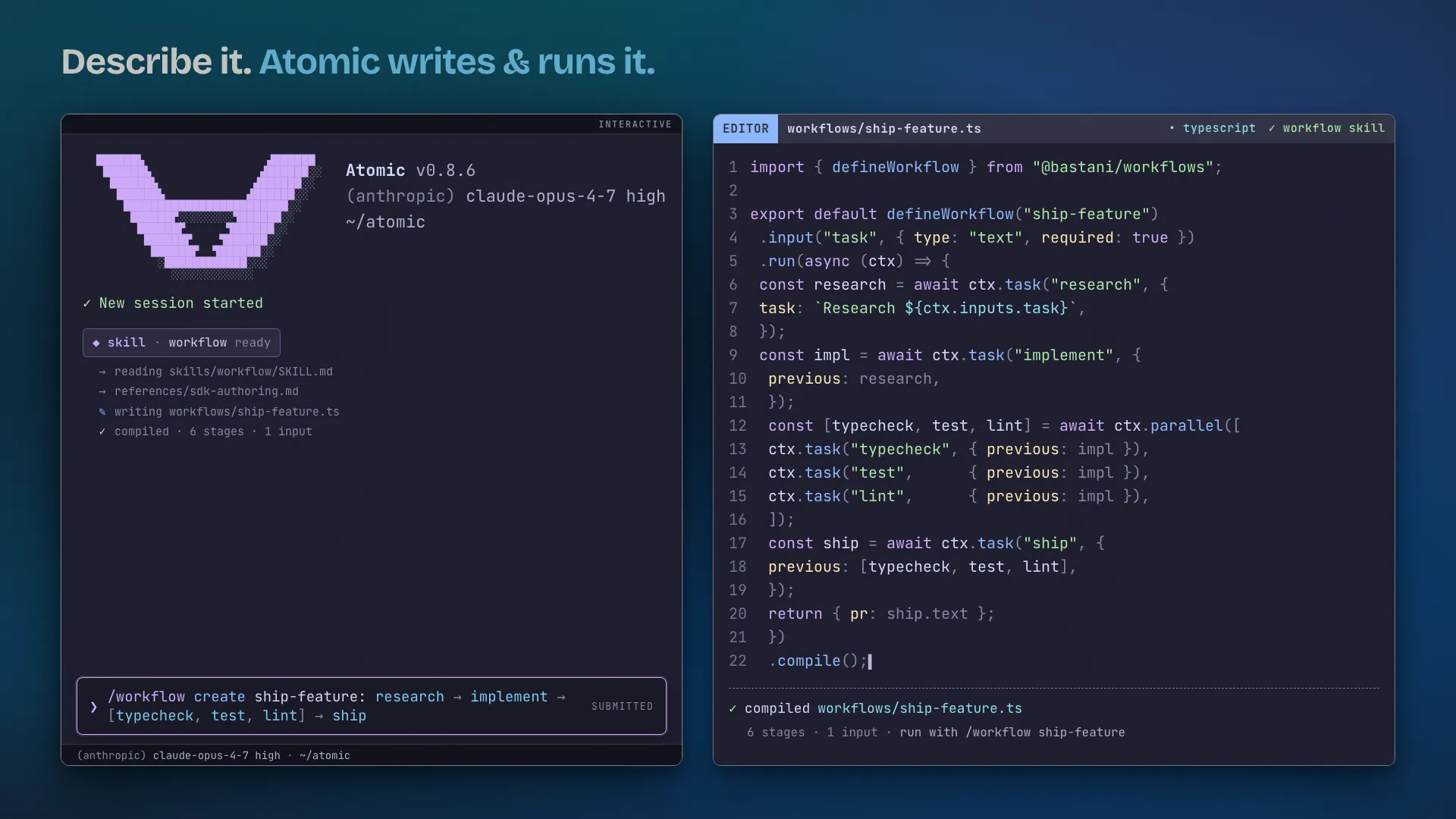
Alex Lavaee, Norin Lavaee May 28, 2026 7 min read
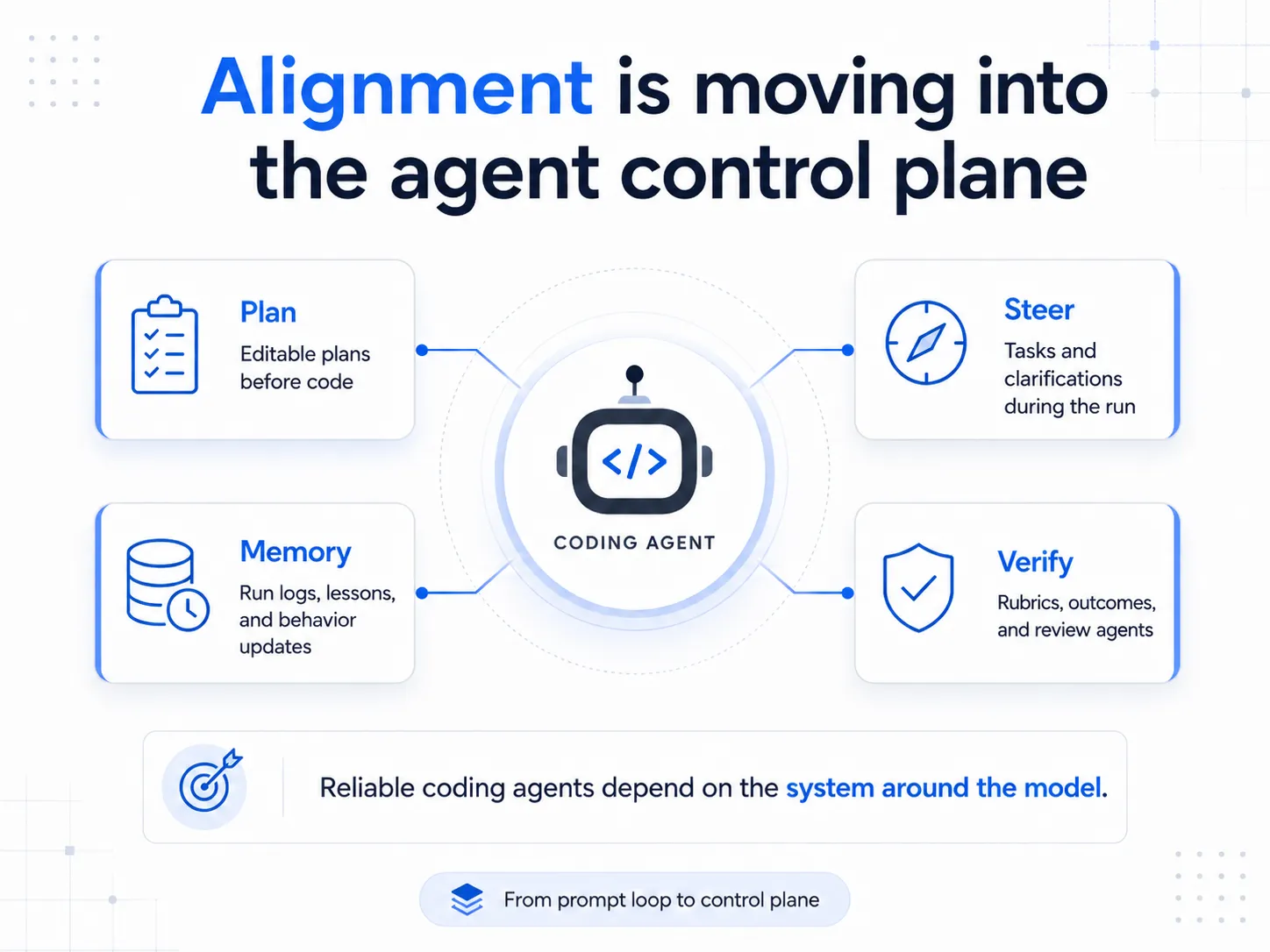
Alex Lavaee, Norin Lavaee May 26, 2026 9 min read
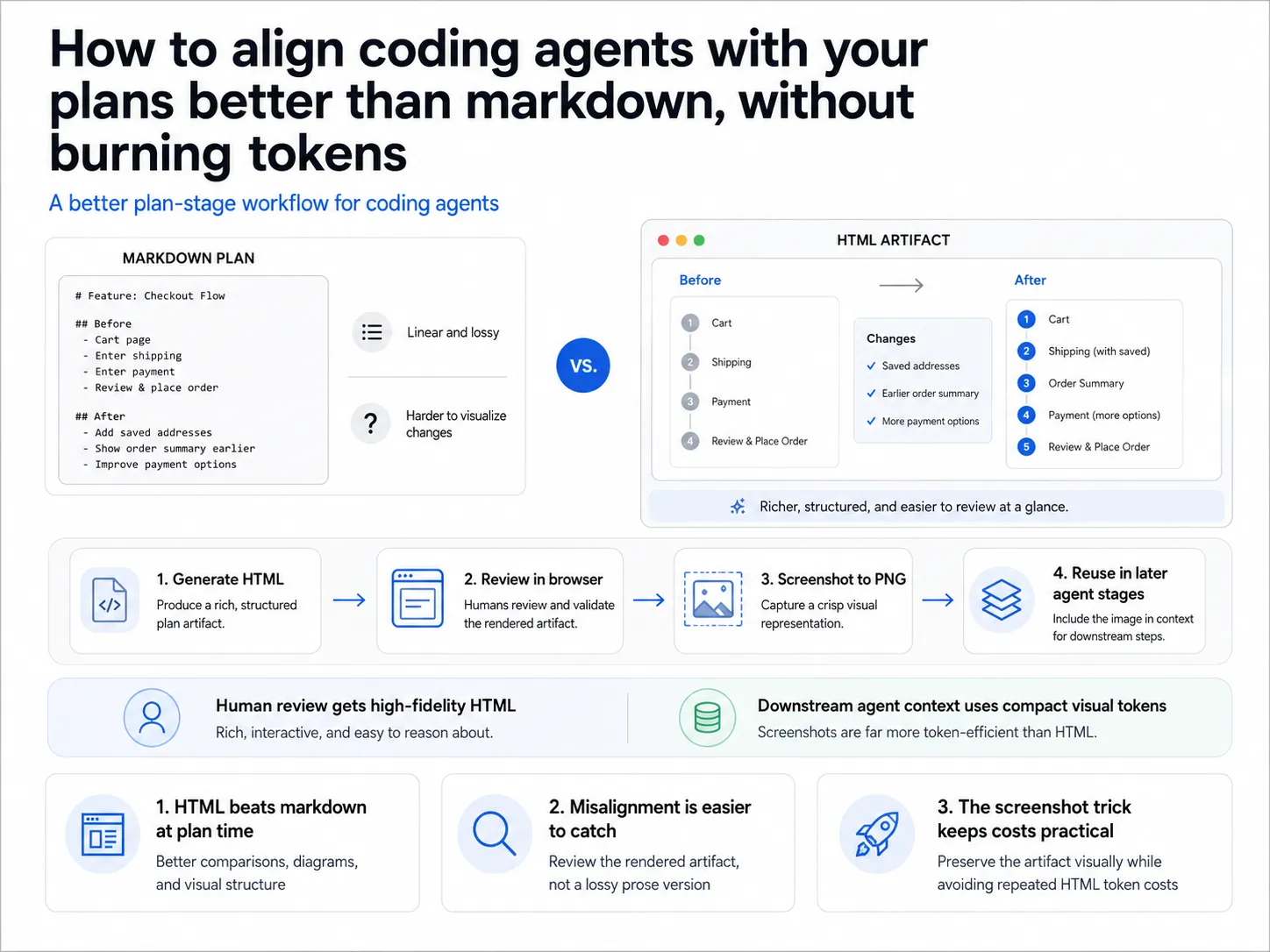
Alex Lavaee, Norin Lavaee May 13, 2026 8 min read
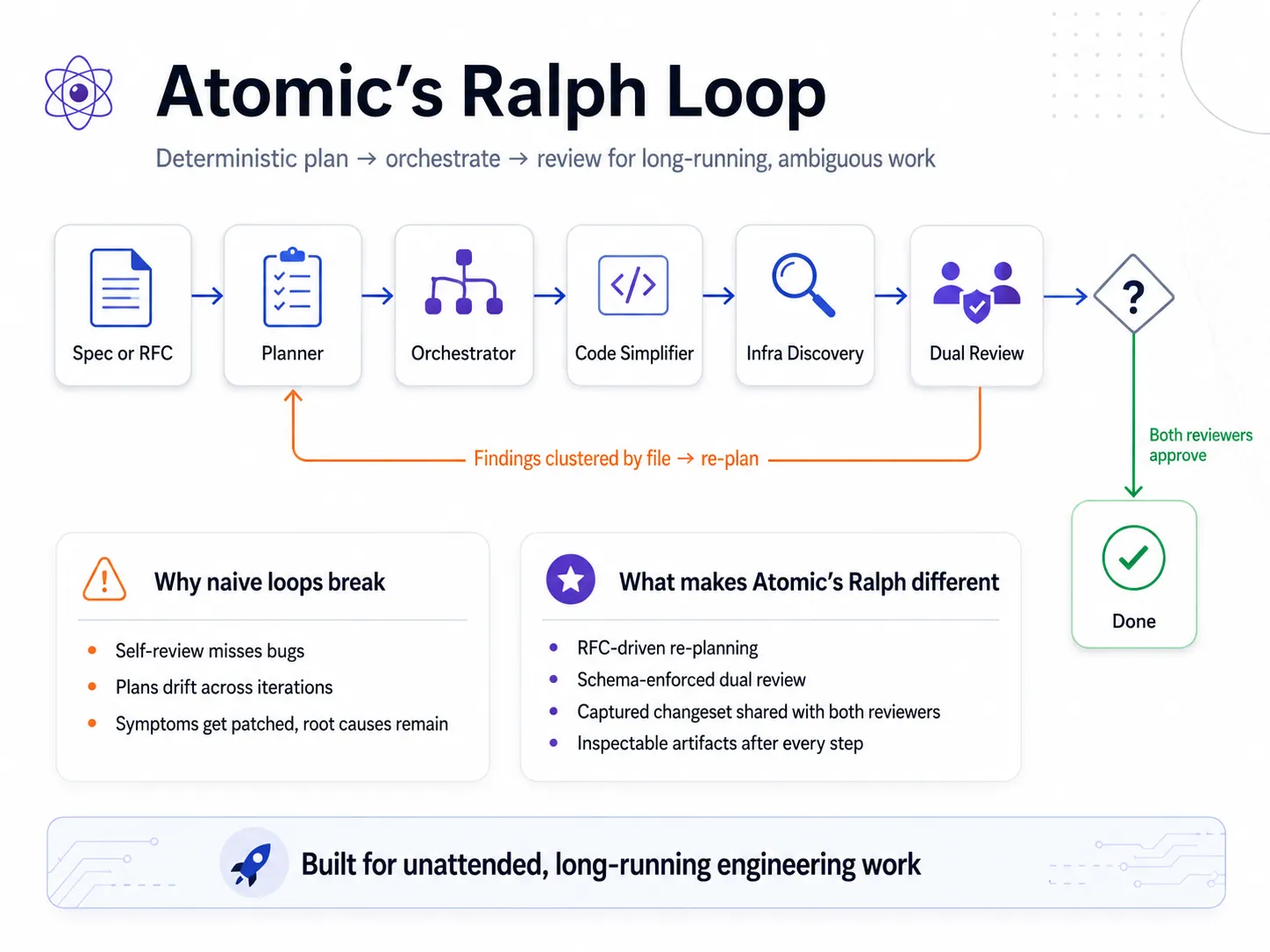
Alex Lavaee, Norin Lavaee May 7, 2026 8 min read

Alex Lavaee, Norin Lavaee May 6, 2026 5 min read

Alex Lavaee, Norin Lavaee Apr 27, 2026 11 min read

Alex Lavaee, Norin Lavaee Apr 24, 2026 9 min read
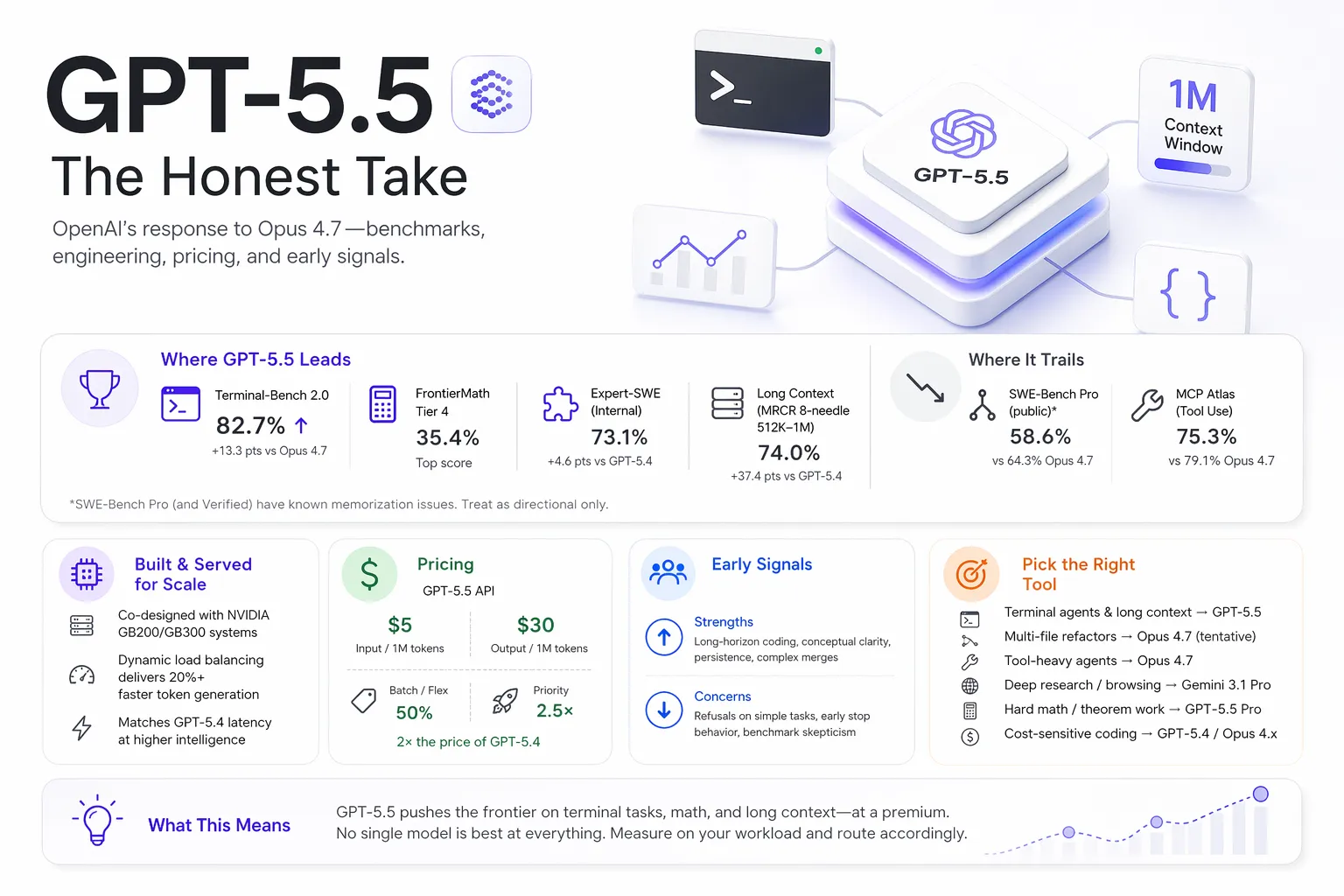
Alex Lavaee, Norin Lavaee Apr 23, 2026 11 min read
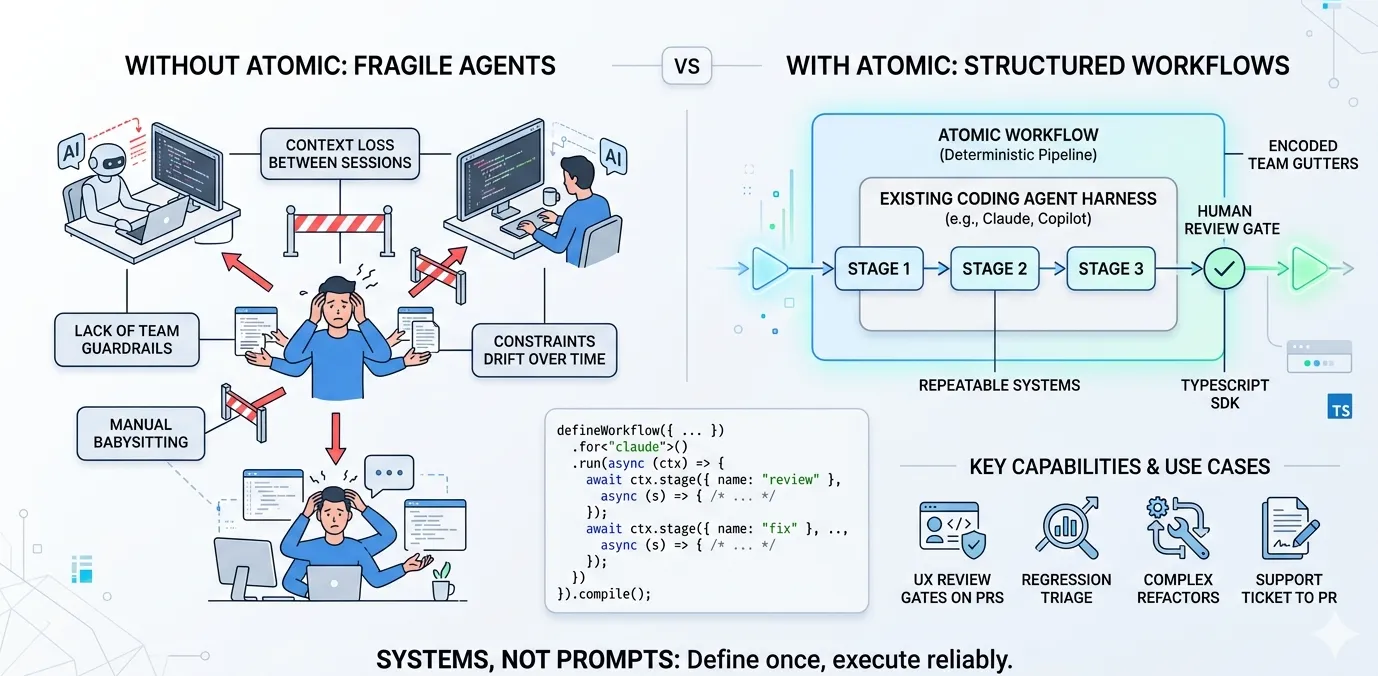
Alex Lavaee, Norin Lavaee Apr 22, 2026 6 min read
$ cat open-claude-design-atomic-harness.md
# Open Claude Design: A Weekend Harness Built on Atomic
Alex Lavaee, Norin Lavaee Apr 20, 2026 9 min read

Alex Lavaee, Norin Lavaee Apr 16, 2026 13 min read
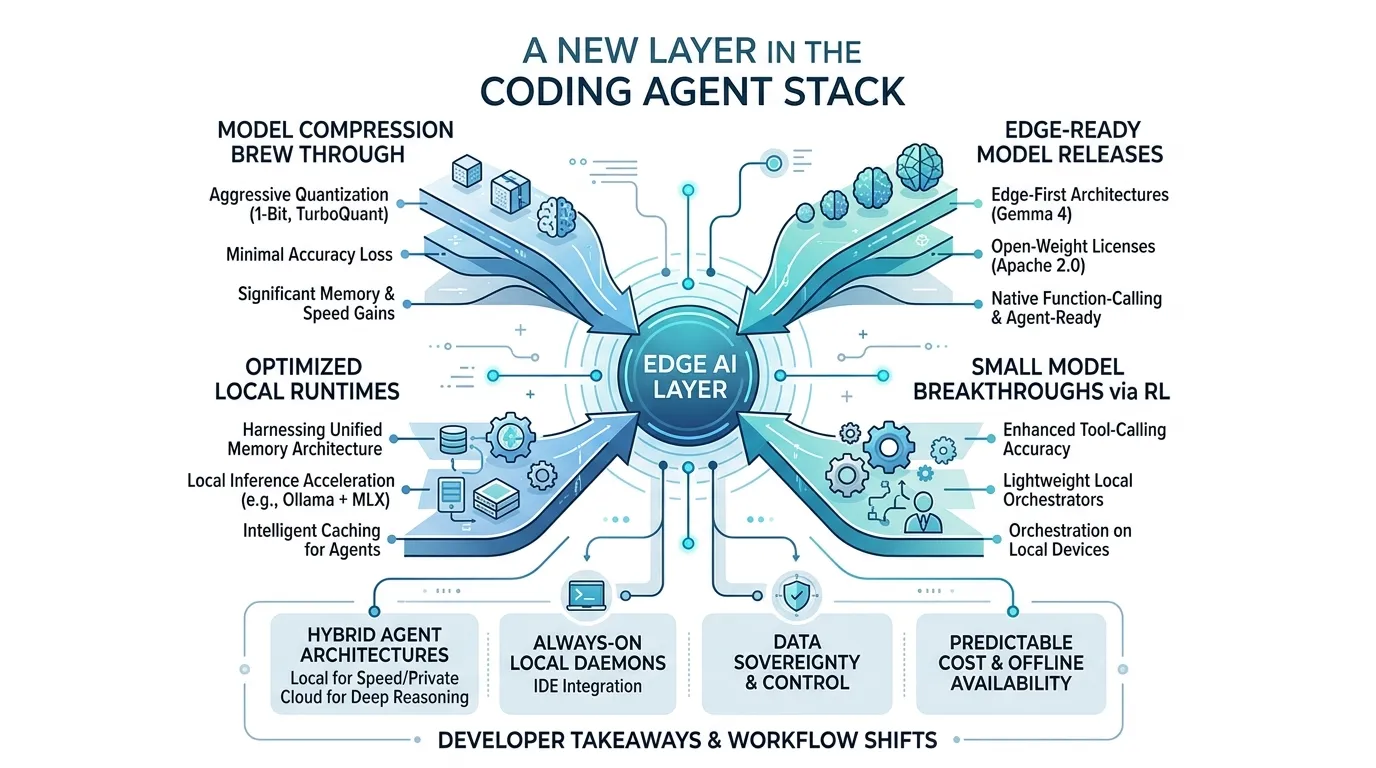
Alex Lavaee, Norin Lavaee Apr 14, 2026 20 min read
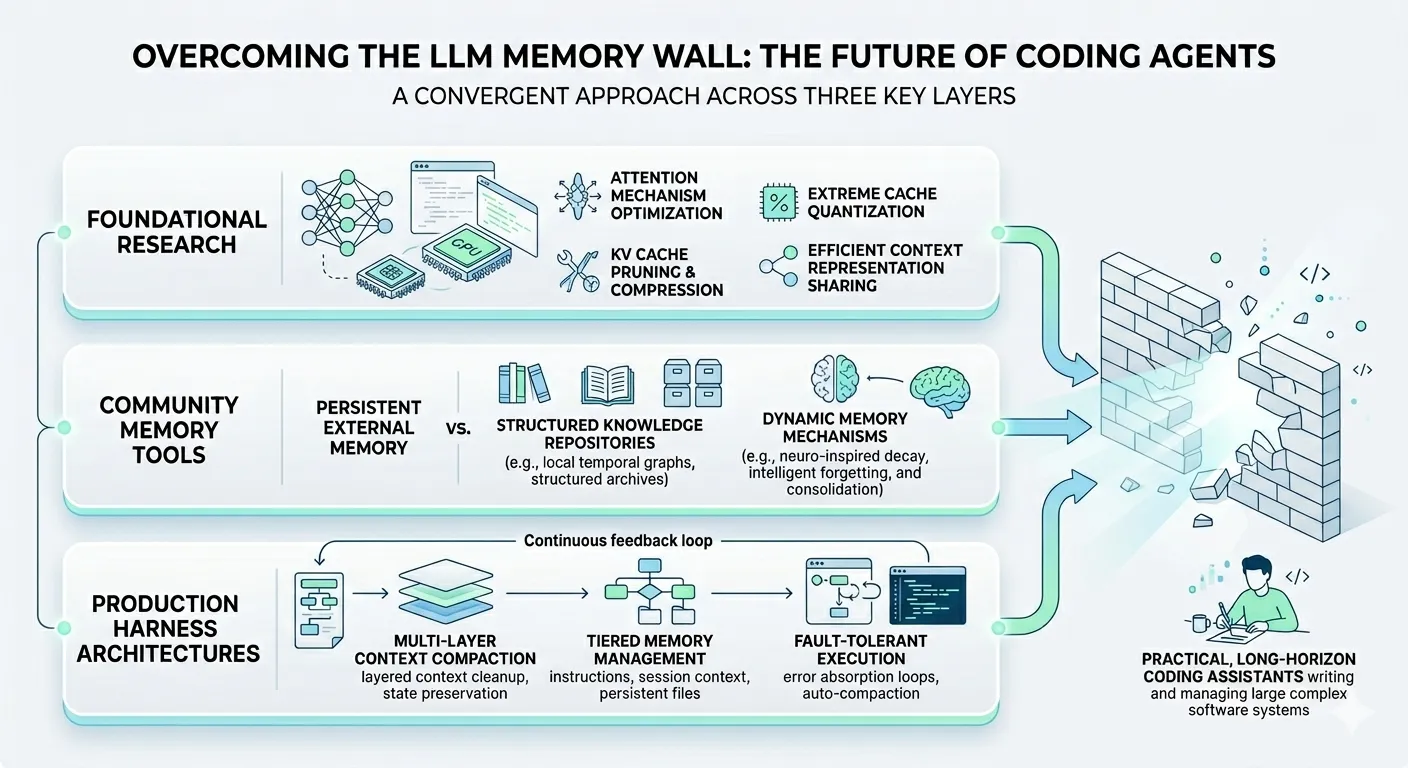
Alex Lavaee, Norin Lavaee Apr 13, 2026 18 min read
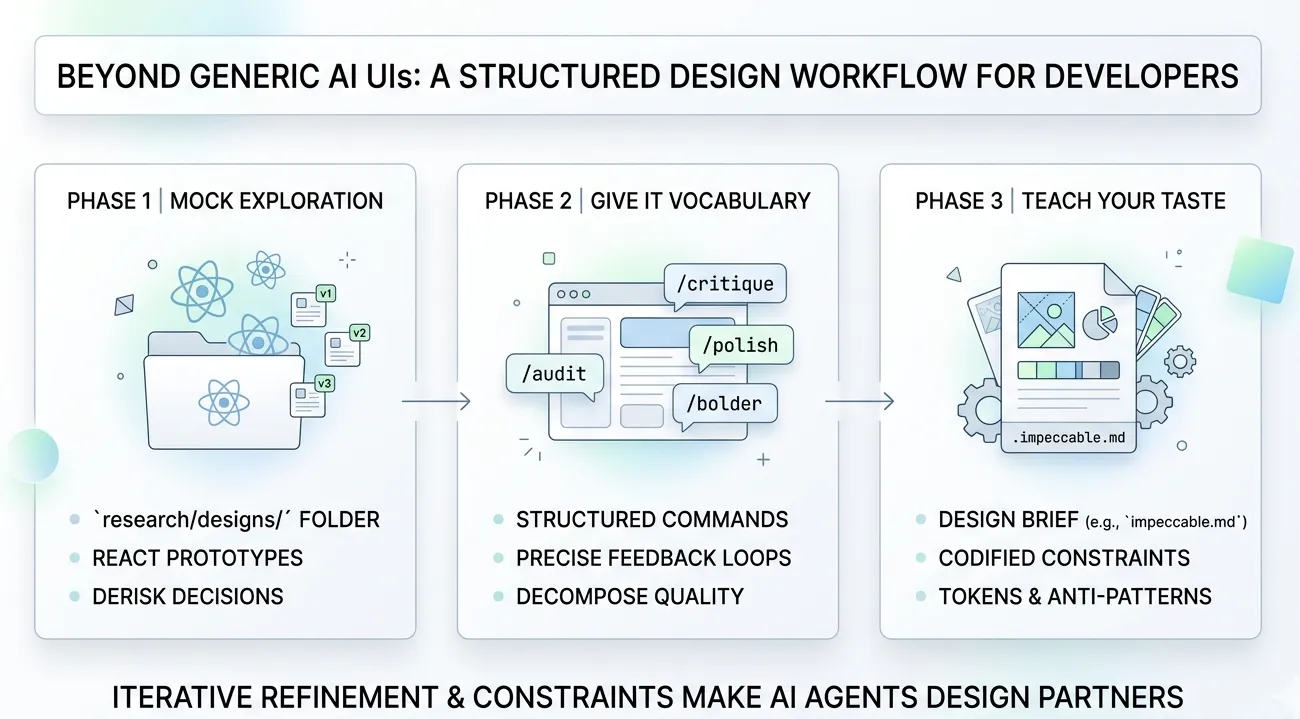
Alex Lavaee, Norin Lavaee Apr 9, 2026 15 min read
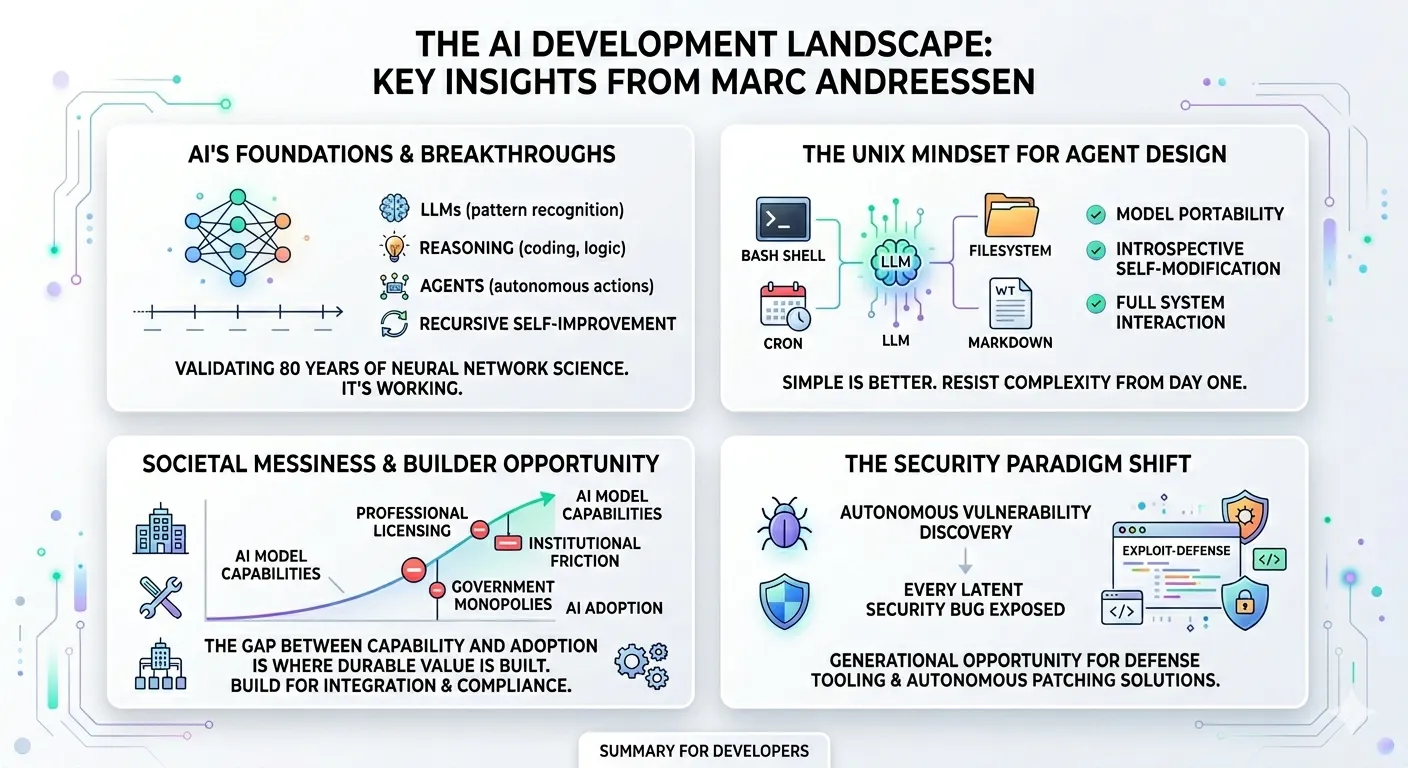
Alex Lavaee, Norin Lavaee Apr 8, 2026 14 min read
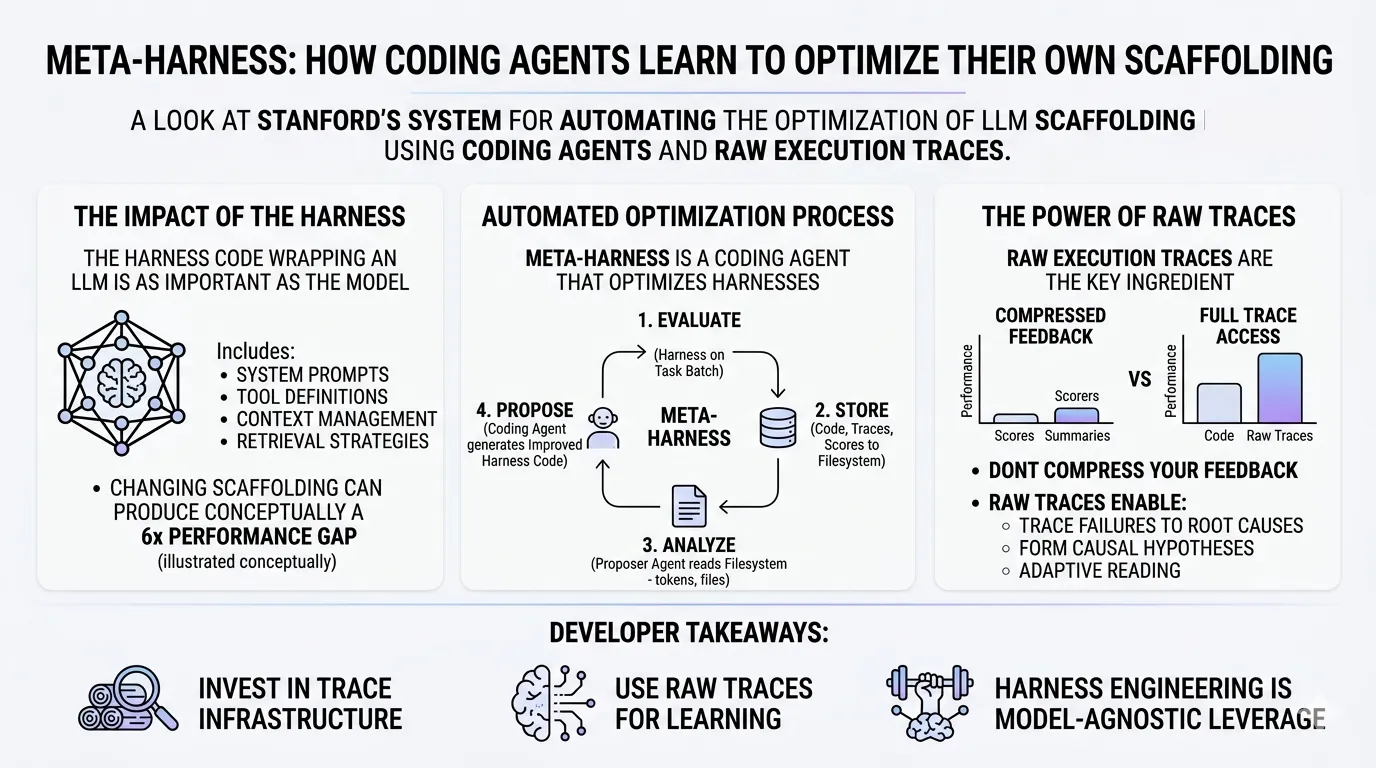
Alex Lavaee, Norin Lavaee Apr 7, 2026 8 min read
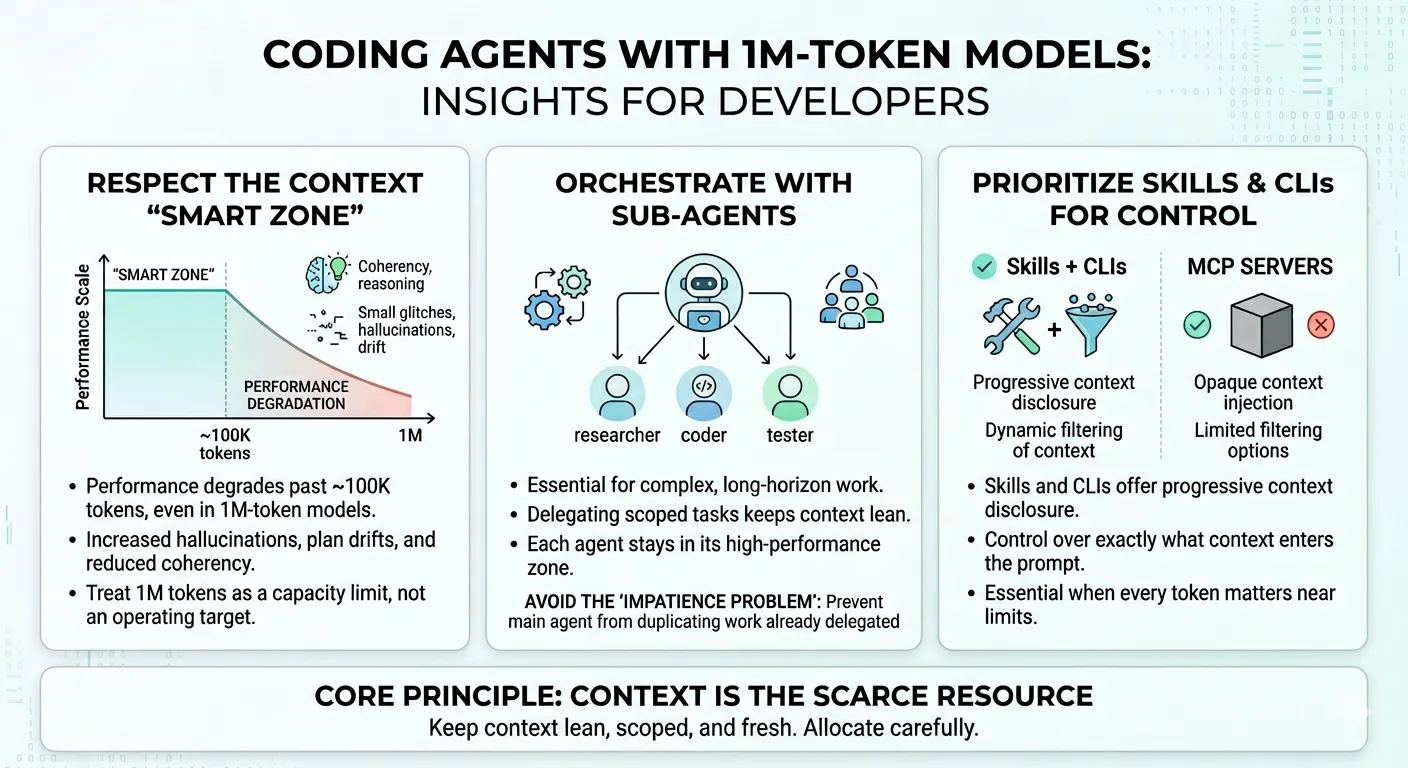
Alex Lavaee, Norin Lavaee Apr 4, 2026 9 min read
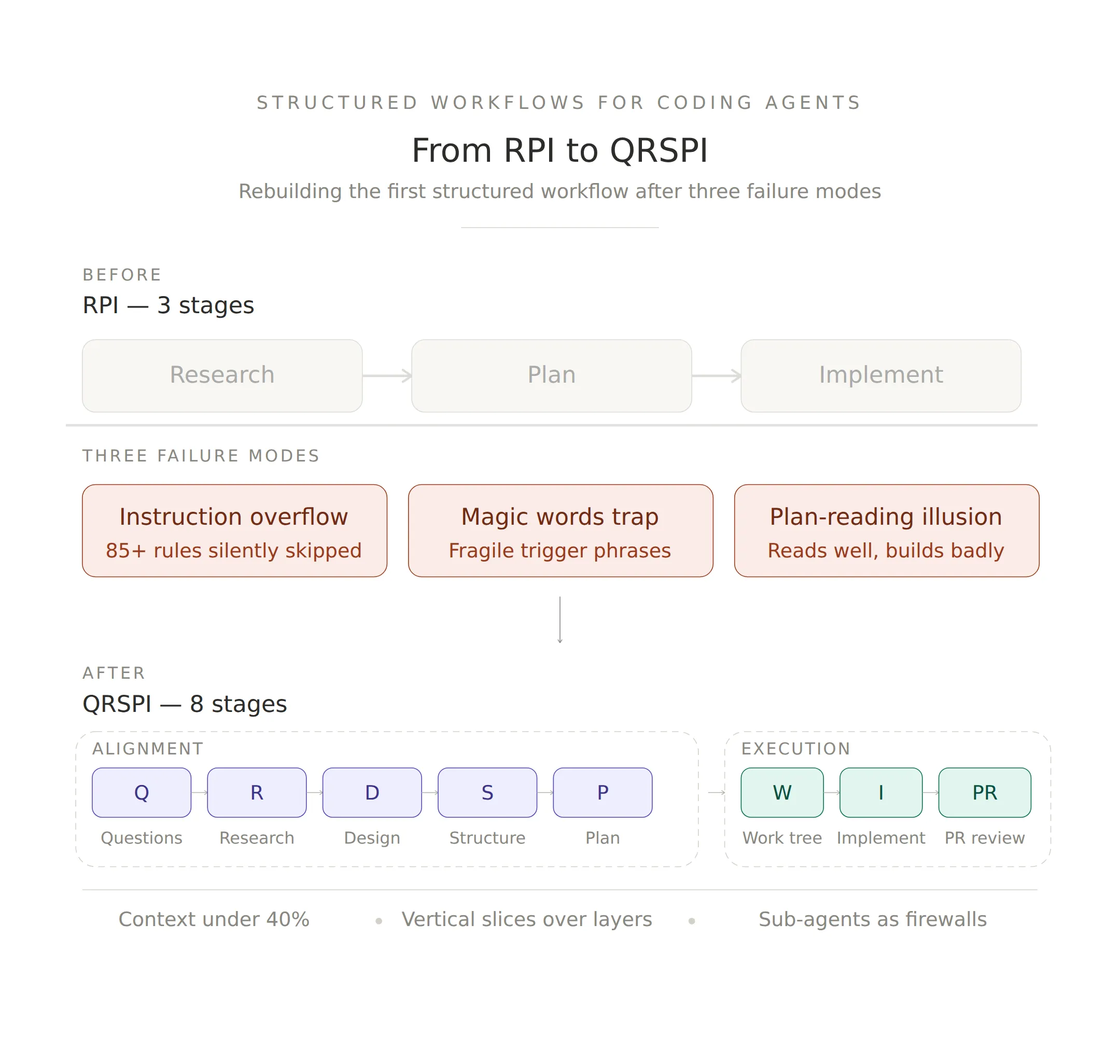
Alex Lavaee, Norin Lavaee Mar 30, 2026 12 min read
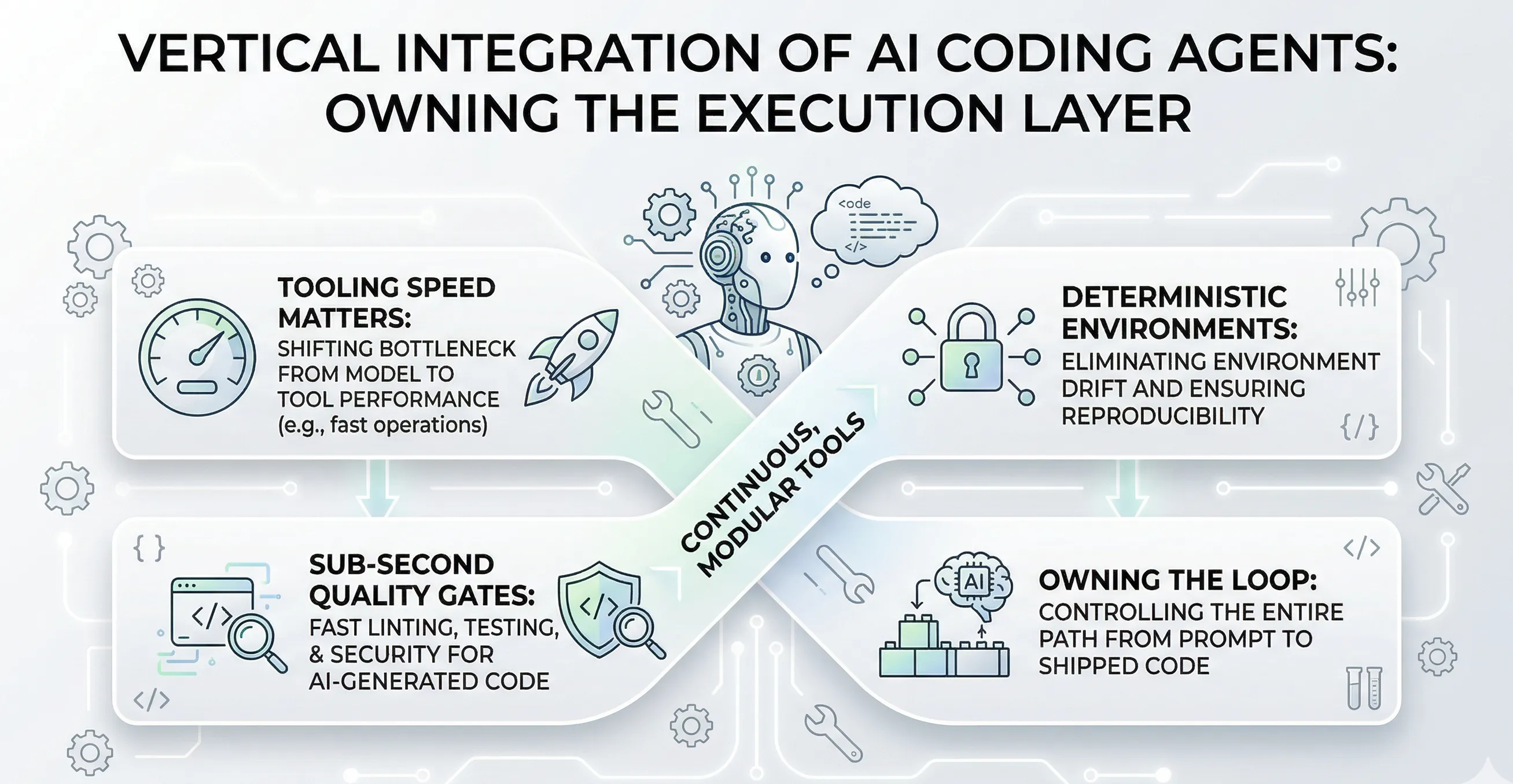
Alex Lavaee, Norin Lavaee Mar 24, 2026 10 min read
Alex Lavaee, Norin Lavaee Mar 22, 2026 8 min read
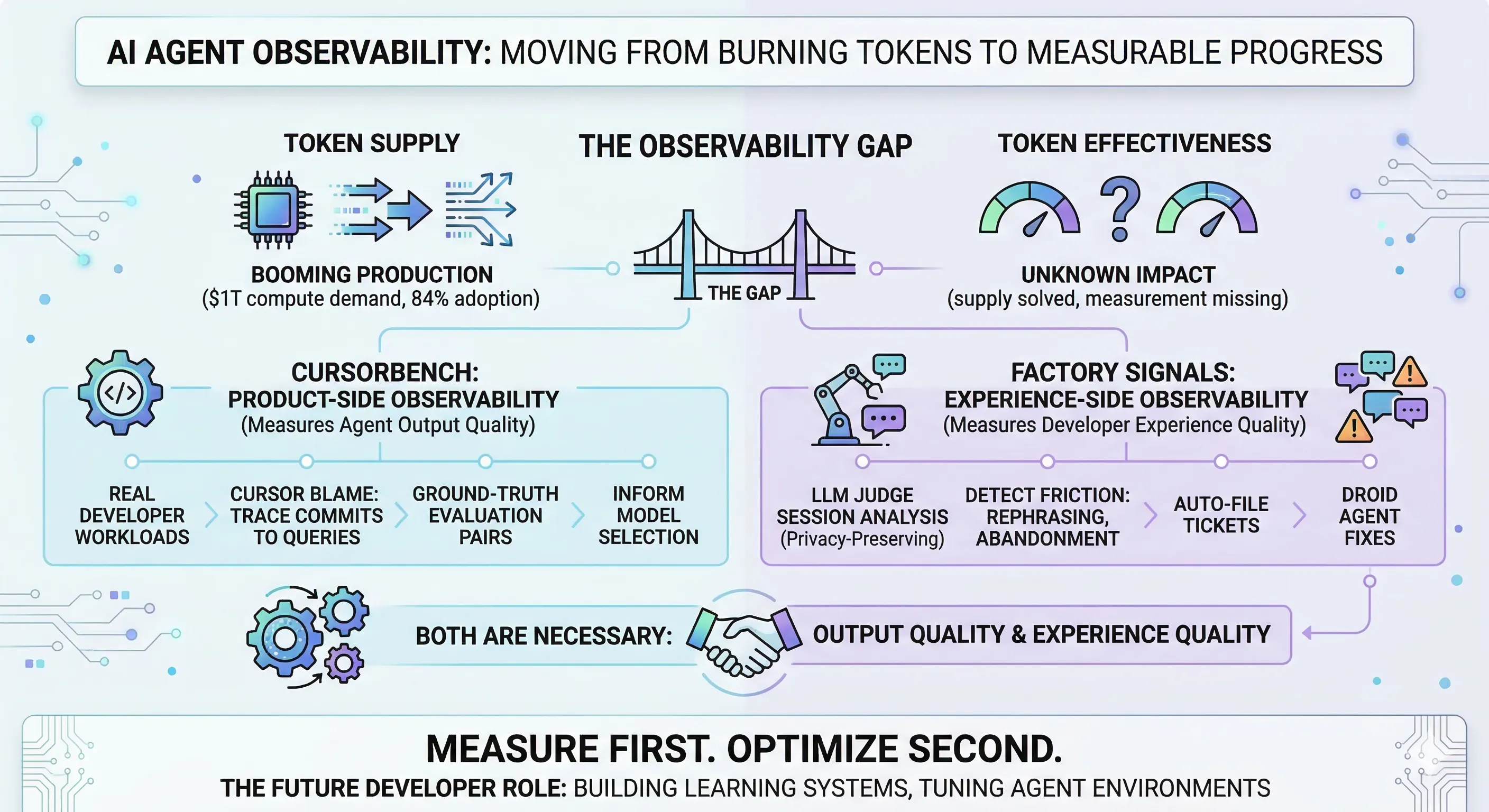
Alex Lavaee, Norin Lavaee Mar 19, 2026 8 min read
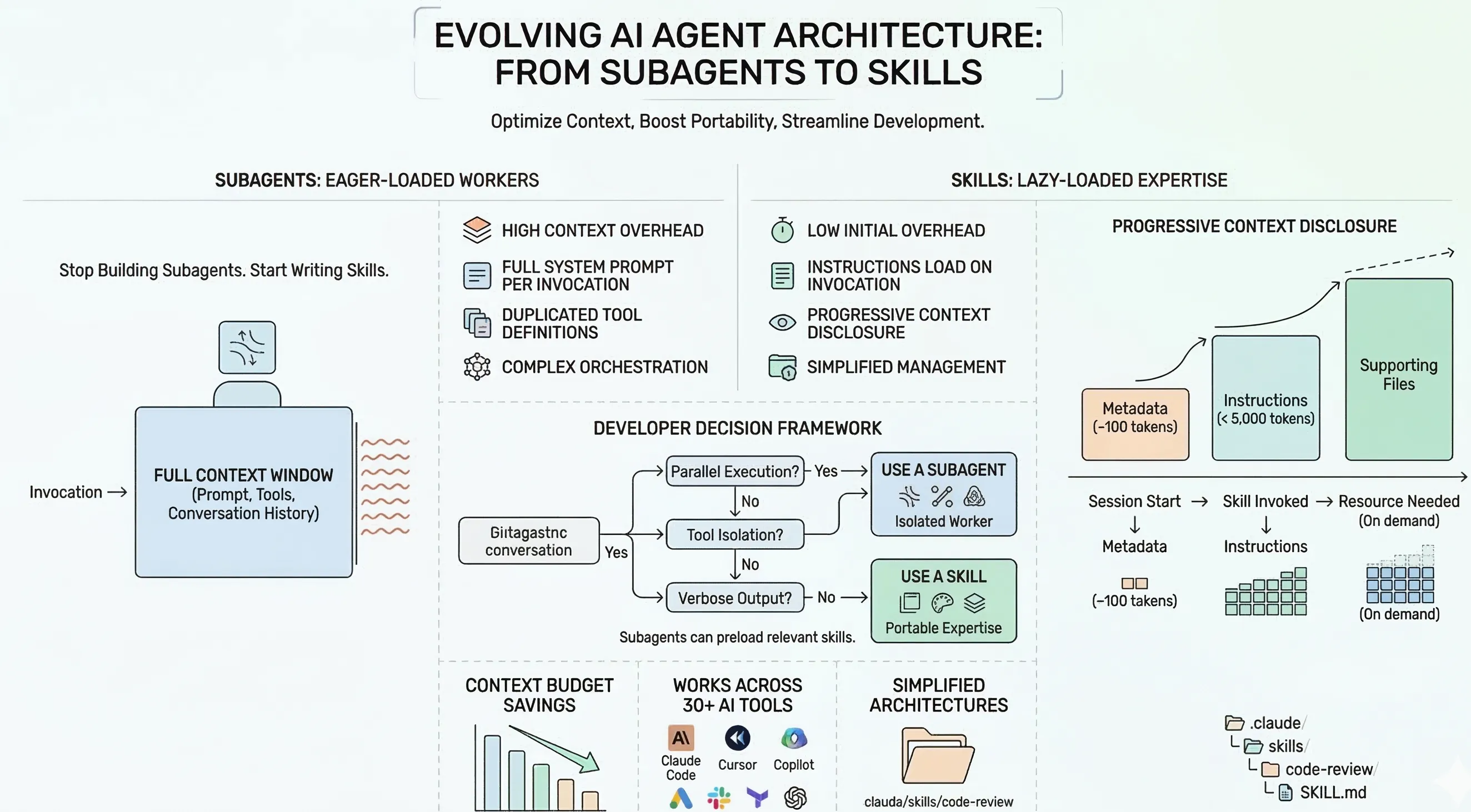
Alex Lavaee, Norin Lavaee Mar 17, 2026 7 min read
Alex Lavaee, Norin Lavaee Mar 10, 2026 13 min read
Alex Lavaee, Norin Lavaee Mar 9, 2026 16 min read
Alex Lavaee, Norin Lavaee Mar 5, 2026 12 min read
Alex Lavaee, Norin Lavaee Mar 4, 2026 11 min read
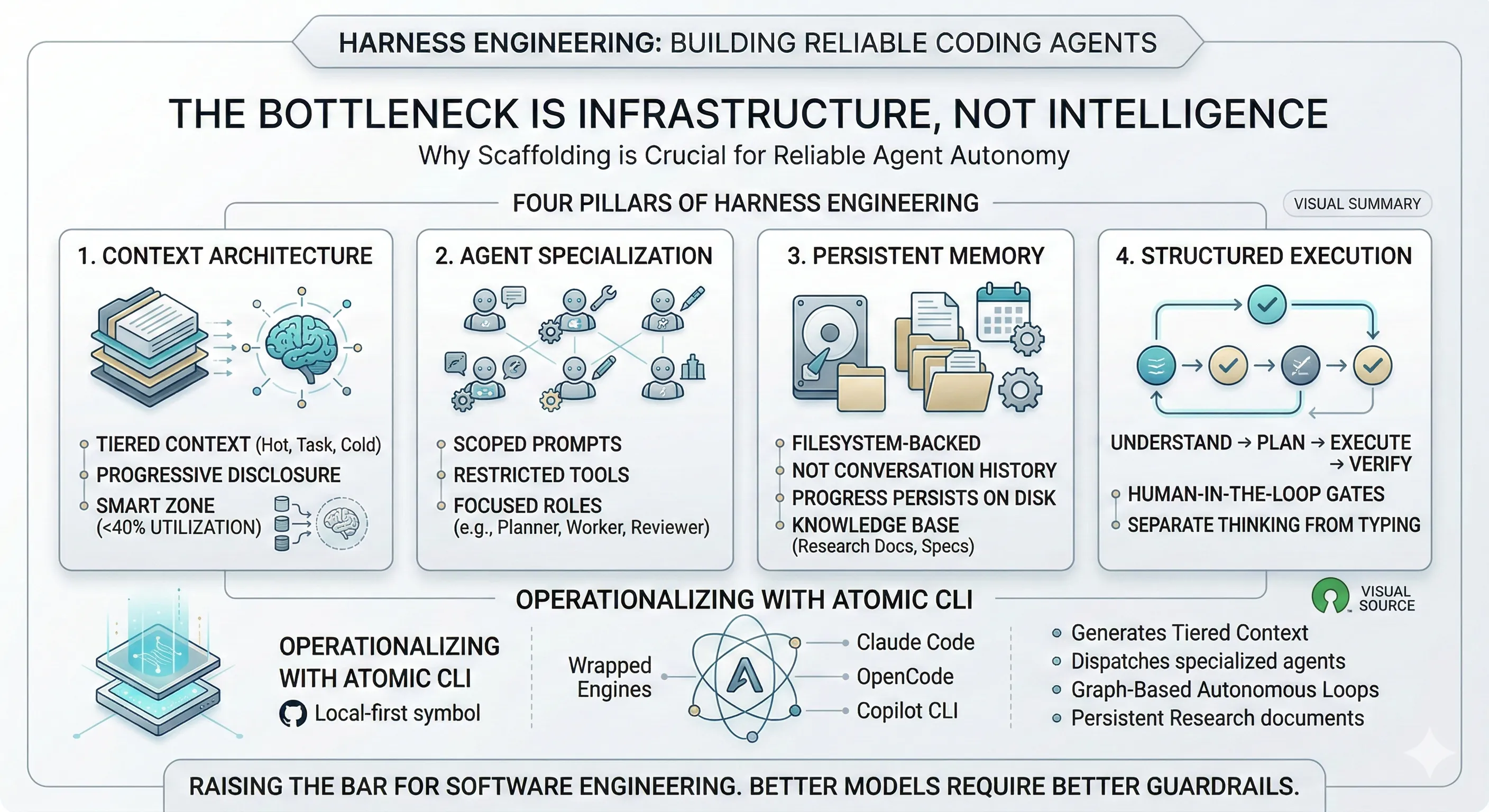
Alex Lavaee, Norin Lavaee Mar 3, 2026 18 min read
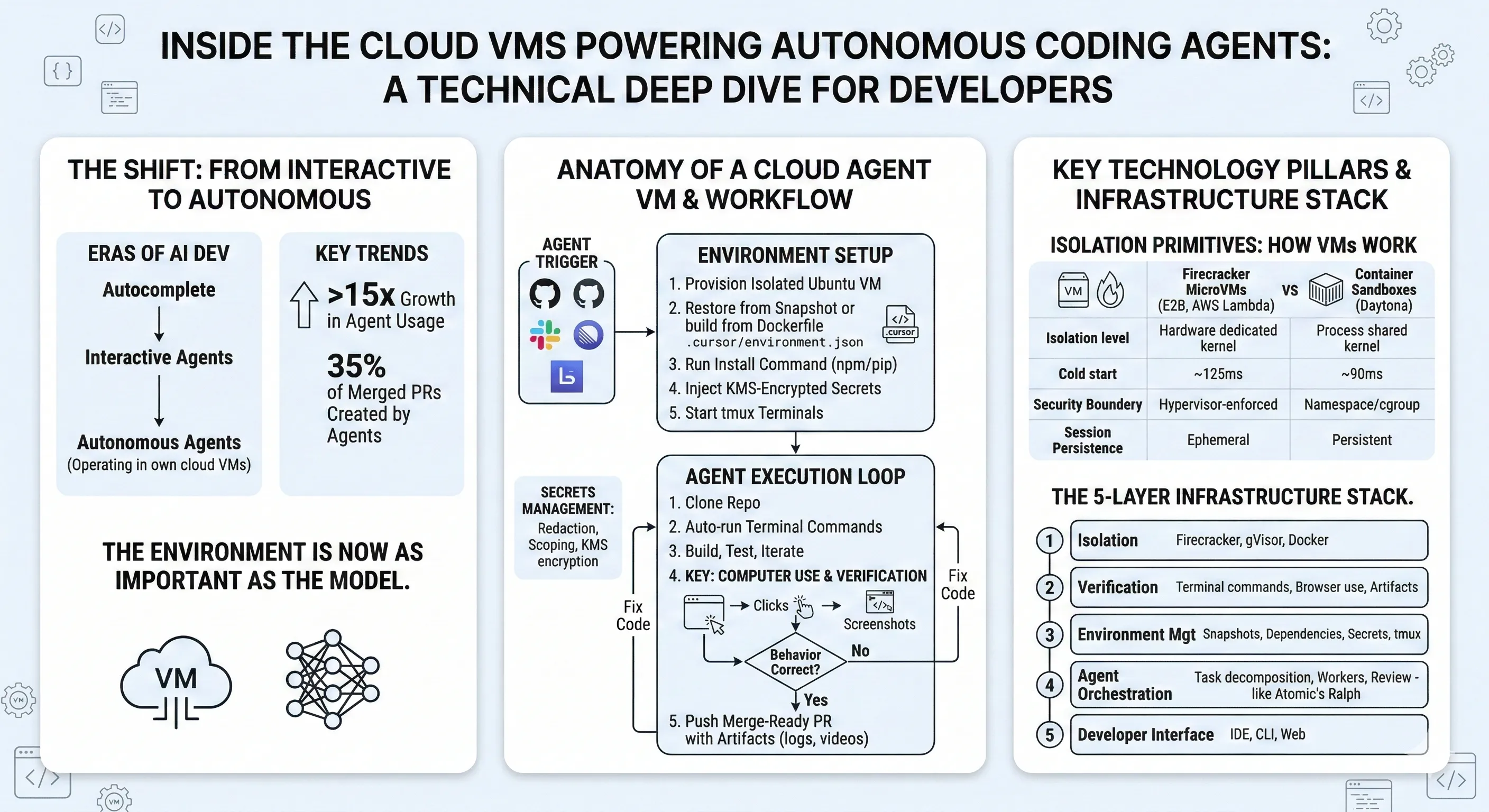
Alex Lavaee, Norin Lavaee Feb 26, 2026 14 min read
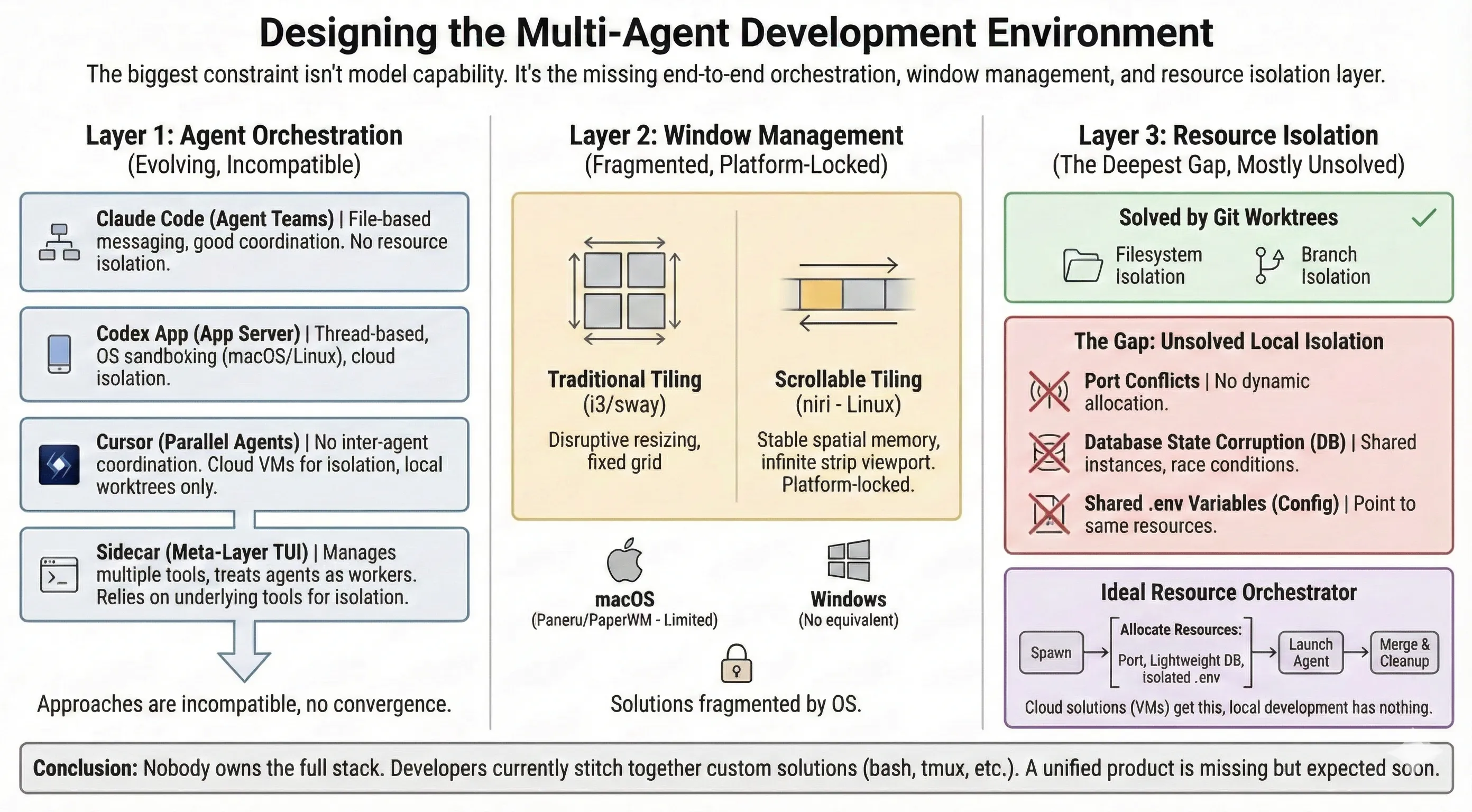
Alex Lavaee, Norin Lavaee Feb 25, 2026 13 min read
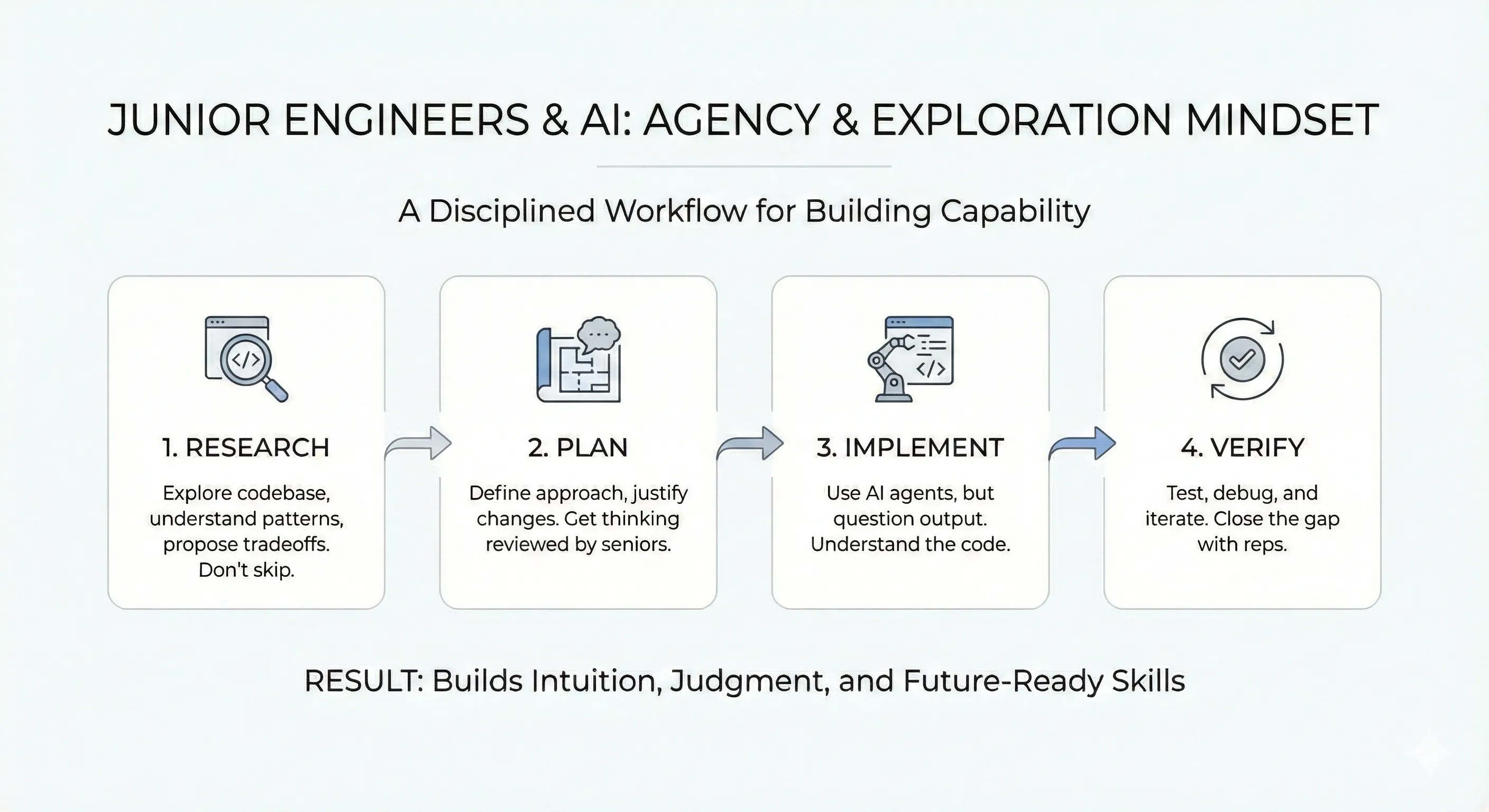
Alex Lavaee, Norin Lavaee Feb 24, 2026 9 min read
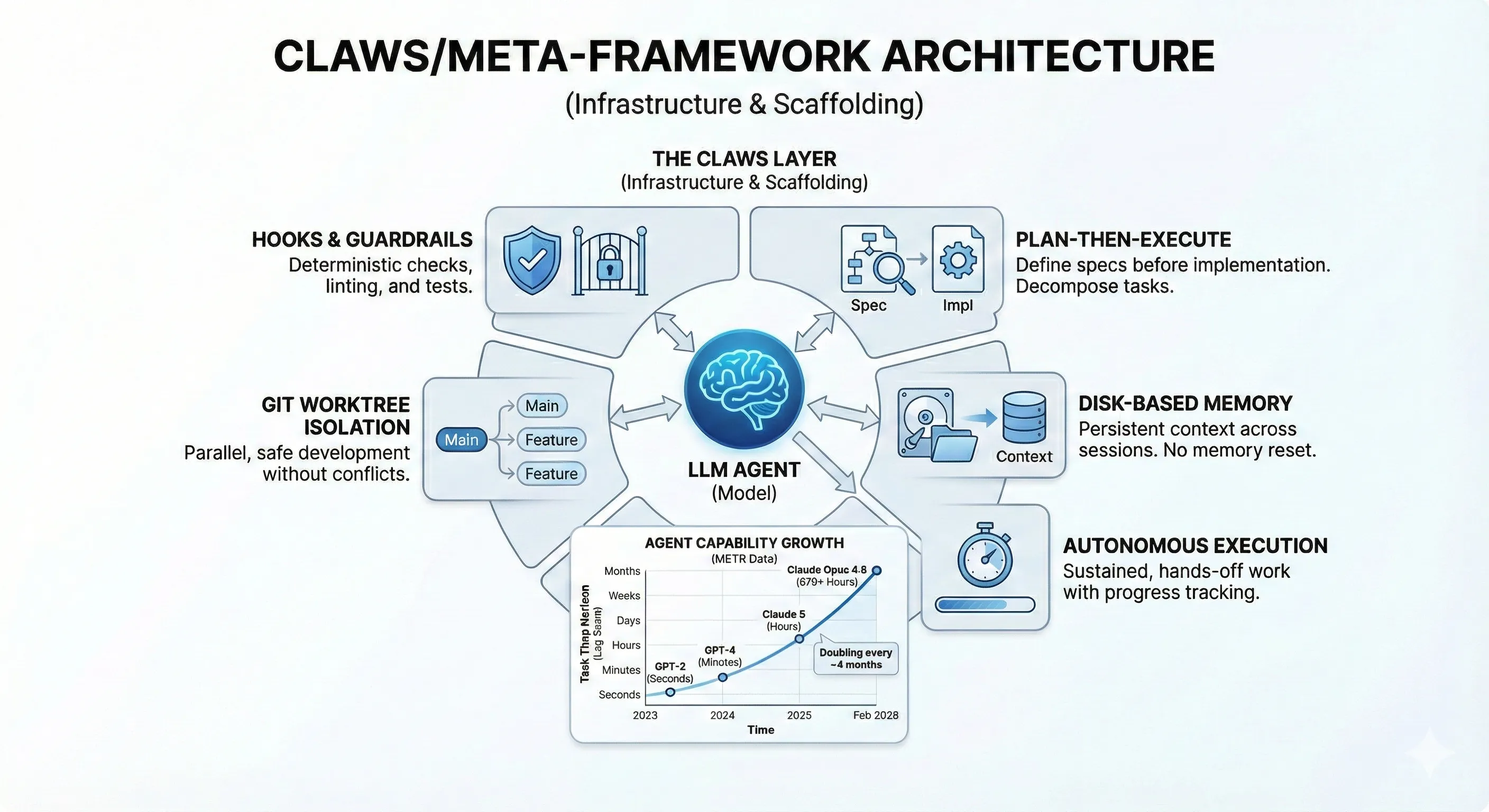
Alex Lavaee, Norin Lavaee Feb 23, 2026 10 min read
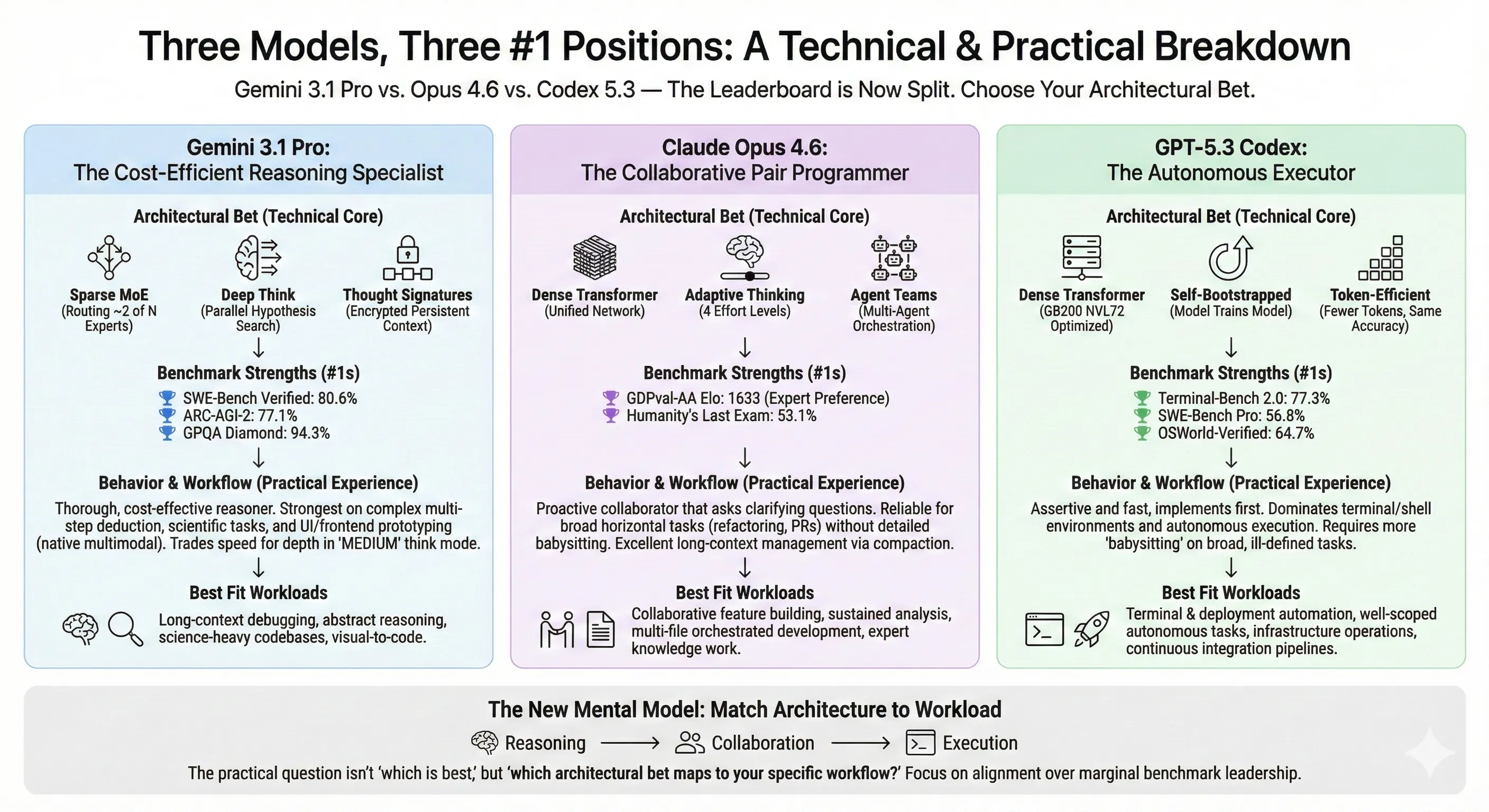
Alex Lavaee, Norin Lavaee Feb 19, 2026 13 min read
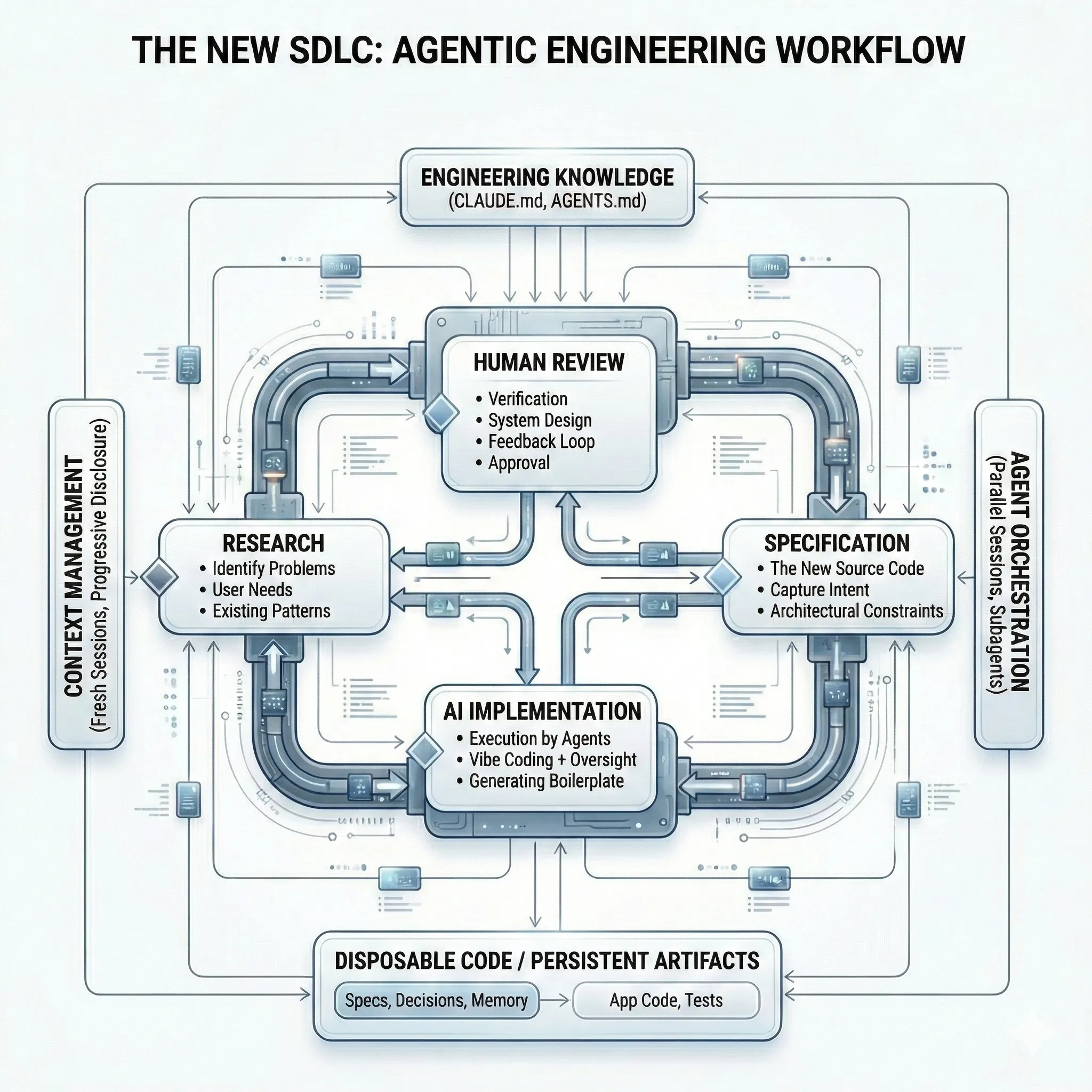
Alex Lavaee, Norin Lavaee Feb 18, 2026 16 min read
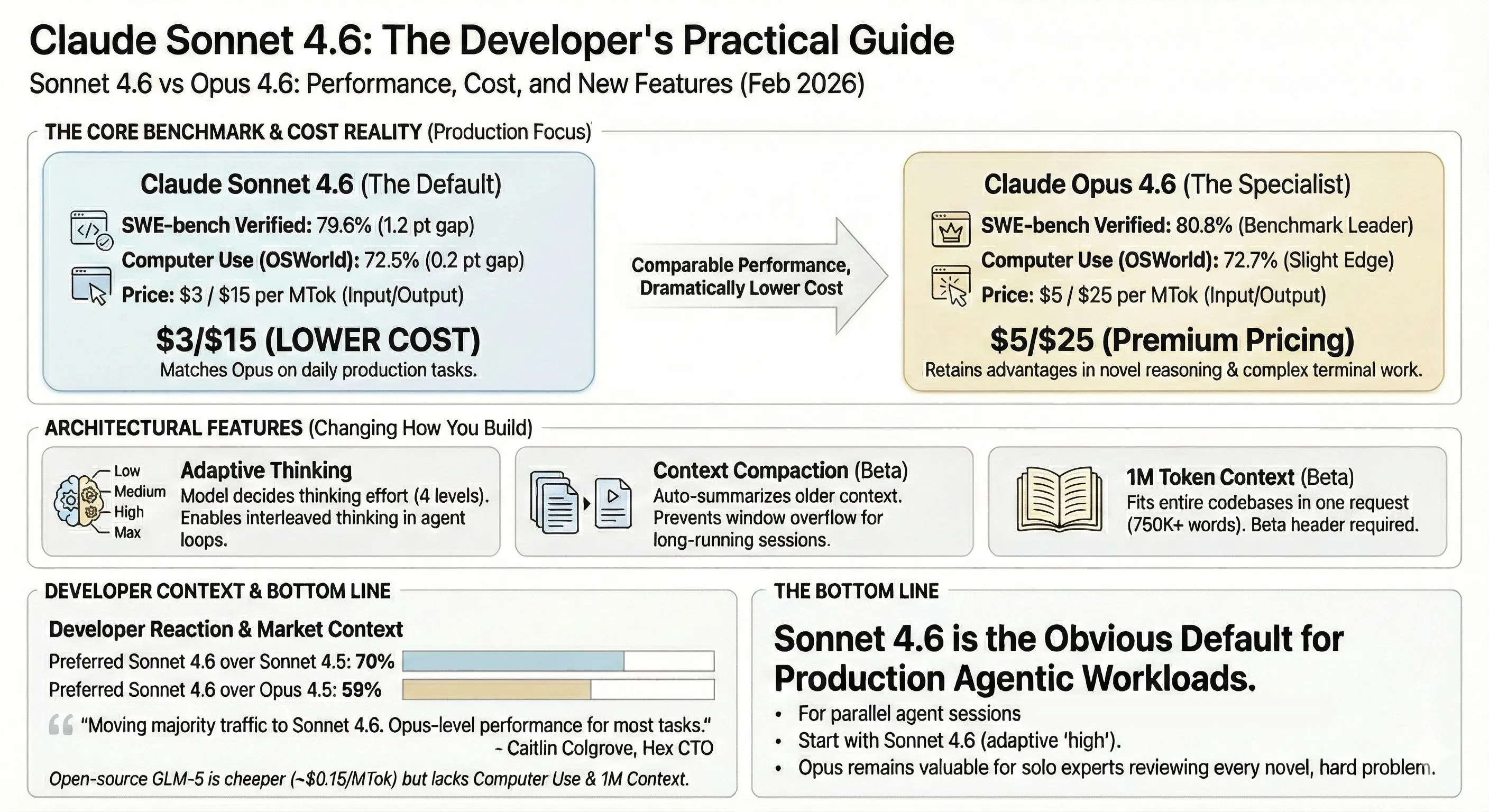
Alex Lavaee, Norin Lavaee Feb 17, 2026 13 min read
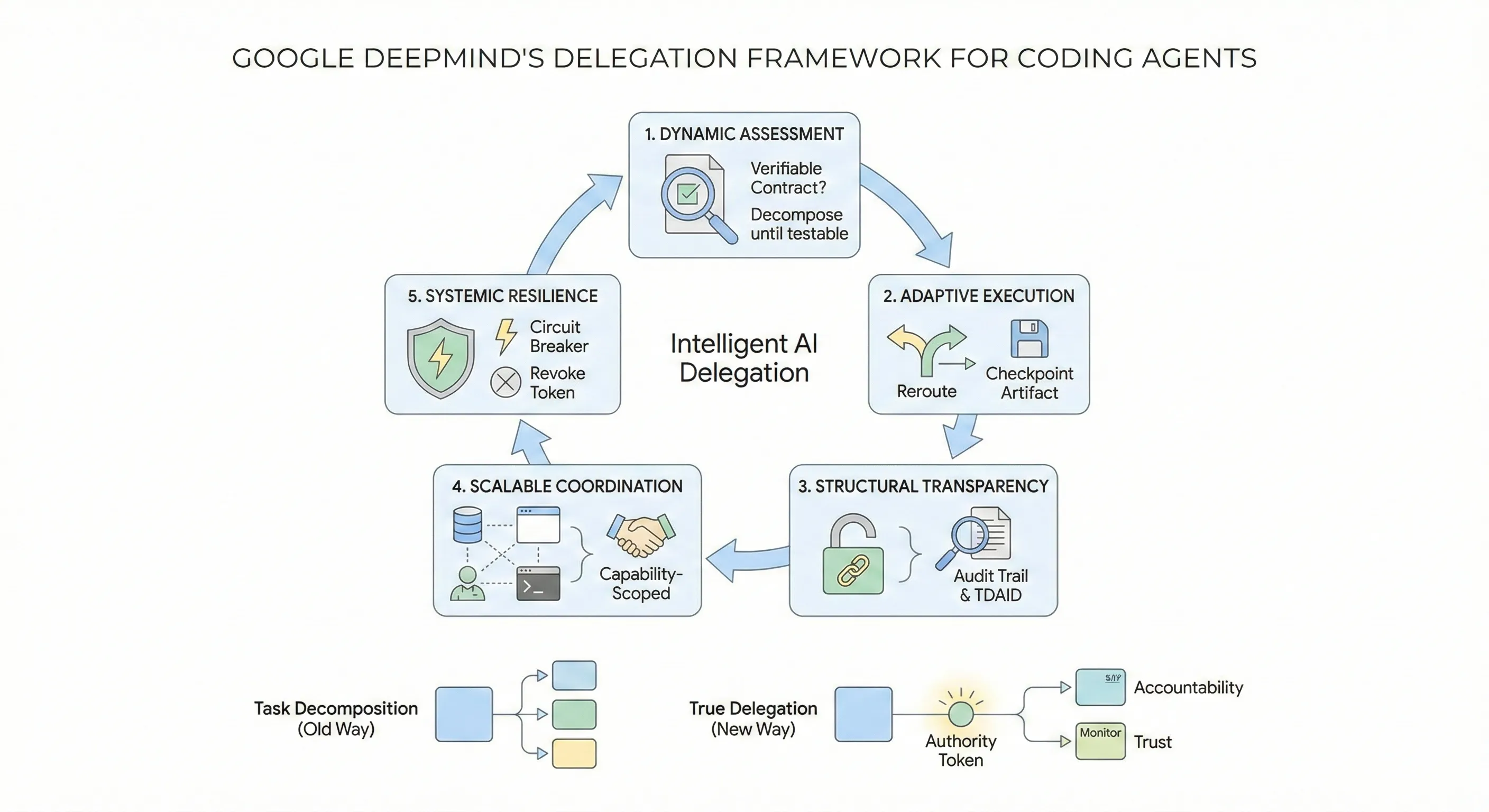
Alex Lavaee, Norin Lavaee Feb 16, 2026 9 min read
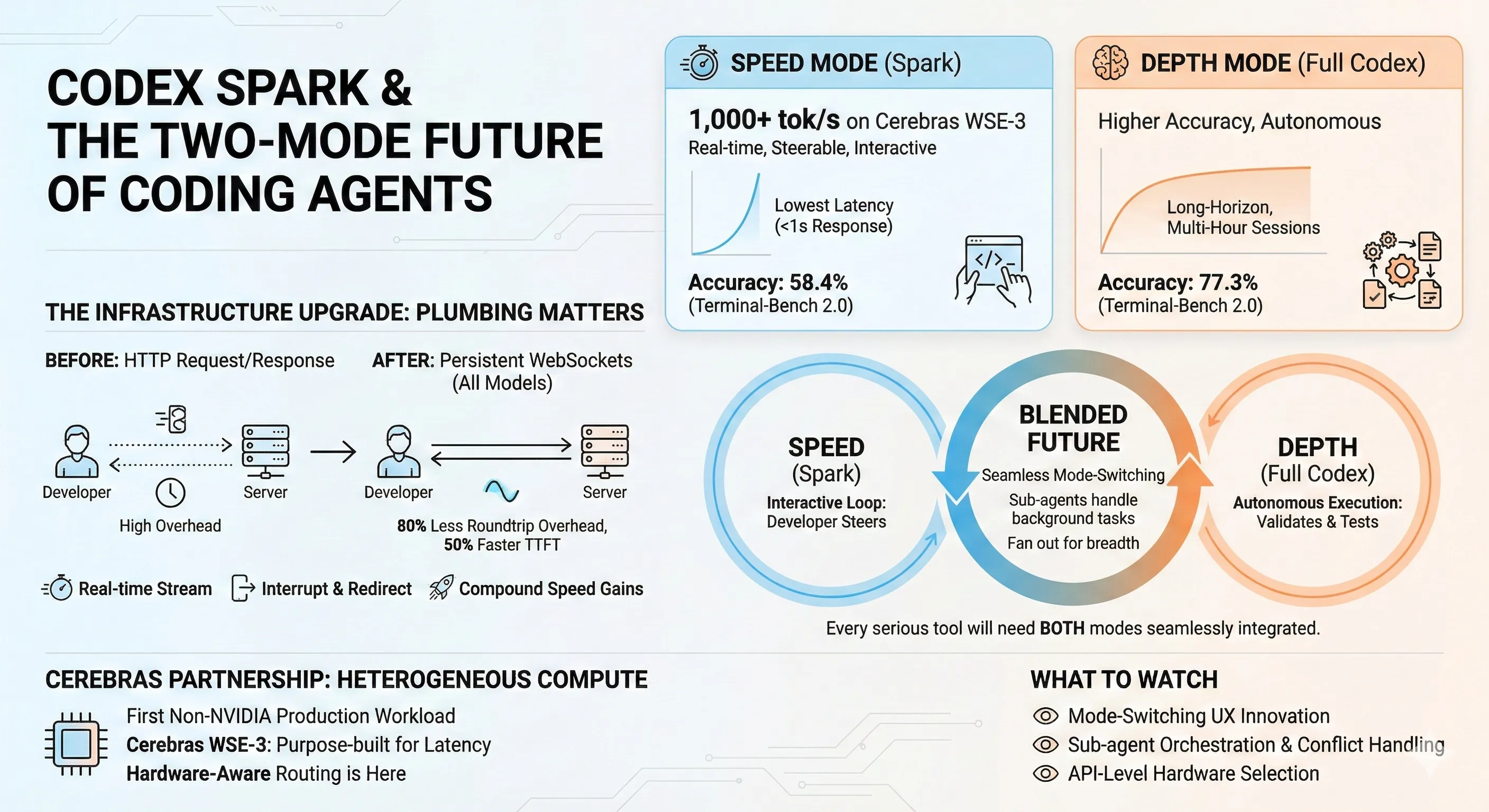
Alex Lavaee, Norin Lavaee Feb 12, 2026 7 min read
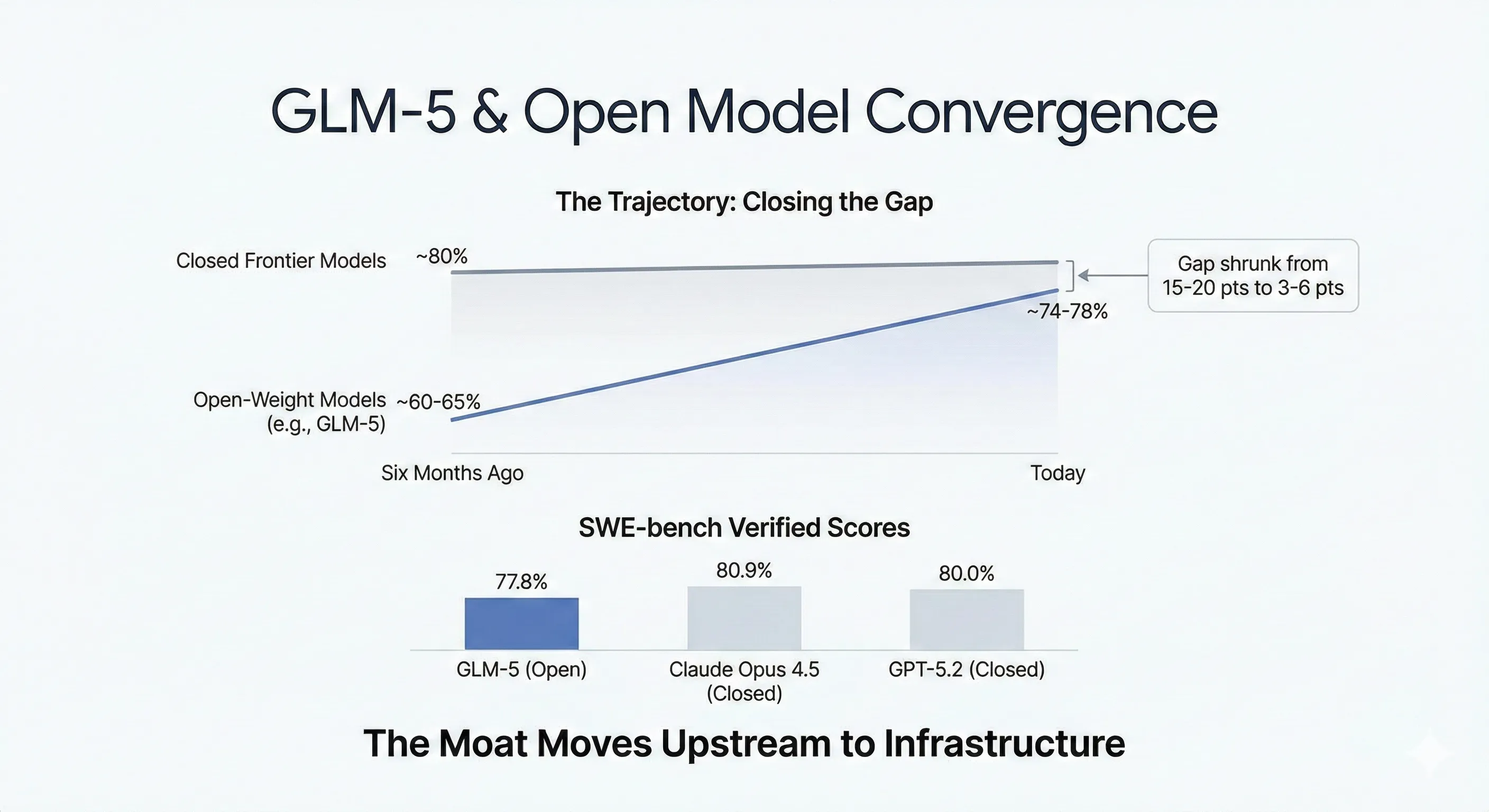
Alex Lavaee, Norin Lavaee Feb 12, 2026 9 min read
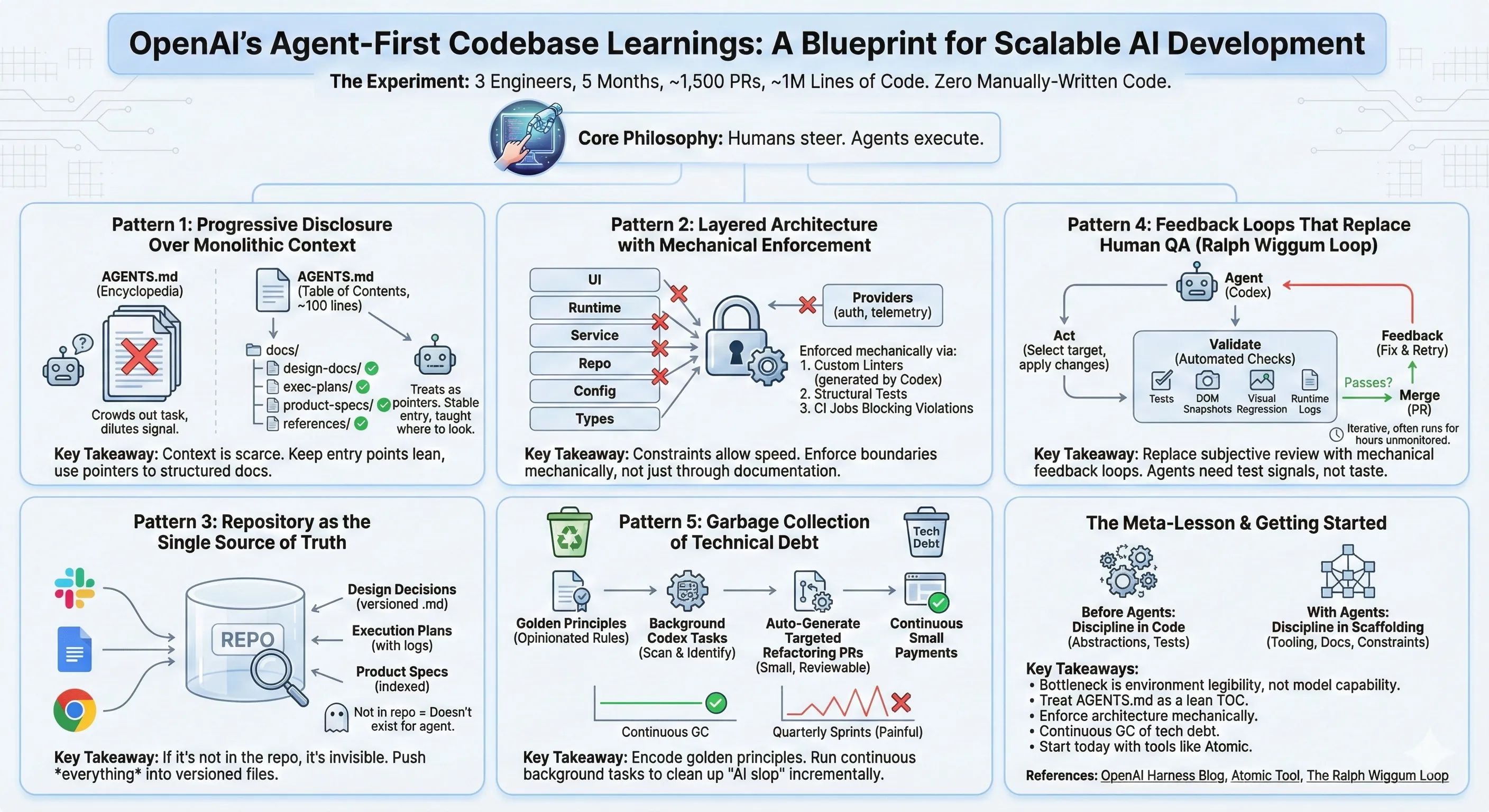
Alex Lavaee, Norin Lavaee Feb 11, 2026 11 min read
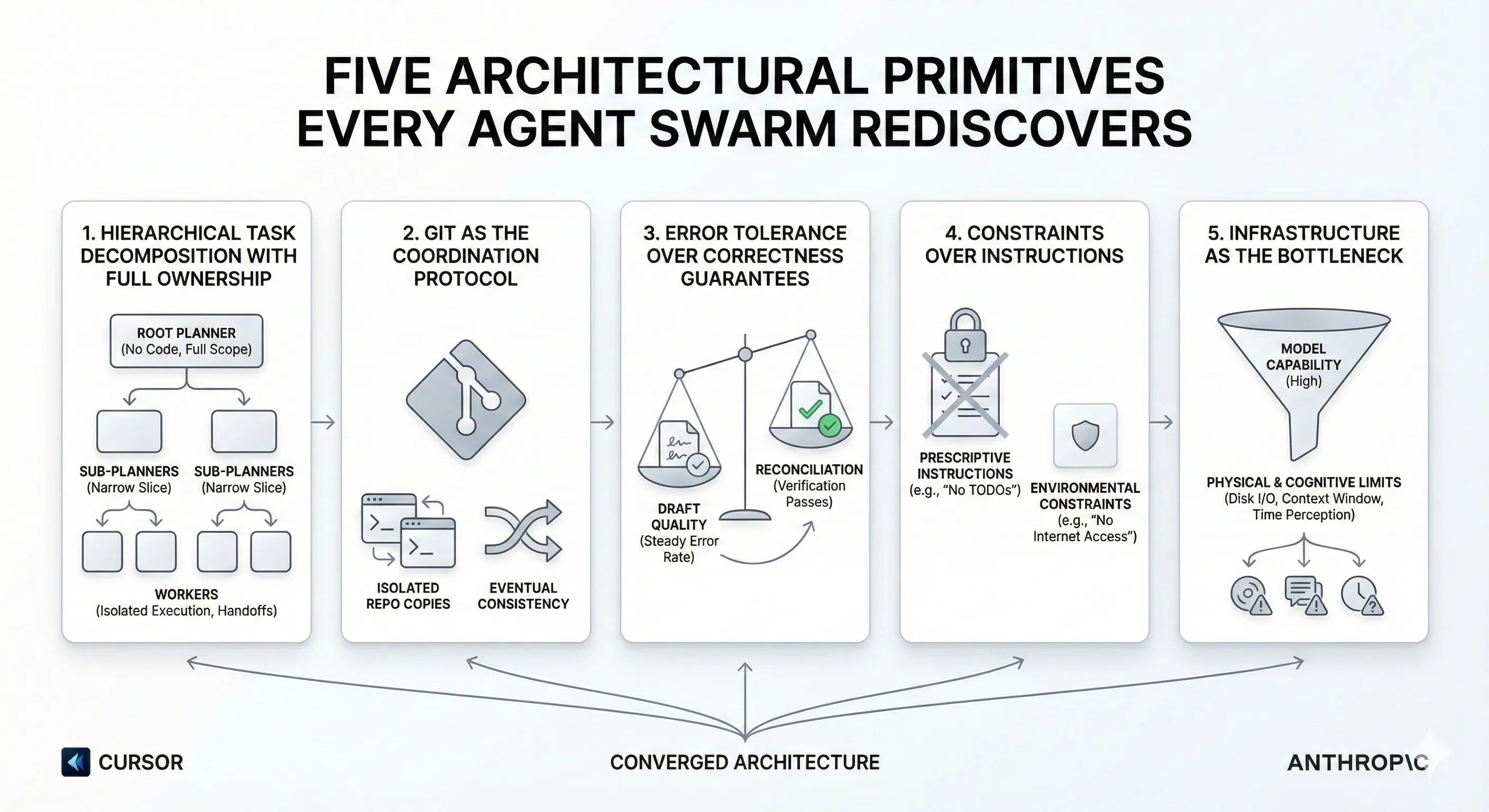
Alex Lavaee, Norin Lavaee Feb 10, 2026 12 min read
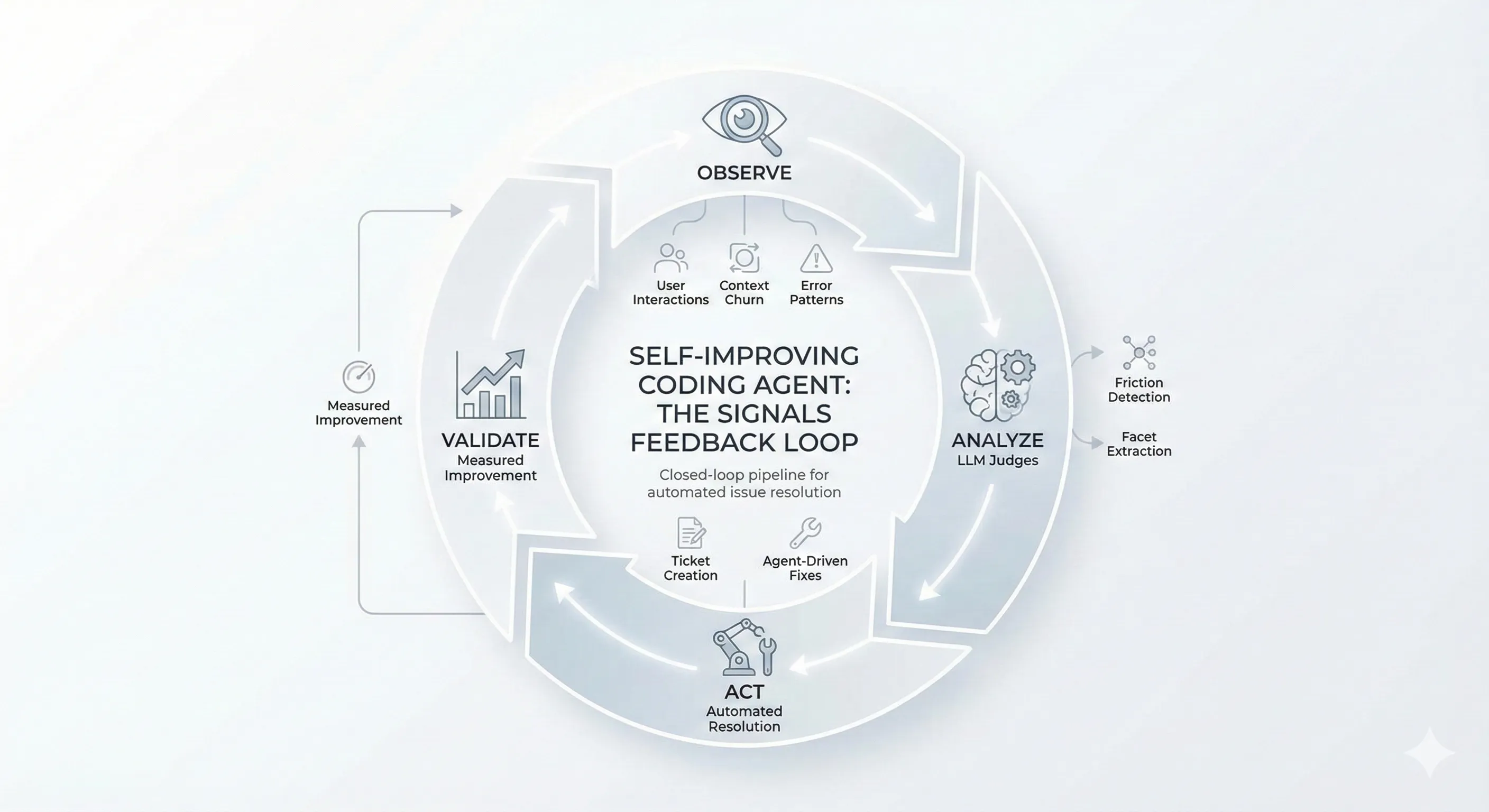
Alex Lavaee Feb 9, 2026 10 min read
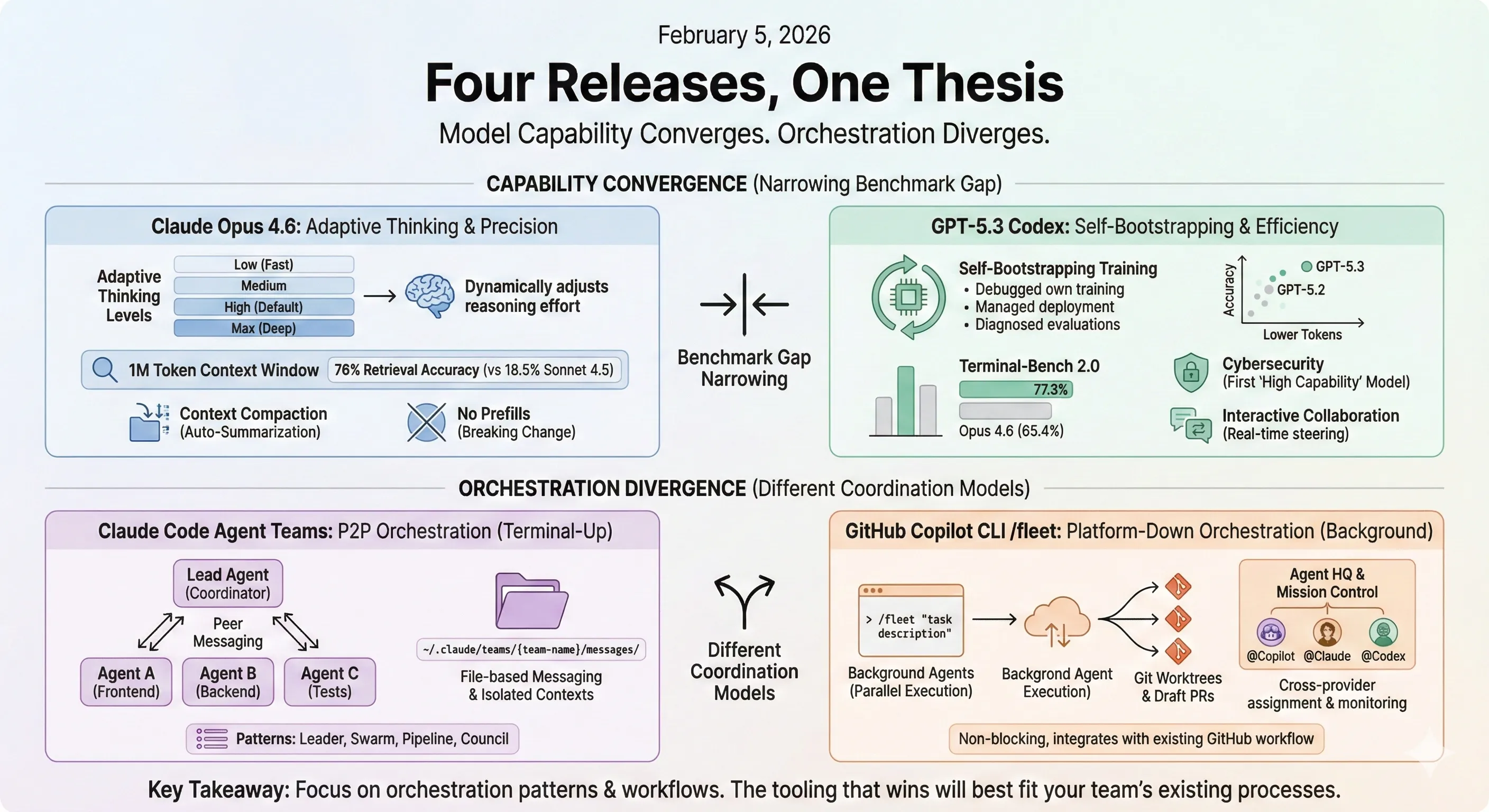
Alex Lavaee, Norin Lavaee Feb 5, 2026 15 min read
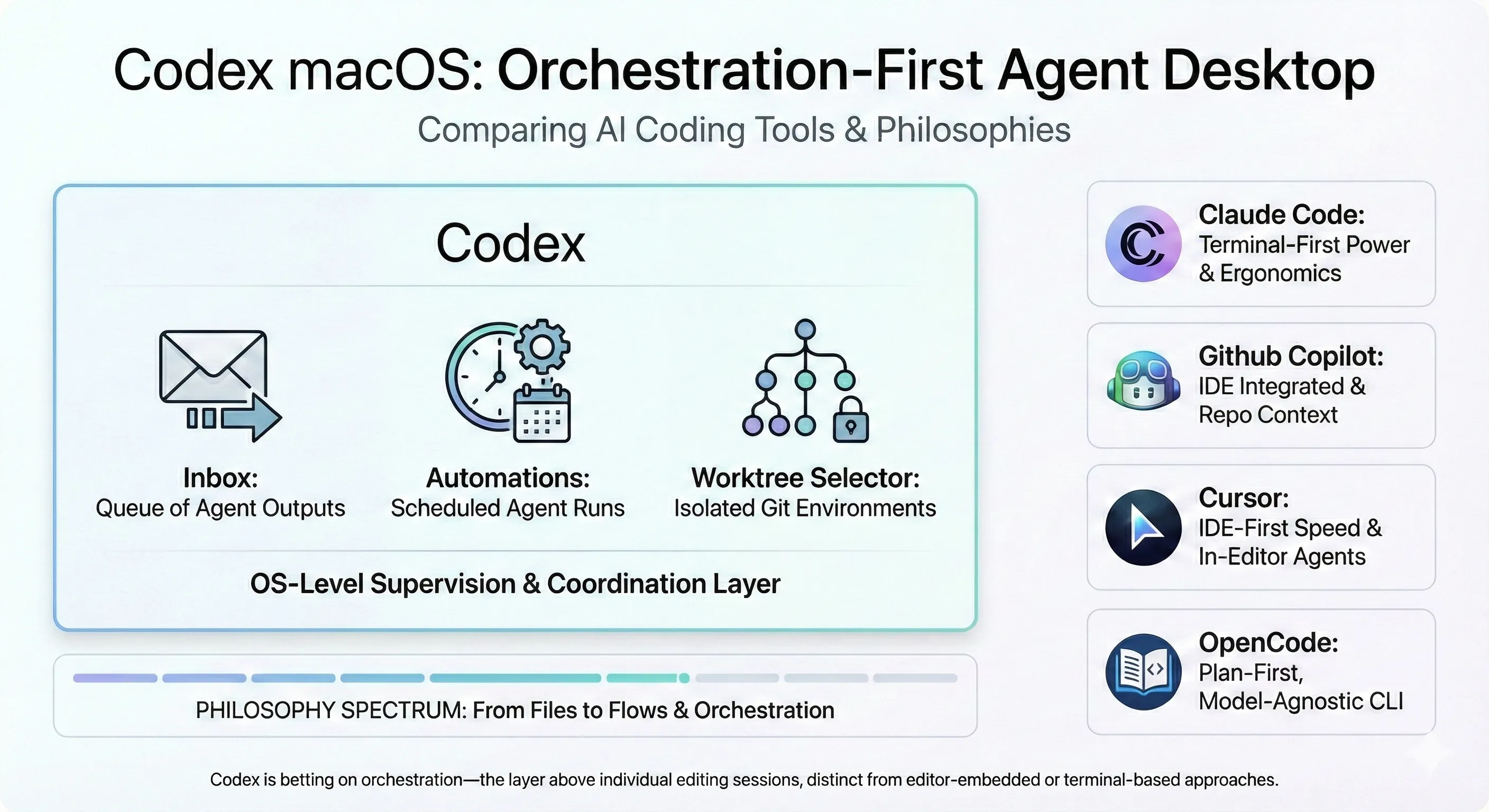
Alex Lavaee Feb 4, 2026 13 min read
Alex Lavaee, Norin Lavaee Feb 3, 2026 10 min read
Alex Lavaee Feb 2, 2026 12 min read
$ cat openai-data-agent-patterns.md
# Building AI Agents That Work at Any Scale
Alex Lavaee Jan 29, 2026 15 min read
$ cat building-reliable-ai-coding-agent-infrastructure.md
# Atomic: Building Reliable AI Coding Agent Infrastructure
Alex Lavaee Jan 28, 2026 18 min read
$ cat atomic-workflow.md
# Atomic: Automated Procedures and Memory for AI Coding Agents
Alex Lavaee, Norin Lavaee Dec 8, 2025 8 min read
$ cat ai-coding-infrastructure.md
# How I Shipped 100k LOC in 2 Weeks with Coding Agents
Alex Lavaee Nov 12, 2025 9 min read
$ cat self-evolving-llm-agents.md
# Continuous Self-Learning in AI Agents
Alex Lavaee, Norin Lavaee Nov 10, 2025 25 min read
$ cat context-engineering-cheat-sheet.md
# Context Engineering Navigator
Alex Lavaee, Norin Lavaee Sep 19, 2025 3 min read
$ cat context-engineering-ai-ides.md
# Building Products with Agentic-Powered IDEs
Alex Lavaee, Norin Lavaee Jul 23, 2025 7 min read
$ cat memorization-generalization-and-reasoning.md
# Memorization, Generalization, and Reasoning
Alex Lavaee, Norin Lavaee Jun 23, 2025 35 min read
mixture-of-experts ~ /connect
$ atomic --help
Atomic is the agent harness we use to build durable coding-agent workflows.
Try it$ cat .mailmap
$ curl -s alexlavaee.me/rss.xml