Gemini 3.1 Pro, Opus 4.6, and Codex 5.3: A Technical Breakdown of Three Models, Three #1 Positions
Key Takeaways
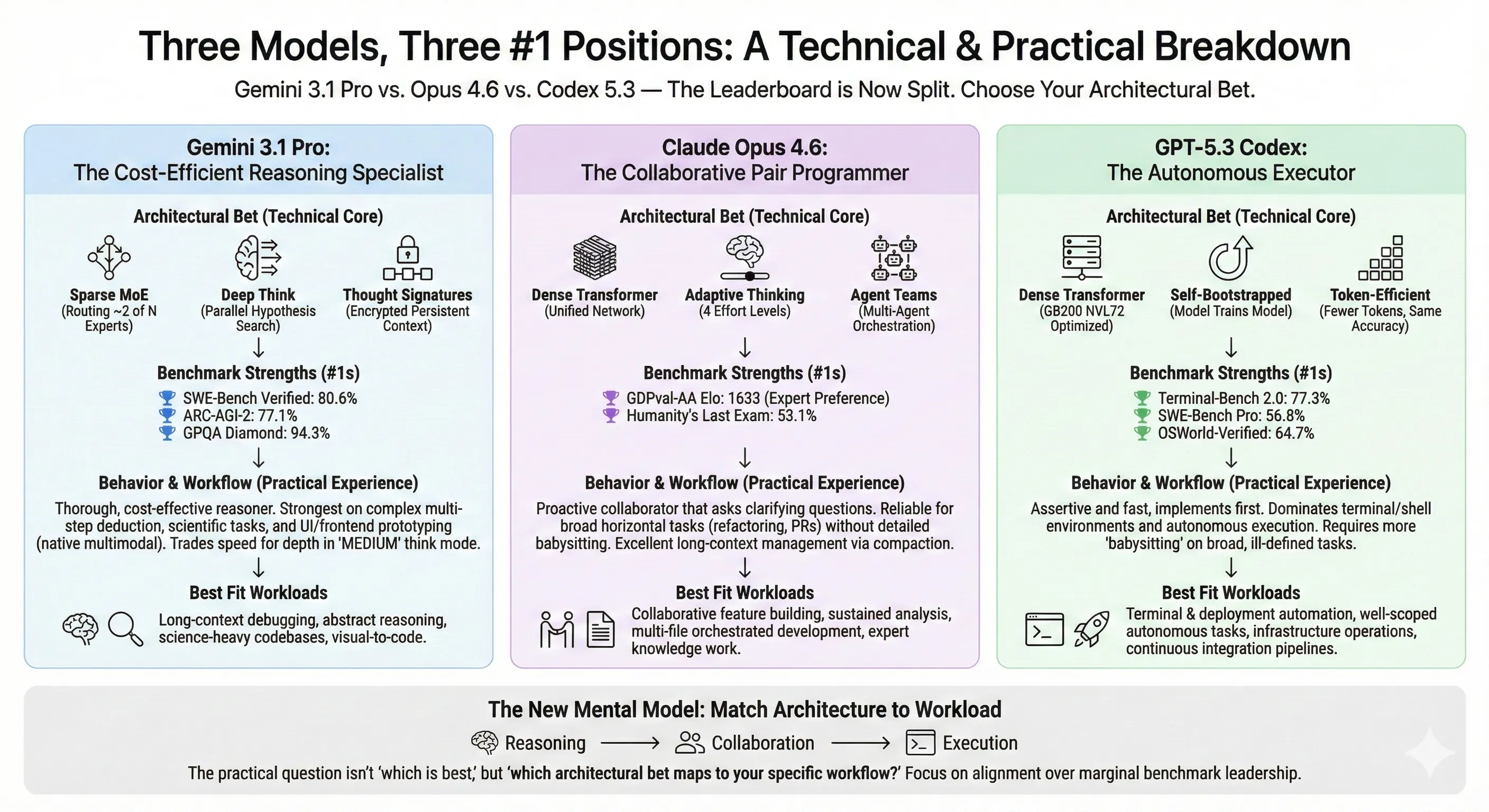
- Gemini 3.1 Pro hits 80.6% on SWE-Bench Verified (first model above 80%) by combining sparse MoE routing with Deep Think inference-time reasoning and Thought Signatures for multi-step context persistence.
- Claude Opus 4.6 leads real-world developer preference (GDPval-AA Elo 1633) through adaptive thinking effort levels and Agent Teams orchestration—a behavioral difference that shows up as collaborative coding rather than autonomous execution.
- GPT-5.3 Codex dominates terminal work (Terminal-Bench 77.3%) through self-bootstrapped training and token-efficient patching, but developers report it needs more babysitting on broad tasks.
- The benchmark leaderboard is now split three ways. The practical question isn’t which model is best—it’s which architectural bets matter for your workflow.
The Architecture Divergence
These three models don’t just score differently. They’re built on fundamentally different technical bets. Understanding the architecture explains why each model excels where it does.
Gemini 3.1 Pro: Sparse MoE + Deep Think + Thought Signatures
Gemini 3.1 Pro’s architecture rests on three mutually reinforcing innovations. Each addresses a different bottleneck in agentic coding.
Sparse Mixture of Experts
Gemini’s transformer backbone uses Mixture of Experts (MoE) layers. Instead of activating the entire network for every token, a gating router selects a small subset of expert sub-networks (e.g., 2 out of 16) per token. The rest stay idle.
This is how Gemini can have an enormous total parameter count while keeping per-token inference cost low. At $2/$12 per million tokens, 3.1 Pro is roughly 2.5x cheaper on input and 2x cheaper on output than Opus 4.6 ($5/$25). The MoE architecture is the enabling factor—you get frontier capability at a fraction of the compute cost because most of the network doesn’t fire per token.
Deep Think: Inference-Time Compute Scaling
Deep Think is Gemini’s reasoning mode. Rather than generating a single chain-of-thought, it explores multiple hypotheses in parallel and uses an internal verifier (codenamed Aletheia) to catch logical errors mid-chain.
Aletheia follows a Generator-Verifier-Reviser (GVR) loop:
- Generator produces a candidate solution
- Verifier checks the solution using natural language reasoning, flagging flaws or hallucinations
- Reviser patches the solution or restarts from scratch if fundamentally flawed
This separation of generation from verification is critical. Google’s researchers found that explicitly separating verification helps the model recognize errors it overlooks during generation. In practice, this means Deep Think doesn’t just “think longer”—it debates with itself and discards bad reasoning paths.
Gemini 3.1 Pro introduces a new MEDIUM thinking budget level alongside LOW and HIGH, giving developers a cost/speed/accuracy dial:
from google import genai
client = genai.Client()
# Use MEDIUM thinking for balanced cost/accuracyresponse = client.models.generate_content( model="gemini-3.1-pro", contents="Analyze this codebase for race conditions in the connection pool", config={ "thinking_config": {"thinking_budget": "MEDIUM"}, },)On Deep Think’s highest setting, Gemini 3 achieved 84.6% on ARC-AGI-2 and 95.1% accuracy on IMO-Proof Bench Advanced—with 100x less compute than its July 2025 version. That compute efficiency gain is the real story: inference-time reasoning is becoming cheaper fast.
Thought Signatures: Persistent Reasoning Across Turns
Thought Signatures solve a specific problem in multi-step agentic tasks: context drift. When a model performs a multi-turn function-calling workflow (e.g., “check the flight status, and if delayed, book a taxi”), the reasoning context from step 1 can degrade by step 3.
Thought Signatures are encrypted representations of the model’s internal reasoning state, returned alongside each response. You pass them back verbatim in the next turn:
import google.genai as genai
client = genai.Client()
# Step 1: Initial reasoning produces a thought signatureresponse = client.models.generate_content( model="gemini-3.1-pro", contents="Check flight status for AA100 and book a taxi if delayed.", config={"thinking_config": {"thinking_budget": "MEDIUM"}},)
# The response includes function_call with a thought_signature# Step 2: Pass the signature back to preserve reasoning context# When sending the function result back, include the thought_signature# from the previous response EXACTLY as received
# For Gemini 3 models, omitting the thought_signature on function# calls returns a 400 validation errorFor Gemini 3 models, passing back thought signatures during function calling is mandatory—omitting them returns a 400 validation error. This isn’t optional ergonomics; it’s a hard contract that reasoning state must persist across tool calls. The practical effect: multi-step agents don’t lose their train of thought between actions.
Claude Opus 4.6: Adaptive Thinking + Agent Teams
Opus 4.6 takes a different architectural bet. Rather than sparse routing at the model level, Anthropic focused on dynamic reasoning allocation and multi-agent coordination.
Adaptive Thinking
Previously, extended thinking was binary—on or off with a fixed token budget. Opus 4.6 replaces this with adaptive thinking that dynamically decides when deeper reasoning helps. Four effort levels control the behavior:
import anthropic
client = anthropic.Anthropic()
# Adaptive thinking: model decides reasoning depthresponse = client.messages.create( model="claude-opus-4-6-20260205", max_tokens=16000, thinking={ "type": "enabled", "budget_tokens": 10000, }, messages=[{"role": "user", "content": "..."}],)
# Or use effort-based controlresponse = client.messages.create( model="claude-opus-4-6-20260205", max_tokens=16000, thinking={"type": "adaptive"}, # Auto-selects effort level messages=[{"role": "user", "content": "..."}],)At high (the default), Claude almost always engages deep reasoning. At low, it skips thinking for simple queries. This directly reduces latency and cost on straightforward tasks while preserving depth when needed.
Agent Teams: Multi-Agent Orchestration
The most architecturally significant Opus 4.6 feature isn’t in the model itself—it’s the Agent Teams system in Claude Code. A lead agent spawns specialist agents (each with its own context window), assigns subtasks, and synthesizes results with peer-to-peer communication:
# Agent teams spawn through multiple backends# Example: tmux-based multi-agent sessionCLAUDE_CODE_TEAM_NAME="refactor-auth"CLAUDE_CODE_AGENT_ID="agent-001"CLAUDE_CODE_AGENT_TYPE="backend"
# Lead agent coordinates via file-based messaging:# ~/.claude/teams/{team-name}/messages/{session-id}/In a demonstration, an agent team generated 100,000 lines of working C compiler code that boots Linux on x86, ARM, and RISC-V—in roughly 8 hours. The practical pattern: one agent writes tests, another handles implementation, a third reviews security, all simultaneously.
Context Compaction
For long-running agentic sessions, Opus 4.6 introduces server-side context compaction. When context approaches the window limit, the API automatically summarizes older exchanges while preserving critical information. This enables sessions that run for hours without manual context management—a significant advantage for the collaborative coding workflow Claude is optimized for.
GPT-5.3 Codex: Self-Bootstrapping + Token Efficiency
Codex 5.3’s technical story centers on two innovations: the model participated in its own development, and it achieves frontier results with fewer tokens.
Self-Bootstrapping Development
OpenAI describes GPT-5.3 Codex as “the first model that was instrumental in creating itself.” Early versions were used to debug training runs, manage deployment infrastructure, and diagnose evaluation results. This isn’t recursive self-improvement in the sci-fi sense—it’s a model accelerating the development feedback loop by handling infrastructure work that previously bottlenecked human researchers.
The model was co-designed for and served on NVIDIA GB200 NVL72 systems, achieving its 25% inference speed improvement through combined model and hardware optimization.
Token-Efficient Patching
GPT-5.3 Codex achieves its SWE-Bench Pro results with fewer output tokens than any prior model. This is a direct cost improvement: better accuracy per token means lower cost per patch. The model also fixed three specific failure patterns from its predecessor:
- Non-deterministic linting loops (model would endlessly retry failed lints)
- Insufficient bug-analysis evidence (premature fix attempts without diagnosis)
- Premature completion in flaky-test scenarios (declaring success on intermittent passes)
Head-to-Head Benchmarks
Here’s where the three-way split becomes concrete:
| Benchmark | Gemini 3.1 Pro | Opus 4.6 | Codex 5.3 | What It Measures |
|---|---|---|---|---|
| SWE-Bench Verified | 80.6% | 80.8% | — | Agentic software engineering |
| SWE-Bench Pro | 54.2% | — | 56.8% | Multi-language SE |
| Terminal-Bench 2.0 | 68.5% | 65.4% | 77.3% | Terminal/shell execution |
| ARC-AGI-2 | 77.1% | 68.8% | — | Abstract reasoning |
| GPQA Diamond | 94.3% | 91.3% | — | Scientific knowledge |
| APEX-Agents | 33.5% | 29.8% | — | Long-horizon agentic tasks |
| GDPval-AA Elo | 1317 | 1633 | — | Expert-level knowledge work |
| Humanity’s Last Exam (tools) | 51.4% | 53.1% | — | Multidisciplinary reasoning |
| OSWorld-Verified | — | — | 64.7% | Computer use tasks |
Bold = category leader. The pattern is clear: Google leads reasoning and scientific benchmarks, OpenAI leads terminal execution, Anthropic leads real-world expert preference.
How They Actually Behave Differently
Benchmarks measure capability. Behavior determines whether engineers prefer a model. Based on reports from Interconnects, DataCamp, and practitioner testing, there are clear behavioral differences.
Opus 4.6: The Collaborative Pair Programmer
Claude tends to ask clarifying questions before acting. It will surface assumptions, propose alternatives, and seek confirmation on ambiguous requirements. This is intentional—Opus is optimized for sessions where the developer is actively steering.
Developers report trusting Claude to “understand the context of a fix and generally get it right” on broad horizontal tasks like git operations, data analysis, PR management, and refactoring. It handles multiple-instruction queues without detailed babysitting.
Codex 5.3: The Autonomous Executor
Codex tends to implement first and ask questions later. It’s more assertive, faster to produce output, and optimized for well-scoped, clear problems. The tradeoff: it “can skip files, put stuff in weird places” on broad tasks and requires “babysitting in terms of more detailed descriptions when doing somewhat mundane tasks,” as the Interconnects review noted.
Where Codex excels is terminal work—shell environments, deployment pipelines, and infrastructure automation. The 77.3% Terminal-Bench score reflects a model fine-tuned for autonomous execution in constrained environments.
Gemini 3.1 Pro: The Reasoning Specialist
Gemini 3.1 Pro’s Deep Think mode trades speed for thoroughness. It is strongest on tasks that require multi-step logical deduction: debugging complex race conditions, analyzing mathematical proofs, or handling science-heavy codebases. The MEDIUM thinking level introduces a practical middle ground—less latency than full Deep Think, more thorough than standard inference.
Developers on community forums note Gemini’s particular strength in frontend and UI work—turning Figma-like mockups into code, implementing hover states, and aligning layouts based on visual specs. The native multimodal architecture gives it an edge when the problem involves visual reasoning alongside code generation.
The Right Mental Model for February 2026
The leaderboard is now genuinely split three ways. Rather than asking “which model is best,” the productive question is which architectural bet maps to your workload:
| Workload | Best Fit | Why |
|---|---|---|
| Long-context refactoring | Gemini 3.1 Pro | MoE keeps cost low on large contexts; Thought Signatures maintain reasoning across steps |
| Collaborative feature building | Opus 4.6 | Adaptive thinking + Agent Teams for multi-file orchestrated development |
| Terminal/deployment automation | Codex 5.3 | 77.3% Terminal-Bench; optimized for autonomous shell execution |
| Abstract reasoning / debugging | Gemini 3.1 Pro | 77.1% ARC-AGI-2; Deep Think explores multiple hypotheses |
| Expert knowledge work | Opus 4.6 | GDPval-AA Elo 1633; best at sustained, nuanced analysis |
| Prototyping from visual specs | Gemini 3.1 Pro | Native multimodal architecture; strong on frontend/UI |
Some developers are settling into multi-model workflows—Claude for architecture and complex implementation, Gemini for prototyping and long-context work, Codex for deployment and long-running autonomous tasks. Others prefer sticking with one model because behavioral consistency matters more than marginal benchmark advantages.
What Engineers Are Saying
Real-world feedback from vetted sources paints a more nuanced picture than benchmarks alone.
On Gemini 3.1 Pro, Vladislav Tankov (Director of AI at JetBrains) reported a “15% quality improvement over previous versions,” noting the model is “stronger, faster… and more efficient, requiring fewer output tokens.” Hanlin Tang (CTO of Databricks) stated it achieved “best-in-class results” on OfficeQA, a benchmark for grounded reasoning across tabular and unstructured data. Andrew Carr (Co-founder at Cartwheel) highlighted “substantially improved understanding of 3D transformations,” noting it resolved long-standing rotation order bugs in 3D animation pipelines.
On Opus 4.6, Codecademy’s review emphasized the long-context retrieval jump from 18.5% to 76% as the standout practical improvement. Boris Cherny (Claude Code developer at Anthropic) summarized it as “more agentic, more intelligent, runs for longer, and is more careful and exhaustive.” The Interconnects review found Opus handles broad horizontal tasks reliably without requiring detailed instructions—a significant UX advantage for day-to-day engineering work.
On Codex 5.3, the same Interconnects review noted that while Codex has “the best top-end ability in software understanding,” switching from Opus to Codex “feels like needing to babysit the model.” DataCamp’s analysis highlighted the real-time interactive collaboration as a meaningful UX shift—you can steer Codex mid-task rather than waiting for final output, enabled via Settings > General > Follow-up behavior.
The emerging consensus: benchmark leadership doesn’t translate directly to developer preference. Opus 4.6 has the highest satisfaction in collaborative workflows. Codex 5.3 is preferred for constrained, autonomous long running tasks. Gemini 3.1 Pro offers the best reasoning-to-dollar ratio and is earning rapid adoption for cost-sensitive, reasoning-heavy workloads. The right choice depends on how you work, not which number is highest. For a detailed look at Sonnet 4.6 as a cost-effective alternative to Opus, see our Sonnet 4.6 technical breakdown. And for how GPT-5.4 shifted the competition beyond coding into computer use and knowledge work, see GPT-5.4: The Real Leap Isn’t Coding.
References
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.