Codex Spark and the Two-Mode Future of Coding Agents
The Model: Intelligence as a Tunable Knob
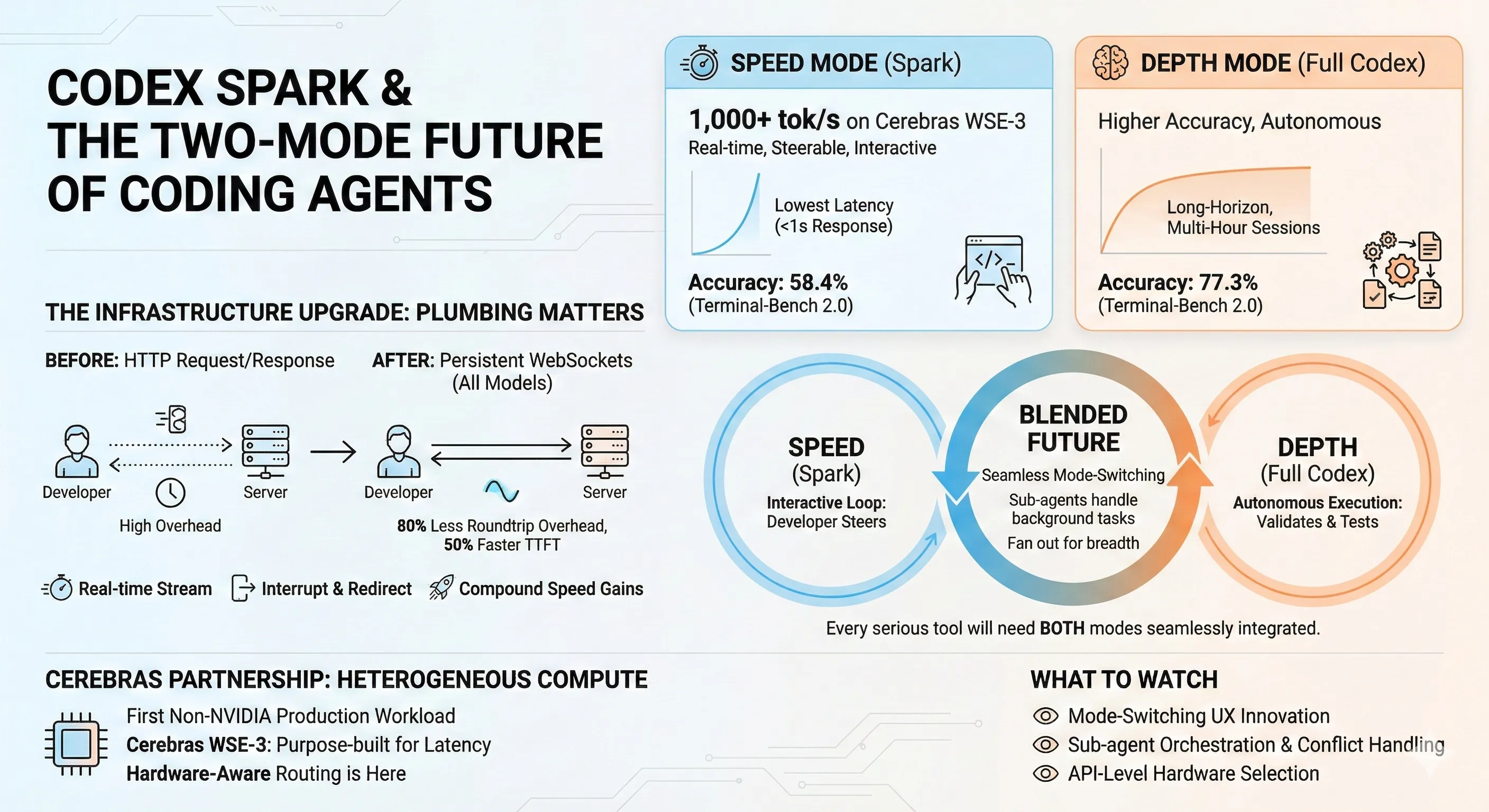
GPT-5.3-Codex-Spark is a smaller distillation of GPT-5.3-Codex, purpose-built for a specific interaction pattern: respond instantly, let the developer steer.
The benchmarks make the tradeoff explicit:
| Model | Terminal-Bench 2.0 | SWE-Bench Pro | Interaction Style |
|---|---|---|---|
| GPT-5.3-Codex | 77.3% | Higher accuracy, longer duration | Autonomous, long-running |
| GPT-5.3-Codex-Spark | 58.4% | Lower accuracy, fraction of the time | Real-time, steerable |
| GPT-5.1-Codex-mini | 46.1% | — | Previous generation |
Spark isn’t a “faster Codex.” It’s a different model designed for a different workflow. It makes minimal, targeted edits. It doesn’t auto-run tests. It lets you interrupt and redirect mid-generation. The 128k context window and text-only constraint at launch reinforce that this is the interactive mode—quick edits, not multi-hour autonomous sessions.
This is an important design choice. Rather than trying to make one model do everything, OpenAI is explicitly acknowledging that speed and depth require different architectures with different optimization targets.
The Infrastructure Story Is Bigger Than the Model
Here’s what most coverage misses: the plumbing upgrade that shipped alongside Spark benefits every Codex model, not just Spark.
OpenAI rewrote key pieces of their inference stack and introduced persistent WebSocket connections. The results:
- 80% reduction in client/server roundtrip overhead
- 30% improvement in per-token overhead
- 50% faster time-to-first-token (TTFT)
These numbers compound. A typical coding agent interaction involves dozens of roundtrips—tool calls, file reads, command executions, response streaming. Cutting 80% of the overhead per roundtrip dramatically changes how responsive the entire system feels, regardless of which model is running behind it.
The WebSocket path is enabled by default for Spark and will become the default for all models soon. This is the kind of infrastructure investment that creates durable competitive advantage—it makes every future model launch on the platform feel faster for free.
Why This Matters for Agent Builders
If you’re building coding agents or developer tools on top of LLM APIs, the lesson is clear: model speed is necessary but not sufficient. The end-to-end latency of your agent loop matters just as much. Investing in persistent connections, streaming protocols, and minimizing serialization overhead will compound across every model upgrade.
The Two-Mode Future
OpenAI is now explicit about where Codex is headed: two complementary modes that eventually blend together.
Speed mode (Spark): You’re in a tight loop with the model. You describe an edit, it responds instantly, you refine. It’s pair programming where your partner types at 1,000 words per second.
Depth mode (full Codex): You describe a task—“refactor this authentication module to use JWT”—and the model works autonomously for minutes or hours. It reads files, writes tests, validates changes, and comes back with a complete result.
The blended future: You iterate in real-time on a UI component while sub-agents handle the backend migration in the background. You fan out tasks to parallel models when you need breadth. You never have to choose a single mode up front.
This maps directly to how experienced developers already work. You alternate between focused, interactive editing (tweaking a function, adjusting CSS, exploring an API) and delegating larger chunks of work (code review, test writing, refactoring). The two-mode model just gives each pattern its own optimized runtime.
What This Means for Your Architecture
If you’re building developer tools or coding agents, start thinking about mode-switching now:
// Conceptual: mode-aware agent routinginterface AgentRequest { task: string; context: string[]; estimatedComplexity: "interactive" | "autonomous";}
function routeToModel(request: AgentRequest): ModelConfig { if (request.estimatedComplexity === "interactive") { return { model: "spark", // Speed-optimized streaming: true, // Real-time token delivery interruptible: true, // Developer can redirect autoRunTests: false, // Keep it lightweight }; }
return { model: "full-codex", // Intelligence-optimized streaming: false, // Batch result interruptible: false, // Let it work autonomously autoRunTests: true, // Validate its own output };}The key design question becomes: how does a user signal which mode they want, and how does the system transition between modes seamlessly? This is where UX innovation will happen over the next year.
The Cerebras Angle: Heterogeneous Compute Goes Mainstream
Codex Spark is the first production OpenAI workload running on non-NVIDIA hardware. The Cerebras Wafer Scale Engine 3 is a purpose-built AI accelerator where the entire chip is a single wafer—no chiplet packaging, no inter-chip communication overhead.
OpenAI’s framing is clear: GPUs remain foundational for training and cost-effective broad inference. Cerebras complements GPUs by excelling at latency-sensitive workloads. The two can even combine for single workloads.
This is a signal that the AI inference stack is going heterogeneous. Different hardware for different latency/throughput tradeoffs. If you’re planning infrastructure for AI-powered developer tools, the era of “just use GPUs for everything” is ending. Expect to see more hardware-aware routing where your agent orchestrator picks the optimal backend based on the task’s latency requirements.
What to Watch
Three things to track as this space evolves:
-
Mode-switching UX: How will tools let developers seamlessly move between interactive and autonomous modes? The current explicit toggle is crude—the future is likely automatic detection based on task complexity.
-
Sub-agent orchestration: When speed-mode and depth-mode agents run simultaneously, coordination becomes the hard problem. How do you handle conflicts when the interactive session and the background agent both modify the same file?
-
Hardware-aware routing at the API level: Will OpenAI (and others) expose hardware selection in their APIs? Or will it remain abstracted behind model selection? The answer shapes how much control developers get over the speed/intelligence tradeoff.
Conclusion
Codex Spark isn’t primarily about a new model. It’s about the emerging architecture of coding agents: dual modes optimized for different interaction patterns, infrastructure that makes every model faster, and heterogeneous compute that matches hardware to workload.
The 58.4% accuracy on Terminal-Bench doesn’t matter in isolation. What matters is that for interactive coding—the quick edit, the CSS tweak, the “rename this variable everywhere”—speed at 1,000+ tok/s with good-enough intelligence is more useful than perfect accuracy at 100 tok/s.
Every coding tool will need both modes. The competitive differentiation won’t be in which model you use, but in how seamlessly you blend speed and depth into a single developer experience. For a detailed technical comparison of how the leading models stack up across these different modes, see our breakdown of Gemini 3.1 Pro, Opus 4.6, and Codex 5.3.
Key Takeaways
- Codex Spark runs at 1,000+ tok/s on Cerebras’ Wafer Scale Engine 3—a deliberate intelligence-for-speed tradeoff (58.4% vs 77.3% on Terminal-Bench 2.0)
- The infrastructure matters more than the model: 80% reduction in roundtrip overhead, 30% per-token improvement, and 50% faster TTFT via persistent WebSockets—applied to all Codex models
- Coding agents are splitting into two modes: real-time interactive (speed) and long-horizon autonomous (depth). Every serious tool will need both.
- First production OpenAI workload on non-NVIDIA hardware—the Cerebras partnership is shipping real traffic
References
- Introducing GPT-5.3-Codex-Spark — OpenAI official announcement and model details
- Introducing OpenAI GPT-5.3-Codex-Spark Powered by Cerebras — Cerebras partnership announcement and Wafer Scale Engine details
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.