GLM-5 and the Open Model Convergence
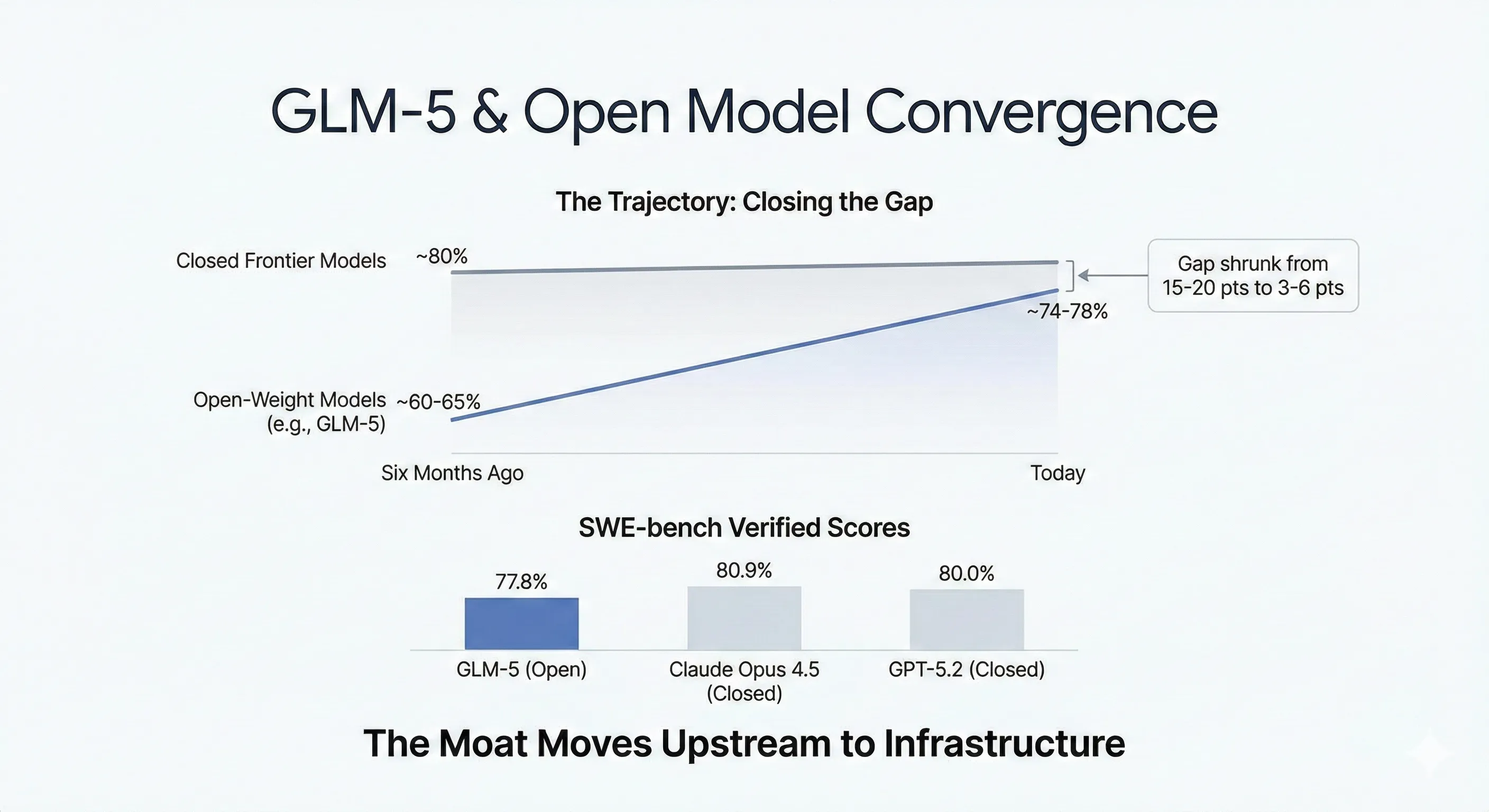
The Trajectory Matters More Than the Scoreboard
GLM-5 launched with numbers that would have been unthinkable for an open model six months ago:
| Benchmark | GLM-5 | Claude Opus 4.5 | GPT-5.2 | DeepSeek V3.2 | Kimi K2.5 |
|---|---|---|---|---|---|
| SWE-bench Verified | 77.8% | 80.9% | 80.0% | 73.1% | 76.8% |
| SWE-bench Multilingual | 73.3% | 77.5% | 72.0% | 70.2% | 73.0% |
| Terminal-Bench 2.0 | 56.2 | 59.3 | 54.0 | 39.3 | 50.8 |
| HLE w/ Tools | 50.4 | 43.4 | 45.5 | 40.8 | 51.8 |
| BrowseComp | 62.0 | 37.0 | — | 51.4 | 60.6 |
But fixating on whether GLM-5 beats a closed model on any single row misses the signal. The signal is the rate of convergence.
Six months ago, the best open model trailed frontier closed models by 15-20 points on coding benchmarks. Today, three open-weight models—GLM-5, Kimi K2.5, and DeepSeek V3.2—cluster within single digits of the frontier. As one HN commenter put it: “The actual gap between frontier and non-frontier models right now is RL infrastructure, not pre-training compute.”
GLM-5 scales to 744B parameters (40B active) with a Mixture of Experts architecture, up from GLM-4.5’s 355B (32B active). It integrates DeepSeek Sparse Attention to cut deployment cost while preserving long-context capacity. The post-training uses a custom asynchronous RL infrastructure called slime that improves training throughput for fine-grained iteration. MIT license. Free weights. Available on HuggingFace.
These are the specs. But specs alone don’t tell you whether to use it. Let’s look at what actually matters for coding agent workflows.
Where GLM-5 Actually Fits in Your Stack
I tested GLM-5 on the $80 coding plan. The behavior profile sits between Opus 4.6 and Codex 5.3—it plans more deliberately than GLM-4.7 but doesn’t go as deep on complex multi-step tasks as Opus 4.6. Inference is noticeably slower than Opus 4.6 fast mode.
Here’s where that trade-off matters and where it doesn’t:
Strong fit: Long-running autonomous sessions
For multi-hour autonomous coding sessions where budget matters more than latency, GLM-5’s economics are compelling. At 6-10x cheaper API costs than Opus 4.6, you can run significantly more agent iterations per dollar. If you’re using patterns like the Ralph Loop—where an agent iterates on a task for hours with sleep intervals between cycles—the cost difference compounds.
# Example: Running GLM-5 in a Ralph-style autonomous loop# At 6-10x cheaper per token, overnight sessions become# economically viable for tasks that were cost-prohibitive before
# Configure OpenCode to use GLM-5 via opencode.json:# { "model": "zai-coding-plan/glm-5" }
opencode --model zai-coding-plan/glm-5 --dir . 2>&1 | \ tee -a .ralph/opencode_output.logWeaker fit: Complex multi-step reasoning under time pressure
For interactive coding sessions where you need fast feedback—debugging a tricky issue, iterating on architecture in real time—the slower inference and slightly lower ceiling on multi-step reasoning make Opus 4.6 or Codex 5.3 a better choice. The cost savings don’t matter when you’re waiting on each response.
The evaluation framework
Rather than asking “is GLM-5 better than X?”, the useful question is: what’s the cost-adjusted quality for my specific workload?
The Real Shift: Model Convergence Moves the Moat
This is the part that matters most for how you build.
When the capability gap between models was 15-20 points, model selection was arguably the most important decision in your coding agent stack. Pick the wrong model and you’re working with a fundamentally less capable agent.
When the gap is 3-6 points, model selection becomes a commodity decision—important, but no longer the differentiator. The moat moves upstream to the infrastructure around the model.
The teams winning with coding agents aren’t winning because they picked the best model. They built better scaffolding. Specifically:
1. Orchestration quality — How well does your system decompose complex tasks, coordinate parallel agents, and recover from failures? A well-orchestrated system with GLM-5 will outperform a raw Opus 4.6 prompt for any non-trivial multi-step task.
2. Tool integration — Can your agent inspect DOM state, query logs, run tests, and loop on results? The Harness team’s Chrome DevTools Protocol integration turned Codex into a self-validating system. Model capability was necessary but not sufficient—the tooling made it work.
3. Context management — Progressive disclosure, persistent memory across sessions, research-to-spec pipelines. These patterns are model-agnostic and multiply the effectiveness of any model you plug in.
4. Ecosystem depth — Skills, sub-agents, feedback loops, mechanical enforcement of architectural constraints. This is the compound interest of coding agent infrastructure—each rule, each skill, each feedback loop makes every future agent run more reliable.
Practical Guide: Evaluating GLM-5 for Your Workflow
If you want to test GLM-5 against your current model, here’s how to do it systematically rather than vibes-based.
Step 1: Define your workload profile
Categorize your typical agent tasks:
// Map your tasks to evaluation categoriesconst workloadProfile = { interactive: { // Debugging, architecture discussion, code review latencySensitive: true, typicalDuration: "5-30 min", budgetWeight: "low", // fewer tokens per session }, batch: { // Feature implementation, test generation, refactoring latencySensitive: false, typicalDuration: "1-4 hours", budgetWeight: "high", // bulk of token spend }, autonomous: { // Ralph-style overnight loops, migration tasks latencySensitive: false, typicalDuration: "4-12 hours", budgetWeight: "highest", // most tokens consumed },};Step 2: Run a head-to-head on representative tasks
Pick 5-10 real tasks from your recent history. Run each through both your current model and GLM-5. Track:
- Completion rate — Did it finish the task without human intervention?
- Quality — Does the output pass your tests and review criteria?
- Cost — Total tokens consumed x price per token
- Latency — Time to first useful output (matters for interactive, less for batch)
Step 3: Calculate cost-adjusted quality
Score = (completion_rate × quality_score) / cost_per_taskIf GLM-5’s cost-adjusted quality exceeds your current model for batch and autonomous workloads, route those workloads to GLM-5 and keep your premium model for interactive sessions.
Step 4: Set up model routing
The simplest version: use model selection based on task type in your agent configuration.
// Example: Model routing in your agent config{ "models": { "interactive": "claude-opus-4-6", "batch": "glm-5", "autonomous": "glm-5" }}More sophisticated setups can route dynamically based on task complexity, but start simple. The 80/20 is: cheap model for long-running batch work, premium model for interactive sessions.
What to Watch Next
Open-closed model convergence is the most underpriced trend in AI right now. Here’s what to monitor:
- RL infrastructure improvements — GLM-5’s “slime” async RL system and similar innovations are closing the post-training gap. Watch for open-source RL tooling that lets smaller teams replicate frontier-level post-training
- Tool-use benchmarks — HLE with tools, MCP-Atlas, and BrowseComp are better proxies for real-world agent capability than pure reasoning benchmarks. GLM-5 beat Opus 4.5 and GPT-5.2 on HLE with tools—that signal matters
- Deployment cost trajectory — GLM-5 integrates DeepSeek Sparse Attention to reduce serving cost. As inference optimization improves for open models, the cost advantage over closed APIs will widen
- Ecosystem adoption — OpenCode already supports GLM-5. Broader tool compatibility means lower switching costs
The model race isn’t over. But when the gap narrows to single digits, the question stops being “which model writes better code?” and starts being “which team built better infrastructure around the model?”
The answer to the second question is entirely in your control. For a detailed technical comparison of how the leading closed models differentiate on architecture, benchmarks, and developer experience, see our breakdown of Gemini 3.1 Pro, Opus 4.6, and Codex 5.3.
Getting Started with GLM-5
Chat: Try it free at Z.ai (select GLM-5 from the model dropdown)
API: Available at api.z.ai — compatible with standard OpenAI-style API calls
Coding agents: Update your model config:
// opencode.json (for OpenCode){ "$schema": "https://opencode.ai/config.json", "model": "zai-coding-plan/glm-5"}Local deployment: Weights available on HuggingFace and ModelScope. Supports vLLM and SGLang for inference. See the GitHub repo for deployment instructions.
Coding Plan: Starts at $80/month. Max plan users can enable GLM-5 now. Other tiers rolling out progressively. GLM-5 requests consume more quota than GLM-4.7.
Key Takeaways
- GLM-5 scores 77.8% on SWE-bench Verified (within 3 points of Claude Opus 4.5) with MIT-licensed weights—the open-closed gap on coding benchmarks has collapsed from 15-20 points to single digits in six months
- First open-weights model to cross 50 on the Artificial Analysis Intelligence Index, joining Kimi K2.5 and DeepSeek V3.2 in a cluster converging on frontier performance
- At 6-10x cheaper API costs than Opus 4.6, model economics are shifting the optimization target from “pick the best model” to “build better scaffolding”
- When models converge on capability, the moat moves to orchestration, tool integration, context management, and ecosystem depth
- Practical guidance: how to evaluate GLM-5 for your coding agent workflows and where it fits versus closed alternatives
References
- GLM-5 Release — Zhipu AI official announcement and model access
- GLM-5 on HuggingFace — MIT-licensed model weights
- GLM-5 GitHub — Deployment instructions and documentation
- SWE-bench — Software engineering benchmark used for coding evaluation
- Atomic: Ship complex features with AI agents — Open-source tool for research-to-execution agent workflows
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.