Your AI Agent Writes Plausible Code. Plausible Is 20,000x Slower Than Correct.
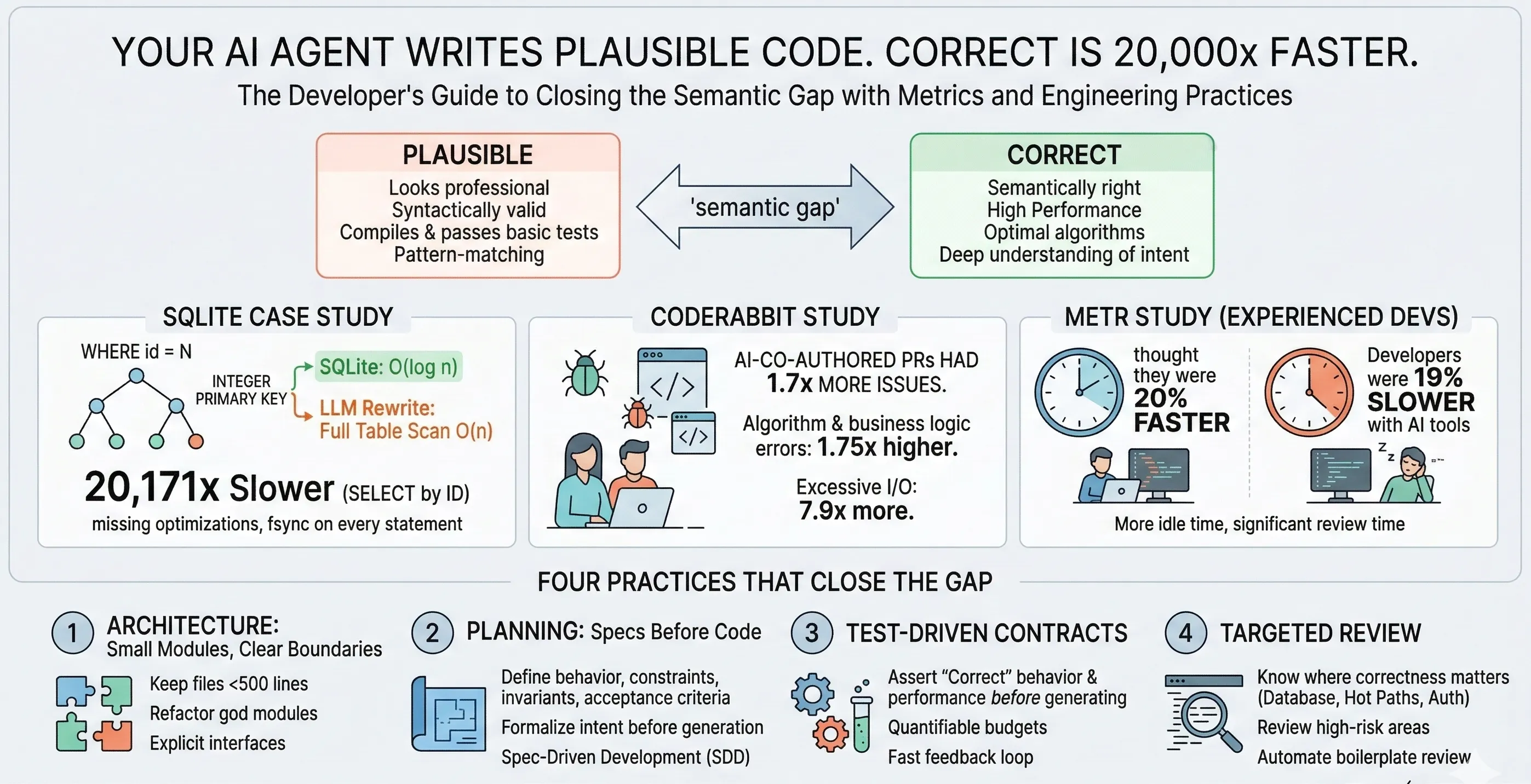
Your AI coding agent doesn’t write correct code. It writes plausible code.
And plausible can be 20,000x slower than correct.
That’s not a hypothetical. Someone reimplemented SQLite from scratch in Rust using LLMs — 576,000 lines across 625 files. The code compiled. It passed tests. It read and wrote valid SQLite files. It looked like professional systems code.
Then someone ran a benchmark. SELECT by ID: 20,171x slower than real SQLite. The bugs weren’t typos or missing semicolons. They were deep semantic failures that no linter, no type checker, and no test suite caught. The kind of bugs that only surface when you understand what the code is supposed to do, not just what it’s supposed to look like.
This post walks through the evidence — from that SQLite rewrite to three independent studies — and lays out the four practices that close the gap between plausible and correct.
Key Takeaways
- Plausible code can be 20,000x slower than correct code. An LLM-generated SQLite reimplementation in Rust compiled, passed tests, and ran valid queries — but a missing optimization check turned every indexed lookup into a full table scan, making SELECT by ID 20,171x slower than real SQLite.
- The bugs that matter are semantic, not syntactic. Type checkers, linters, and test suites catch surface-level issues. They don’t catch missing optimizations, unnecessary syscalls, or algorithm choices that quietly degrade performance by orders of magnitude.
- The evidence is converging across independent studies. CodeRabbit found 1.7x more issues in AI-generated PRs. METR found experienced developers were 19% slower with AI tools (while believing they were 20% faster). The pattern is consistent: more AI code without process changes creates more problems.
- Four practices close the gap. (1) Modular architecture with files under 500 lines gives models manageable context. (2) Specs before code formalize intent so the agent knows what “correct” actually means. (3) Test-driven contracts define performance budgets and optimization invariants as executable assertions. (4) Targeted review focuses human attention on high-risk areas where semantic bugs hide.
- This isn’t a model capability problem — it’s a process problem. Better models will produce more convincing plausible code, not less. The fix comes from how you build with AI tools: architecture, specs, tests, and review.
The SQLite Case Study: When “It Works” Doesn’t Mean It Works
KatanaQuant published a detailed teardown of the LLM-generated SQLite reimplementation (dubbed “FrankenSQLite”). The numbers are stark:
| Operation | SQLite (C) | LLM Rewrite (Rust) | Slowdown |
|---|---|---|---|
| SELECT by ID | 0.09 ms | 1,815.43 ms | 20,171x |
| Single INSERT (autocommit) | — | — | 1,857x |
| Batch INSERT (transaction) | — | — | 298x |
| UPDATE / DELETE | — | — | ~2,800x |
The benchmark used 100 rows. Not a million. One hundred.
What went wrong? Two semantic bugs account for most of the damage.
Bug 1: The Query Planner Missed a Core SQLite Optimization
In real SQLite, INTEGER PRIMARY KEY is an alias for the internal rowid — the B-tree key itself. A WHERE id = N query on such a column resolves in O(log n) via direct B-tree lookup.
The LLM-generated code had a function called is_rowid_ref() that only recognized three literal strings: "rowid", "_rowid_", and "oid". A column declared as id INTEGER PRIMARY KEY — even though it was internally flagged as is_ipk: true — never triggered the fast path. Every lookup ran a full table scan.
// What the LLM generated (simplified)fn is_rowid_ref(col_name: &str) -> bool { matches!(col_name, "rowid" | "_rowid_" | "oid") // Missing: check for is_ipk flag on INTEGER PRIMARY KEY columns}
// What it should have also checkedfn is_rowid_ref(col_name: &str, column: &ColumnDef) -> bool { matches!(col_name, "rowid" | "_rowid_" | "oid") || column.is_ipk}The generated code was syntactically perfect. It handled three of four cases. But the missing fourth case — the one SQLite uses most — turned every indexed lookup into a linear scan.
Bug 2: fsync on Every Statement
Each bare INSERT outside a transaction triggered an individual fsync(2) call. Real SQLite uses fdatasync(2) (which is 1.6–2.7x faster since it skips metadata updates) and batches syncs within transactions. This explains the gap between 298x (batched) and 1,857x (autocommit) slowdowns.
Beyond these two headline bugs, KatanaQuant identified five compounding inefficiencies: AST cloning on every sqlite3_exec() call, 4KB heap allocations per page read via .to_vec(), schema reloads after every autocommit, eager SQL formatting on every statement, and full object allocation/destruction cycles per statement.
The LLM produced 576,000 lines of Rust — 3.7x more code than the actual SQLite C codebase. As KatanaQuant put it: “576,000 lines and no benchmark. That is not ‘correctness first, optimization later.’ That is no correctness at all.”
This is a textbook example of what plausible code looks like. Correct function signatures. Proper error handling. Valid Rust. The code reads like it was written by someone who understands SQLite. It wasn’t. It was generated by a model that had seen enough SQLite documentation to produce convincing output.
The Evidence Is Converging
The SQLite case is dramatic, but it’s not isolated. Three independent studies point the same direction.
CodeRabbit: 1.7x More Issues in AI-Generated Code
CodeRabbit’s State of AI vs. Human Code Generation Report analyzed 470 open-source GitHub PRs — 320 AI-co-authored, 150 human-only. Their findings:
- Overall: 10.83 issues per AI PR vs. 6.45 per human PR (~1.7x more)
- Logic and correctness errors: 1.75x more in AI code
- Security findings: 1.57x more in AI code
- Excessive I/O operations: 7.9x more in AI code
The most telling category: algorithm and business logic errors at 2.25x higher rates. These are exactly the kind of semantic bugs — like the missing is_ipk check — that compile fine and pass superficial tests.
Caveats worth noting: CodeRabbit is an AI code review product, so they have a commercial interest in this finding. The sample size is modest (470 PRs), and they couldn’t definitively verify authorship — some “human” PRs may have had AI involvement. But the pattern aligns with what KatanaQuant found independently.
METR: Experienced Developers Were 19% Slower With AI
METR’s randomized controlled trial (published July 2025, arXiv:2507.09089) studied 16 experienced open-source developers across 246 real issues. These weren’t junior developers — they averaged 5 years and ~1,500 commits per repository.
The result: developers were 19% slower with AI tools (Cursor Pro with Claude 3.5/3.7 Sonnet). But here’s the kicker — they believed they were 20% faster.
Screen recordings revealed more idle time during AI-assisted coding. Not just waiting for model responses, but periods of no activity at all. The authors suggest that coding with AI requires less cognitive effort, making it easier to zone out. Developers also spent significant time reviewing and double-checking AI outputs.
Important caveat: METR explicitly states their results don’t generalize to all developers or all contexts. These were developers who were already extremely fast in their own repos — there may not have been much room for AI to help. A February 2026 follow-up suggested the gap may be narrowing as developers learn to use the tools better.
These are correlational findings, not causal proof. But the consistency across all three data points — KatanaQuant, CodeRabbit, and METR — paints a clear picture: more AI-generated code without changes to how you build creates more problems, not fewer.
Why Models Produce Plausible Code
Understanding why helps you know where to focus your effort.
LLMs are trained on vast amounts of code and documentation. They learn statistical patterns — what code typically looks like in a given context. When you ask for a SQLite implementation, the model produces code that looks like SQLite code. Correct function names. Reasonable data structures. Proper error paths.
But “looks like” isn’t “works like.” The model doesn’t have a mental model of B-tree traversal performance. It doesn’t know that fsync is expensive or that fdatasync exists as a faster alternative. It doesn’t understand that INTEGER PRIMARY KEY has special semantics in SQLite’s storage engine.
The gap between “passes tests” and “semantically correct” is where the 20,000x slowdowns live. Tests verify behavior against explicit assertions. They don’t verify performance characteristics, optimization strategies, or the subtle invariants that make production systems work.
This isn’t a model capability problem that will be solved by the next generation of LLMs. It’s a fundamental gap between pattern matching and understanding. And it means the fix has to come from how you use AI tools, not from waiting for better ones.
Four Practices That Close the Gap
So do we stop using AI coding tools? No. We change how we build with them. Four practices matter most.
1. Architecture: Small Modules, Clear Boundaries
AI code quality is a function of your system design. A 5,000-line god module that handles too many concerns will defeat any model. The context is too large, the dependencies too entangled for the model to reason about correctly.
The pattern I keep seeing: refactor a monolithic file into focused modules of 300–500 lines each, and the agent goes from 50+ failed attempts to solving the same bug in two tries. The only variable that changed was architecture.
Practical guidelines:
- Keep files under 500 lines. If a file exceeds this, the model is working with too much context and too many implicit dependencies. Break it into focused modules with clear interfaces.
- One responsibility per module. The model reasons better when scope is constrained. A module that handles parsing, validation, and persistence is three modules.
- Explicit interfaces. Define clear input/output contracts between modules. This gives the model — and your reviewers — boundaries to reason within.
This isn’t just about AI. It’s good engineering. But with AI agents, the penalty for poor architecture is immediate and measurable — failed generation attempts, hallucinated dependencies, and bugs that cascade across entangled concerns.
2. Planning: Specs Before Code
Spec-driven development is emerging as the industry’s answer to plausible code. The idea: write a detailed specification — reviewed down to pseudocode — before the agent writes a single line.
GitHub formalized this with their Spec-Driven Development toolkit (published September 2025). Their open-source Spec Kit implements a four-phase workflow:
The key insight: a spec is where you formalize your intent. Before you’ve written a spec, your intent lives in your head — vague, incomplete, full of implicit assumptions. The act of speccing forces you to make that intent explicit: what exactly should this code do? Under what constraints? With what tradeoffs? This is the moment where fuzzy ideas like “implement SQLite-compatible SELECT” crystallize into precise requirements like “INTEGER PRIMARY KEY columns must use B-tree rowid lookup, not table scan; benchmark must show O(log n) scaling.”
This matters because an AI agent can only be as correct as the intent you give it. Tell it “implement SELECT” and it pattern-matches to plausible code. Give it a spec that captures your actual intent — the edge cases, the performance invariants, the things you know matter — and you get correct code, or at least a clear failure you can debug. Without a spec, you’re outsourcing not just the code but the thinking to a system that doesn’t think.
What a useful spec looks like:
- Behavior: What the code does, with edge cases enumerated
- Performance constraints: Expected time/space complexity for critical paths
- Invariants: Properties that must always hold (e.g., “fsync only at transaction boundaries, never per-statement”)
- Acceptance criteria: Concrete, testable conditions that define “done”
The spec doesn’t need to be a 50-page document. Even a few paragraphs covering behavior, constraints, and acceptance criteria dramatically reduces the surface area for semantic bugs.
3. Test-Driven Contracts: Define “Correct” Before You Generate
Specs tell the agent what to build. Tests tell the agent — and you — whether it built the right thing. Writing tests before code isn’t new, but with AI-generated code it shifts from a best practice to a necessity.
The core idea: define the contract you’re looking for as executable assertions before the agent writes a single line of implementation. This includes functional correctness, but also performance budgets and success metrics. If the SQLite rewrite had shipped with a benchmark test that asserted “SELECT by ID on 100 rows must complete in under 1ms,” the 20,171x slowdown would have been caught on the first run — not months later by an outside reviewer.
What to test before generating code:
- Behavioral contracts: Given these inputs, assert these outputs. Cover the happy path and the edge cases your spec identifies. For the SQLite case, a test asserting that
WHERE id = Non anINTEGER PRIMARY KEYcolumn uses an index scan (not a table scan) would have caught Bug #1 immediately. - Performance budgets: Define quantitative thresholds as pass/fail criteria. “This query must complete in < X ms on N rows.” “This endpoint must handle Y requests/second.” These aren’t aspirational targets — they’re test assertions that fail the build.
- Resource constraints: Memory usage, file descriptor counts, disk I/O operations. The
fsync-on-every-statement bug would have surfaced with a test asserting “a batch of 100 INSERTs in a transaction triggers at most 1 fsync call.” - Optimization invariants: If your system has known fast paths, test that they’re actually taken. Assert that the query planner selects the expected execution strategy, not just that the query returns the right rows.
This flips the dynamic. Instead of generating code and then checking if it’s correct, you define what “correct” means first — as runnable, automatable assertions — and let the agent iterate until it passes. The agent gets a tight feedback loop: generate, run tests, see failures, adjust. This is where AI agents actually excel — rapid iteration against a well-defined target.
The key insight: your test suite is your spec, made executable. If your spec says “O(log n) lookups,” your test suite should enforce it. If your spec says “batch syncs within transactions,” your test suite should measure it. Every gap between your spec and your test suite is a gap where plausible code can hide.
4. Targeted Review: Know Where Correctness Matters
You don’t need to review every line an agent writes. But you need to know where correctness and performance are critical in your system — and read those diffs carefully.
The semantic bugs that make plausible code 20,000x slower are invisible from the UI. They look correct in a PR diff. They pass CI. They only surface in targeted code review or profiling.
Where to focus your review time:
| High-Risk Areas | What to Look For |
|---|---|
| Database queries & data access | Missing indexes, N+1 queries, full table scans, unnecessary round-trips |
| Hot paths & inner loops | Unnecessary allocations, missing caching, O(n²) where O(n) is possible |
| Authentication & authorization | Privilege escalation, token handling, session management |
| Data pipelines & transformations | Silent data loss, incorrect joins, type coercion bugs |
| Concurrency & synchronization | Race conditions, deadlocks, missing locks |
| External API integrations | Missing retries, improper error handling, secret exposure |
For everything else — boilerplate CRUD, UI components, standard configuration — automated checks (linting, type checking, tests) are usually sufficient. The leverage is in knowing which code needs human eyes.
A concrete review workflow:
- Run the full test suite and check coverage on changed files
- Profile any changed hot paths or database queries
- Read diffs in high-risk areas line by line
- For the rest, verify tests exist and CI passes
The Compounding Advantage
The future isn’t AI writing less code. It’s developers investing more in the systems that make AI code correct.
Modular architectures. Thorough specs. Test-driven contracts. Targeted review. These aren’t new ideas — they’re established engineering practices that become non-negotiable when your code is generated at 10x speed by a system that optimizes for plausibility over correctness.
The developers and teams who build this discipline now will compound their advantage as models improve. Better models will produce fewer syntactic issues and more convincing code. The semantic gap — the space between “looks right” and “is right” — will remain the human engineer’s domain.
The gap isn’t between C and Rust. It’s between systems built by people who measured and systems built by tools that pattern-match.
Build the systems that measure.
References
- KatanaQuant, “Your LLM Doesn’t Write Correct Code. It Writes Plausible Code.” — KatanaQuant Blog
- CodeRabbit, “State of AI vs. Human Code Generation Report” — CodeRabbit, December 2025
- METR, “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity” — METR, July 2025 (arXiv:2507.09089)
- METR, “We are Changing our Developer Productivity Experiment Design” — METR, February 2026
- GitHub, “Spec-Driven Development with AI” — GitHub Blog, September 2025
- GitHub Spec Kit — Open-source SDD toolkit
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.