Agent-Operated CI/CD: The Architecture Making AI Coding Agents Actually Work
The Pattern Emerging for Agent-Operated Pipelines
Engineers using AI coding agents are reporting significant productivity gains—GitHub’s research shows 55% faster task completion and code review times dropping substantially. But the difference isn’t just the agent. It’s how teams have wired it into their CI/CD.
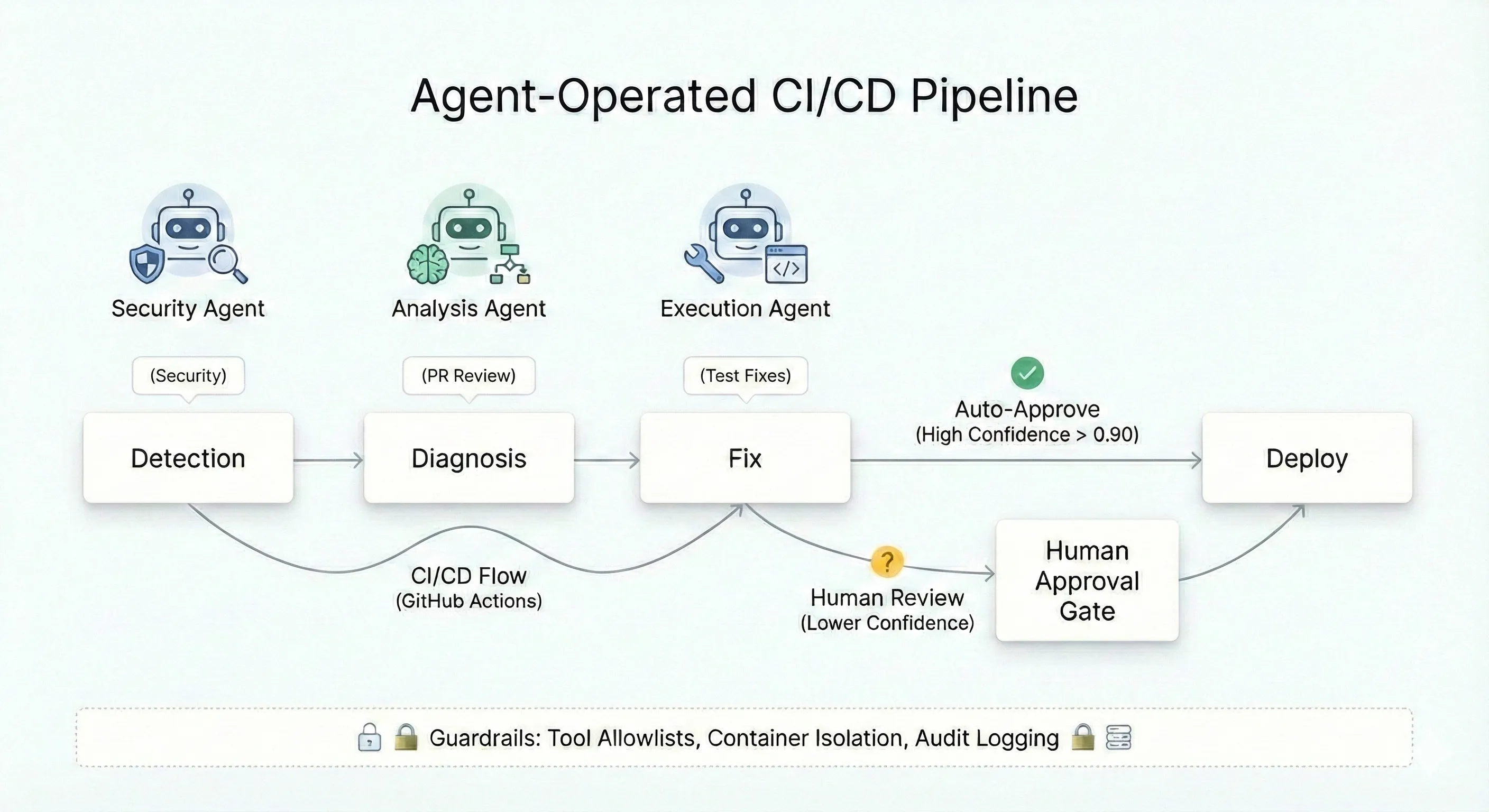
The architecture making this work follows a consistent pattern:
Detection → Diagnosis → Fix → Deploy
When a build fails or an alert fires, the agent investigates automatically. It correlates logs, traces, and deployment history. Stack traces get analyzed, specific files get flagged. The agent generates hypotheses about root cause, validates them against telemetry, and opens a PR with the fix. In mature setups, humans only see a notification that the issue was resolved.
The key insight: specialized agents at each stage. Analysis agents review PRs. Security agents flag vulnerabilities. Execution agents handle deployment. Each scoped to specific tools and permissions.
GitHub Copilot Autofix: Security Vulnerabilities at 3x Speed
Copilot Autofix is enabled by default for all repositories using CodeQL. No separate subscription required. When CodeQL detects a vulnerability, Autofix generates a patch automatically.
The numbers from GitHub’s public beta: median fix time dropped from 1.5 hours to 28 minutes. SQL injection fixes are 12x faster (18 minutes vs 3.7 hours). XSS fixes are 7x faster.
Setting Up CodeQL with Autofix
name: CodeQL Security Scan
on: push: branches: [main] pull_request: branches: [main] schedule: - cron: "30 1 * * 0" # Weekly Sunday 1:30 AM UTC
jobs: analyze: name: Analyze (${{ matrix.language }}) runs-on: ubuntu-latest permissions: security-events: write packages: read actions: read contents: read
strategy: fail-fast: false matrix: include: - language: javascript-typescript build-mode: none - language: python build-mode: none
steps: - uses: actions/checkout@v4
- name: Initialize CodeQL uses: github/codeql-action/init@v4 with: languages: ${{ matrix.language }} build-mode: ${{ matrix.build-mode }} queries: security-extended
- name: Perform CodeQL Analysis uses: github/codeql-action/analyze@v4 with: category: "/language:${{matrix.language}}"Recent updates (late 2025): You can now assign alerts to Copilot directly. Select multiple alerts in a security campaign, click “Assign Copilot,” and it opens a PR within 30 seconds.
OpenAI Codex: Minimal Changes to Make Tests Pass
Codex CLI integrates with GitHub Actions through the openai/codex-action@v1 action. Its strength is identifying “the minimal change needed to make all tests pass” through iterative verification.
Auto-Fix Workflow on CI Failure
name: Codex Auto-Fix on Failure
on: workflow_run: workflows: ["CI"] types: [completed]
permissions: contents: write pull-requests: write
jobs: auto-fix: if: ${{ github.event.workflow_run.conclusion == 'failure' }} runs-on: ubuntu-latest env: OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }} FAILED_HEAD_BRANCH: ${{ github.event.workflow_run.head_branch }} FAILED_HEAD_SHA: ${{ github.event.workflow_run.head_sha }} FAILED_RUN_URL: ${{ github.event.workflow_run.html_url }}
steps: - name: Checkout Failing Ref uses: actions/checkout@v4 with: ref: ${{ env.FAILED_HEAD_SHA }} fetch-depth: 0
- name: Setup Node.js uses: actions/setup-node@v4 with: node-version: "20" cache: "npm"
- name: Install dependencies run: npm ci
- name: Run Codex uses: openai/codex-action@v1 with: openai-api-key: ${{ secrets.OPENAI_API_KEY }} prompt: | Read the repository and run the test suite. Identify the minimal change needed to make all tests pass. Implement only that change. Do not refactor unrelated code. Keep changes small and surgical. sandbox: workspace-write safety-strategy: drop-sudo
- name: Verify tests pass run: npm test --silent
- name: Create PR with fixes if: success() uses: peter-evans/create-pull-request@v6 with: commit-message: "fix(ci): auto-fix failing tests via Codex" branch: codex/auto-fix-${{ github.event.workflow_run.run_id }} base: ${{ env.FAILED_HEAD_BRANCH }} title: "Auto-fix failing CI via Codex" body: | Codex automatically generated this PR in response to a CI failure.
**Failed run:** ${{ env.FAILED_RUN_URL }}Safety strategies: Use drop-sudo (default) on GitHub-hosted runners. For self-hosted runners, use unprivileged-user. Use read-only for exploration tasks.
Claude Code: Feedback Loops Until Tests Pass
Claude Code’s GitHub Action (anthropics/claude-code-action@v1) automatically detects whether to run in autonomous mode or respond to @claude mentions. Its strength is feeding failures back into context and iterating until resolution.
PR Review with Inline Comments
name: Claude Code Review
on: pull_request: types: [opened, synchronize]
jobs: review: runs-on: ubuntu-latest permissions: contents: read pull-requests: write actions: read
steps: - uses: actions/checkout@v4 with: fetch-depth: 1
- uses: anthropics/claude-code-action@v1 with: anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }} additional_permissions: | actions: read prompt: | Review this pull request focusing on: - Code quality and potential bugs - Security implications - Performance considerations
Use inline comments for specific issues. Use a top-level comment for overall feedback. claude_args: | --allowedTools "Read,Grep,Glob,Bash(gh pr comment:*),Bash(gh pr diff:*)"CI Failure Investigation
When users comment @claude why did the CI fail? on a PR, Claude analyzes workflow logs via the github_ci MCP server:
name: Claude CI Helper
on: issue_comment: types: [created] pull_request_review_comment: types: [created]
jobs: claude: runs-on: ubuntu-latest permissions: contents: write pull-requests: write issues: write actions: read
steps: - uses: actions/checkout@v4
- uses: anthropics/claude-code-action@v1 with: anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }} additional_permissions: | actions: read trigger_phrase: "@claude"Security restrictions: Claude cannot modify .github/workflows/ files, cannot bypass branch protection, and Bash is disabled by default (explicitly enable needed commands via --allowedTools).
Multi-Agent Orchestration Patterns
The real power comes from chaining specialized agents. Use job dependencies (needs) for sequential execution and matrix strategies for parallel execution.
Confidence-Based Routing
name: Multi-Agent Pipeline
on: pull_request:
jobs: # Stage 1: Parallel Analysis Agents analysis: runs-on: ubuntu-latest strategy: fail-fast: false matrix: agent: [code-quality, security-scan, test-coverage] outputs: results: ${{ steps.analyze.outputs.results }} steps: - uses: actions/checkout@v4 - name: Run ${{ matrix.agent }} id: analyze run: | RESULT=$(./agents/${{ matrix.agent }}.sh) echo "results=$RESULT" >> $GITHUB_OUTPUT
# Stage 2: Decision Agent decision: needs: analysis runs-on: ubuntu-latest outputs: action: ${{ steps.decide.outputs.action }} confidence: ${{ steps.decide.outputs.confidence }} steps: - name: Aggregate and Decide id: decide run: | # Threshold-based routing CONFIDENCE=0.87 if (( $(echo "$CONFIDENCE >= 0.90" | bc -l) )); then echo "action=auto_approve" >> $GITHUB_OUTPUT elif (( $(echo "$CONFIDENCE >= 0.70" | bc -l) )); then echo "action=human_review" >> $GITHUB_OUTPUT else echo "action=reject" >> $GITHUB_OUTPUT fi echo "confidence=$CONFIDENCE" >> $GITHUB_OUTPUT
# Stage 3A: Auto-Approve Path auto-approve: needs: decision if: needs.decision.outputs.action == 'auto_approve' runs-on: ubuntu-latest steps: - run: | gh pr review ${{ github.event.pull_request.number }} --approve \ --body "Auto-approved (confidence: ${{ needs.decision.outputs.confidence }})" env: GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
# Stage 3B: Human Review Path human-review: needs: decision if: needs.decision.outputs.action == 'human_review' runs-on: ubuntu-latest environment: requires-approval # Blocks until manual approval steps: - run: echo "Awaiting human review"Guardrails: The Non-Negotiable Requirements
Agent autonomy requires guardrails. Without them, you’re one hallucination away from a production incident. (For the broader case on why engineering discipline becomes more critical, not less, with AI agents, see our companion post.)
Tool Allowlists
Each agent should have explicit tool permissions. Claude Code and Codex both support this natively:
# Claude Code - explicit tool allowlistclaude_args: | --allowedTools "Read,Grep,Glob,Bash(gh pr comment:*),Bash(gh pr diff:*)"
# Codex - sandbox modessandbox: workspace-write # Can modify files in workspace only# Other options: read-only, danger-full-accessThe principle: agents can only touch what they’re explicitly allowed to touch. A code review agent doesn’t need deployment permissions. A security scanner doesn’t need write access.
Confidence Thresholds
Industry consensus places optimal thresholds between 0.60-0.90 depending on risk:
| Risk Level | Threshold | Example Actions |
|---|---|---|
| Low | 0.60+ | Code comments, tagging |
| Medium | 0.75+ | Test execution, staging deploy |
| High | 0.90+ | Production deploy, infra changes |
Audit Logging
Every agent action needs an audit trail:
{ "event_id": "uuid", "timestamp": "2026-02-03T10:30:00Z", "agent_id": "analysis-agent-v2", "action": "deploy_staging", "confidence_score": 0.87, "policy_applied": "deployment_policy_v2", "human_reviewer": null, "outcome": "approved"}The Shift: Automation to Autonomy
DevOps is shifting from automation (do what I say) to autonomy (decide what’s best). Your CI/CD pipeline doesn’t need more YAML. It needs agents with the right guardrails.
The infrastructure is ready. All major coding agents now have native GitHub Actions integration. The question is no longer “can we do this?” but “how do we do this safely?”
Start small: enable Copilot Autofix for security vulnerabilities. Add a Claude review job for PRs touching critical paths. Use confidence thresholds to gate autonomous actions. Build trust incrementally.
The teams seeing 70% more PRs merged aren’t running agents without oversight. They’ve built the scaffolding that makes autonomy safe.
Reference Implementations
Complete Multi-Agent Pipeline Template
Below is a production-ready workflow combining all patterns discussed:
name: Complete AI Agent Pipeline
on: pull_request: workflow_dispatch: inputs: confidence-threshold: description: "Minimum confidence for auto-approval" default: "0.90" type: string
permissions: contents: read pull-requests: write security-events: write actions: read
jobs: # Security Analysis with Copilot Autofix security-scan: runs-on: ubuntu-latest outputs: vulnerabilities: ${{ steps.scan.outputs.vuln_count }} steps: - uses: actions/checkout@v4 - uses: github/codeql-action/init@v4 with: languages: javascript-typescript queries: security-extended - uses: github/codeql-action/analyze@v4 - name: Count vulnerabilities id: scan run: | # Parse CodeQL results VULN_COUNT=$(gh api repos/${{ github.repository }}/code-scanning/alerts --jq 'length') echo "vuln_count=$VULN_COUNT" >> $GITHUB_OUTPUT env: GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
# Claude Code Review code-review: runs-on: ubuntu-latest outputs: review-score: ${{ steps.review.outputs.score }} steps: - uses: actions/checkout@v4 - uses: anthropics/claude-code-action@v1 id: review with: anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }} prompt: | Review this PR. Return a JSON object with: - score: 0-100 quality score - issues: array of specific problems - recommendation: approve/request_changes/comment claude_args: | --json-schema '{"type":"object","properties":{"score":{"type":"number"},"issues":{"type":"array"},"recommendation":{"type":"string"}}}' --allowedTools "Read,Grep,Glob,Bash(gh pr diff:*)"
# Decision Gate decision: needs: [security-scan, code-review] runs-on: ubuntu-latest outputs: action: ${{ steps.decide.outputs.action }} steps: - name: Evaluate id: decide env: VULNS: ${{ needs.security-scan.outputs.vulnerabilities }} SCORE: ${{ needs.code-review.outputs.review-score }} THRESHOLD: ${{ github.event.inputs.confidence-threshold || '0.90' }} run: | if [ "$VULNS" -gt 0 ]; then echo "action=block_security" >> $GITHUB_OUTPUT elif (( $(echo "$SCORE >= 80" | bc -l) )); then echo "action=auto_approve" >> $GITHUB_OUTPUT else echo "action=human_review" >> $GITHUB_OUTPUT fi
# Auto-approve high-confidence PRs auto-approve: needs: decision if: needs.decision.outputs.action == 'auto_approve' runs-on: ubuntu-latest steps: - run: gh pr review ${{ github.event.pull_request.number }} --approve env: GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
# Block PRs with security issues security-block: needs: decision if: needs.decision.outputs.action == 'block_security' runs-on: ubuntu-latest steps: - run: | gh pr comment ${{ github.event.pull_request.number }} \ --body "Blocked: Security vulnerabilities detected. Run Copilot Autofix or resolve manually." exit 1 env: GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
# Request human review for medium-confidence human-review: needs: decision if: needs.decision.outputs.action == 'human_review' runs-on: ubuntu-latest environment: requires-approval steps: - run: echo "Awaiting human approval"Reusable Agent Workflow Module
name: Reusable Agent Module
on: workflow_call: inputs: agent-type: required: true type: string confidence-threshold: required: false type: number default: 0.85 context-data: required: false type: string secrets: API_KEY: required: true outputs: result: value: ${{ jobs.run-agent.outputs.result }} confidence: value: ${{ jobs.run-agent.outputs.confidence }} should-continue: value: ${{ jobs.run-agent.outputs.should_continue }}
jobs: run-agent: runs-on: ubuntu-latest outputs: result: ${{ steps.agent.outputs.result }} confidence: ${{ steps.agent.outputs.confidence }} should_continue: ${{ steps.decision.outputs.continue }} steps: - uses: actions/checkout@v4
- name: Run Agent id: agent env: API_KEY: ${{ secrets.API_KEY }} AGENT_TYPE: ${{ inputs.agent-type }} CONTEXT: ${{ inputs.context-data }} run: | python agents/${{ inputs.agent-type }}/main.py \ --context "$CONTEXT" \ --output result.json
echo "result=$(jq -r '.result' result.json)" >> $GITHUB_OUTPUT echo "confidence=$(jq -r '.confidence' result.json)" >> $GITHUB_OUTPUT
- name: Evaluate Threshold id: decision run: | CONF=${{ steps.agent.outputs.confidence }} THRESH=${{ inputs.confidence-threshold }} if (( $(echo "$CONF >= $THRESH" | bc -l) )); then echo "continue=true" >> $GITHUB_OUTPUT else echo "continue=false" >> $GITHUB_OUTPUT fiKey Takeaways
- AI coding agents work best when integrated into CI/CD with specialized roles: analysis, security, and execution agents with scoped permissions
- The major coding agents (Copilot, Codex, Claude Code, OpenCode) now have native GitHub Actions integration with distinct strengths
- Confidence thresholds between 0.70-0.90 determine when agents act autonomously vs. escalate to humans
- Multi-agent orchestration uses job chaining via
needs, matrix strategies for parallelism, and artifact passing for context - Guardrails are non-negotiable: tool allowlists, container isolation, audit logging, and human approval gates for high-risk actions
Sources
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.