How to Harness Coding Agents with the Right Infrastructure
Key Takeaways
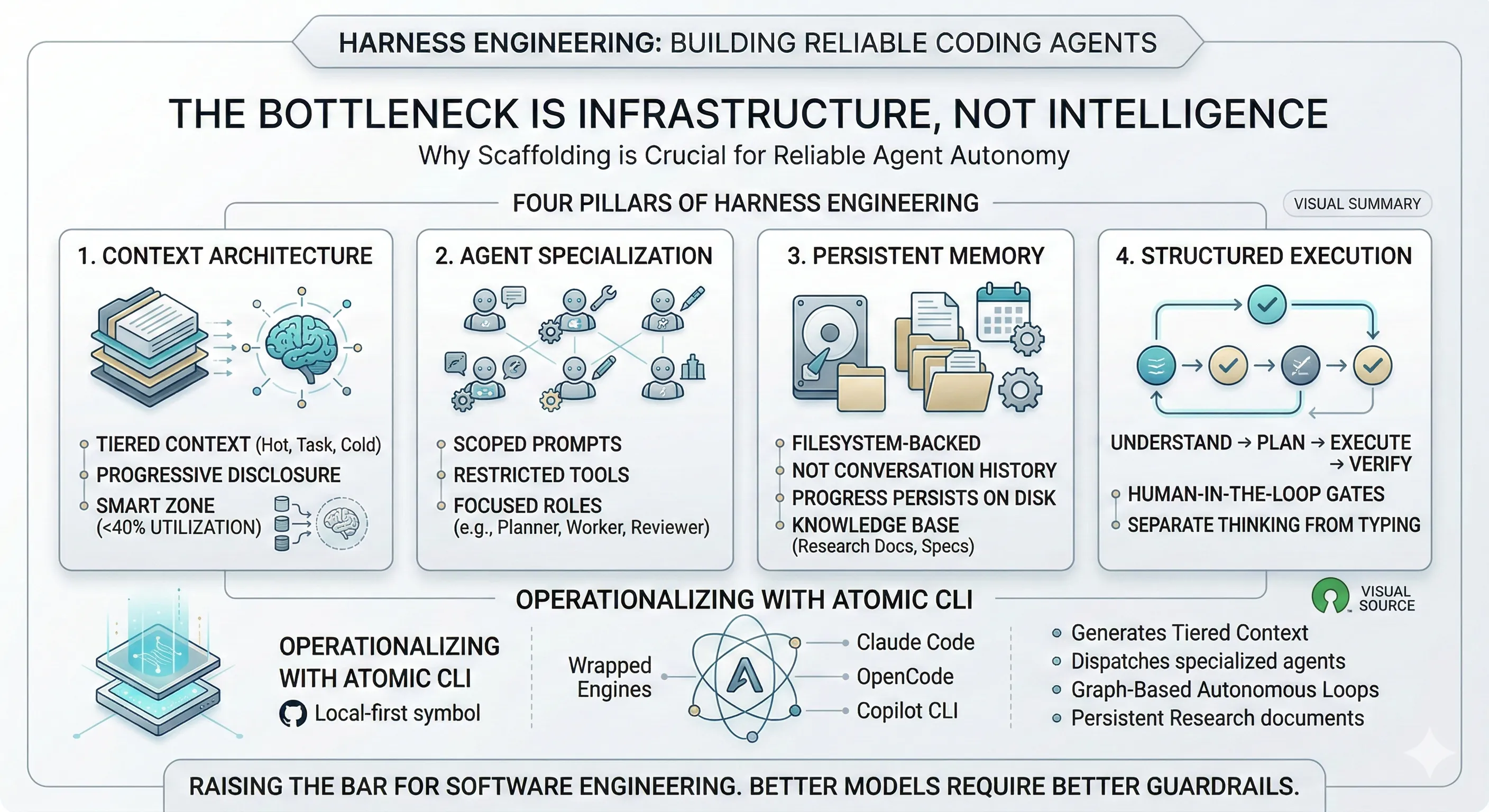
- The bottleneck is infrastructure, not intelligence. Five independent teams — OpenAI, Anthropic, Huntley, Horthy, and Vasilopoulos — all converged on the same finding: coding agents become reliable only when you build the right scaffolding around them.
- Four pillars define harness engineering: context architecture (tiered, progressive disclosure), agent specialization (scoped prompts and restricted tools), persistent memory (filesystem-backed, not conversation history), and structured execution (research, plan, execute, verify).
- Context window utilization has a sweet spot. Performance degrades beyond ~40% context utilization. Overloading agents with tools, verbose docs, and accumulated history makes them worse, not better.
- Better models make harness engineering more important, not less. More capable models unlock more autonomy, and more autonomy demands better guardrails — Carlini’s compiler project required a redesigned harness at each capability level.
- Atomic operationalizes these patterns as an open-source CLI — wrapping Claude Code, GitHub Copilot CLI, and OpenCode with three-tier context, specialized sub-agents, persistent research, and a compiled graph execution engine for autonomous multi-phase workflows.
OpenAI’s harness engineering team built a million-line codebase with three engineers. Their biggest lesson wasn’t about GPT-5’s coding ability. It was this: progress was slow until they stopped focusing on the model and started building the tools, feedback loops, and scaffolding that made agents reliable.
They aren’t alone.
Anthropic orchestrated 16 parallel Claude Opus 4.6 agents across 2,000 sessions to build a 100K-line C compiler. Nicholas Carlini, the project lead, put it directly: “Most of my effort went into designing the environment around Claude — the tests, the environment, the feedback — so that it could orient itself without me.” Geoffrey Huntley demonstrated autonomous loops shipping MVPs — but only with senior engineering judgment guiding every loop. Dex Horthy coined “harness engineering” and showed that managing context utilization is the difference between agents that hallucinate and agents that ship. A 2026 paper by Vasilopoulos validated it across 283 development sessions: three-tier context infrastructure on a 108K-line codebase prevented failures that single-file instruction sets can’t handle at scale.
Five independent teams. Same conclusion: the bottleneck is infrastructure, not intelligence.
This post is a technical deep dive into what that infrastructure actually looks like — the converging patterns, the concrete implementations, and how Atomic, an open-source CLI I built, operationalizes them. If you’re new to these patterns, start with our earlier post on how we shipped 100k LOC in two weeks with coding agents, which introduced the foundational layer that harness engineering builds on.
The Evidence Is Converging
Before getting into the how, it’s worth understanding the scale of evidence behind this claim. These aren’t theoretical positions — they’re hard-won lessons from production.
OpenAI: A Million Lines, Zero Handwritten Code
OpenAI’s internal experiment ran for five months with a team of three engineers. Every line of code — application logic, tests, CI configuration, documentation, observability — was written by Codex. They estimate they built it in roughly 1/10th the time it would have taken manually.
But the velocity didn’t come from prompting better. It came from building what OpenAI now calls the harness: scaffolding, feedback loops, documentation, and architectural constraints encoded into machine-readable artifacts that guide agent execution.
Their key practices:
- AGENTS.md as dynamic feedback loop: A short, repository-level file read by agents each session. Updated iteratively whenever agents encounter failures. Not static documentation — a living constraint system.
- Architectural guardrails: Strict dependency layers (Types → Config → Repo → Service → Runtime → UI) enforced through custom linters and structural tests. Agents cannot violate modular boundaries.
- Observability-driven iteration: Agents leverage telemetry — logs, metrics, spans — to reproduce bugs and validate fixes autonomously. The environment tells the agent what’s wrong, not the engineer.
The result: 3.5 PRs per engineer per day, with throughput increasing as the team grew.
Anthropic: 100K Lines of Compiler, 2,000 Sessions
Nicholas Carlini’s C compiler project is the most rigorous public stress test of agent-driven development. Sixteen parallel Claude instances ran in Docker containers, coordinating through a shared git repository with file-based task locks. No central orchestrator. No controlling “main” agent.
The metrics:
| Metric | Value |
|---|---|
| Duration | ~2 weeks |
| Parallel agents | 16 |
| Claude Code sessions | ~2,000 |
| Lines of Rust produced | 100,000 |
| GCC torture test pass rate | 99% |
| Real-world projects compiled | 150+ |
| Total API cost | ~$20,000 |
The compiler successfully compiles PostgreSQL, Redis, FFmpeg, CPython, the Linux 6.9 kernel, and 150+ other projects.
But the project’s central finding isn’t about the compiler. It’s about what Carlini had to build around the agents to make them productive:
- Context window pollution mitigation: Minimize console output. Log to files. Use grep-friendly error formats (
ERROR: [reason]on single lines). Pre-compute aggregate statistics rather than dumping raw data. - Agent time blindness: Claude “can’t tell time and, left alone, will happily spend hours running tests instead of making progress.” Solution: deterministic test subsampling. Each agent runs a random 1-10% of tests, but the subsample is deterministic per-agent and random across VMs — so collectively all agents cover the full test suite.
- Specialization over generalization: As the project matured, agents took specialized roles — core compiler work, deduplication (LLM-written code frequently re-implements existing functionality), performance optimization, code quality, and documentation.
- CI as harness: Near the end, Claude started frequently breaking existing functionality when implementing new features. The fix was a CI pipeline with stricter enforcement — a harness-level solution to a model-level problem.
Carlini’s summary: “I had to constantly remind myself that I was writing this test harness for Claude and not for myself.”
Huntley: Backpressure as the Core Primitive
Geoffrey Huntley’s Ralph Wiggum Loop — while :; do cat PROMPT.md | claude-code; done — went viral for its simplicity. But the technique’s power isn’t the loop. It’s the backpressure.
Backpressure is Huntley’s term for the bidirectional constraints that keep autonomous agents on track:
- Upstream: Deterministic setup, consistent context allocation, existing code patterns guide the model toward preferred implementations.
- Downstream: Tests, type checks, lints, builds, security scanners, and custom validators reject invalid work before it can be committed.
His production setup runs bare-metal on NixOS. Agents push directly to master. No branches. No human code review. Deployment happens in under 30 seconds. If something breaks, feedback loops feed back into the active session and it self-repairs.
The key insight: “The more you capture the backpressure, the more autonomy you can grant. That’s the game for the new unit economics.”
Horthy: The Smart Zone vs. The Dumb Zone
Vivek Trivedy (Langchain) coined the term “harness engineering,” and Dex Horthy introduced an empirical observation that reframes the entire conversation: as context window utilization increases, LLM outcomes degrade. For a ~168K token context window, performance starts declining around 40% utilization.
- Smart Zone (first ~40%): Focused, accurate reasoning. The agent has relevant, concise information.
- Dumb Zone (beyond ~40%): Hallucinations, looping, malformed tool calls, low-quality code. More tokens actively hurt performance.
This means overloading an agent with MCPs, verbose documentation, and accumulated conversation history doesn’t make it smarter — it makes it worse.
Horthy demonstrated this on a 300,000-line Rust codebase (BAML): a bug fix got one-shot PR approval from the CTO without revision, and a complex feature shipped 35,000 lines in 7 hours. The technique: Research-Plan-Implement with Frequent Intentional Compaction — designing the entire workflow around keeping context utilization in the 40-60% range.
Vasilopoulos (2026): Three-Tier Context, 283 Sessions
The academic validation came from a study on a 108,000-line C# distributed system. The paper describes a three-tier architecture:
- Hot-Memory Constitution: Project conventions, retrieval hooks, and orchestration protocols for immediate access during sessions.
- Specialized Domain-Expert Agents: 19 agents tailored to different functional domains.
- Cold-Memory Knowledge Base: 34 on-demand specification documents accessible when needed.
The finding: systematic, multi-layered context management significantly improves agent reliability. Single-file instruction sets (a lone AGENTS.md) break down at scale because they can’t encode domain specialization, progressive disclosure, or session-persistent knowledge.
The Four Pillars
Across all five teams, four patterns converge. I call them the four pillars of harness engineering.
Pillar 1: Context Architecture
Every team independently discovered that dumping instructions into a single file doesn’t scale. The solution is layered context with progressive disclosure.
OpenAI uses AGENTS.md as a living feedback loop. Anthropic uses extensive READMEs and progress files updated frequently per session. Horthy advocates Frequent Intentional Compaction. Vasilopoulos formalized three tiers: hot memory, domain experts, and cold-memory knowledge.
The principle: an agent should receive exactly the context it needs for its current task — no more, no less.
Pillar 2: Agent Specialization
Carlini specialized his agents into compiler work, deduplication, performance, and documentation. Vasilopoulos deployed 19 domain-specific agents. Huntley uses sub-agents to keep the main agent’s context clean.
The principle: a focused agent with restricted tools outperforms a general-purpose agent with full access. Specialization isn’t just organizational — it’s a context management strategy. Each specialist operates in the smart zone because it carries less irrelevant information.
Pillar 3: Persistent Memory
Every team uses the filesystem — not conversation history — as memory. Carlini’s agents coordinate through git-tracked task files. Huntley’s agents read from IMPLEMENTATION_PLAN.md and progress.txt. Horthy’s compaction technique produces structured markdown artifacts.
The principle: progress persists on disk, not in the context window. Each new agent session starts fresh and rebuilds context from filesystem artifacts.
Pillar 4: Structured Execution
All teams impose a deliberate sequence: understand, plan, execute, verify. OpenAI uses declarative prompts and feedback loops. Huntley separates planning mode from building mode. Horthy’s Research-Plan-Implement workflow is explicitly designed around context management.
The principle: separate thinking from typing. Research and planning happen in controlled phases. Execution happens against a verified plan. Verification happens through automated feedback (tests, linters, CI) and human review.
How Atomic Implements the Four Pillars
Atomic is an open-source CLI that wraps Claude Code, GitHub Copilot CLI, and OpenCode with the infrastructure layer these teams built. It’s not a replacement for your coding agent — it’s the harness around it.
Here’s how each pillar maps to concrete implementation.
Context Architecture: Three-Tier System
Atomic generates and manages three tiers of context:
Tier 1 loads automatically every session — the CLAUDE.md or AGENTS.md file generated by the /init slash command, which explores your codebase and produces a structured project overview:
# my-project
## OverviewExpress.js REST API with PostgreSQL and Redis caching
## Project Structure| Path | Type | Purpose || ---------- | -------- | -------------------------- || `src/api/` | Dir | Route handlers || `src/db/` | Dir | Database access layer || `src/lib/` | Dir | Shared utilities |
## Quick Reference### Commands```bashnpm run dev # Start dev servernpm test # Run testsnpm run lint # Lint & format checkTier 2 loads when specific sub-agents or skills are invoked. Each agent carries only its specialized context — a codebase-analyzer doesn’t carry the prompt for a debugger.
Tier 3 is the persistent knowledge base: research documents, specs, and session history. Agents pull from this on demand, keeping the primary context window lean.
This directly addresses Horthy’s smart zone principle: Tier 1 consumes minimal context. Tier 2 loads only when relevant. Tier 3 stays on disk until needed.
Agent Specialization: Scoped Sub-Agents
Atomic ships with specialized sub-agents, each with a focused system prompt and restricted tool access. Here’s a simplified version of the codebase-analyzer definition:
---name: codebase-analyzerdescription: Analyzes implementation detailstools: Read, Grep, Glob---
You are a specialist at understanding HOW code works.Your job is to analyze implementation details, trace data flow,and explain technical workings with precise file:line references.
## Constraints- DO NOT suggest improvements or modifications- DO NOT critique code quality- ONLY explain what the code does and how
## Analysis Strategy### Step 1: Read Entry Points- Start with main files mentioned in the request- Identify the "surface area" of the component
### Step 2: Follow the Code Path- Trace function calls step by step- Note where data is transformed- Identify external dependencies
### Step 3: Document Key Logic- Document business logic as it exists- Describe validation, transformation, error handlingNote the constraints: the analyzer is a documentarian. It describes what exists without suggesting improvements. This prevents the agent from drifting into unsolicited refactoring — a common failure mode with general-purpose agents.
Atomic ships with 10 specialized agents split across two categories — research agents that explore and document the codebase, and workflow agents that plan, execute, review, and debug implementation tasks. Each agent carries only the tools and permissions it needs: research agents are read-only observers, the planner has no write access, workers are scoped to a single task, and the reviewer can flag but not fix. This isn’t just organizational — it’s a context management strategy that keeps each agent operating in the smart zone.
The /research-codebase command dispatches these agents in parallel, each exploring a different dimension of the codebase. The main agent synthesizes their findings into a single research document.
Each sub-agent operates in its own context window. The main agent receives condensed results. This is the same pattern Carlini used (specialized agents for compiler work, deduplication, performance) and the same pattern Huntley uses (sub-agents as context extensions that keep the main agent’s window clean).
Persistent Memory: Filesystem-Backed Research
Atomic’s research system produces structured documents with YAML frontmatter:
---date: 2026-03-01researcher: codebase-analyzergit_commit: abc1234branch: maintopic: authentication-flowtags: [auth, jwt, middleware]status: complete---
## Authentication Flow Analysis
### Entry Point`src/api/auth/login.ts:24` - POST /api/auth/login handler
### Data Flow1. Request body validated against LoginSchema (Zod)2. User lookup via `src/db/users.ts:findByEmail()`3. Password comparison via bcrypt4. JWT signed with RS256, 15-minute expiry5. Refresh token stored in HttpOnly cookie
### Dependencies- `jsonwebtoken` for JWT operations- `bcrypt` for password hashing- `src/lib/cookies.ts` for secure cookie handlingThese documents accumulate in research/docs/ with a YYYY-MM-DD-topic.md naming convention. When an agent starts a new session, it can query this knowledge base through the codebase-research-locator sub-agent instead of re-analyzing the entire codebase.
This is persistent memory that survives sessions. The output of one session becomes the input for the next — the flywheel that every team independently converged on.
Structured Execution: The Atomic Flywheel
Atomic enforces a four-phase workflow with explicit human-in-the-loop gates:
Each transition is a human checkpoint. You review research before spec generation. You review the spec before implementation. This is the same principle as Horthy’s RPI workflow and Huntley’s separation of planning mode from building mode.
The key: reviewing a plan is faster than reviewing code. When the spec is right, implementation follows reliably. When the spec is wrong, you catch it before 500 lines of code get generated in the wrong direction.
Ralph: Graph-Based Autonomous Execution
The /ralph command is where Atomic’s execution engine does the heavy lifting. Rather than a simple orchestration loop, Ralph is built on a compiled graph execution engine — a custom DAG runner that expresses the entire autonomous workflow as a typed, multi-phase graph constructed through a declarative builder API.
The workflow compiles into three phases:
- Task Decomposition: A read-only planner sub-agent decomposes the spec into structured tasks. Parsing is handled deterministically by a tool node — no LLM reasoning wasted on extraction.
- Worker Loop: The graph executor iterates over a select-and-dispatch cycle. Task readiness is determined programmatically based on dependency satisfaction, and all ready tasks are dispatched concurrently as parallel worker sub-agents — each implementing exactly one task. The loop exits when all tasks are complete, errored, or no actionable tasks remain.
- Review & Fix: A reviewer sub-agent audits the completed work. If issues are found, the graph conditionally routes to a debugger sub-agent that applies corrections.
The task format remains minimal:
[ { "id": "#1", "content": "Add JWT middleware", "status": "pending", "activeForm": "Adding JWT middleware", "blockedBy": [] }, { "id": "#2", "content": "Create login endpoint", "status": "pending", "activeForm": "Creating login endpoint", "blockedBy": ["#1"] }, { "id": "#3", "content": "Add refresh token flow", "status": "pending", "activeForm": "Adding refresh token flow", "blockedBy": ["#1"] }, { "id": "#4", "content": "Integration tests", "status": "pending", "activeForm": "Writing integration tests", "blockedBy": ["#2", "#3"] }]State management is designed for concurrency — the graph engine uses annotation-based reducers so that results from parallel workers merge cleanly without overwriting each other, and a stable identity system ensures correct result-to-task mapping even when agents complete out of order.
Performance is a first-class concern in the execution loop. Task status updates reach the TUI before agents spawn, giving immediate visual feedback. Persistence is debounced to avoid I/O contention during rapid parallel updates. The TUI renders a live tree of agent statuses streamed from the execution engine in real time.
This is the same principle as Carlini’s parallel agent architecture (multiple agents working on independent tasks simultaneously), but with explicit dependency tracking, a typed graph engine, and a reviewer gate before completion. The graph builder expresses workflows declaratively — including loops, conditionals, parallel branches, and human-in-the-loop pauses — while the executor handles traversal, immutable state management, retry with backoff, and checkpointing for resumption.
Agent-Agnostic: One Harness, Multiple Engines
Atomic abstracts across coding agents through a unified client interface that normalizes session management, streaming, and event handling across all three SDKs. Underneath, an event-driven architecture ensures that workflow events, agent lifecycle changes, and UI updates all flow through a single resilient pipeline — regardless of which provider is running.
┌─────────────────────────────────────────┐│ Atomic CLI ││ (Workflows, Sub-agents, Graph Engine) │├─────────────────────────────────────────┤│ Event-Driven Streaming Layer │├─────────────────────────────────────────┤│ Unified Client Interface │├────────────┬────────────┬───────────────┤│ Claude SDK │ OpenCode │ Copilot SDK ││ │ SDK │ │└────────────┴────────────┴───────────────┘Startup performance is optimized aggressively — only the code paths you actually use get loaded, initialization steps run concurrently rather than sequentially, and background operations never block the CLI. The runtime compiles to a single native binary for minimal cold-start overhead.
Your agent of choice is the engine. Atomic is the harness. The workflows, sub-agents, research system, and graph execution engine work identically regardless of which engine you’re running underneath.
The Infrastructure Principle
Addy Osmani nailed it: “The rise of AI coding doesn’t replace the craft of software engineering — it raises the bar for it.”
This is the same principle that applies to every production system. You wouldn’t deploy a web service without CI/CD, monitoring, and rollback mechanisms. Coding agents are production systems now. They need the same infrastructure discipline.
Harness engineering isn’t a temporary workaround while we wait for better models. Better models make it more important — because they unlock more autonomy, and more autonomy demands better guardrails. Carlini saw this firsthand: Opus 4.5 could produce a functional compiler. Opus 4.6 could compile the Linux kernel. But only with a redesigned harness for each capability level.
The four pillars — context architecture, agent specialization, persistent memory, structured execution — aren’t Atomic-specific patterns. They’re converging best practices that every serious agentic engineering team has arrived at independently. For a deeper look at how these pillars manifest as a layered architecture of tools, hooks, skills, and subagents, see our post on the rise of the meta-framework layer. Atomic just packages them into an open-source CLI you can install today.
Open source. Local-first. No cloud dependency.
References
- OpenAI Harness Engineering: openai.com/index/harness-engineering
- Anthropic C Compiler: anthropic.com/engineering/building-c-compiler
- Vasilopoulos (2026), “Codified Context”: arxiv.org/abs/2602.20478
- Dex Horthy, “Harness Engineering”: humanlayer/advanced-context-engineering-for-coding-agents
- Geoffrey Huntley, Ralph Methodology: ghuntley.com/ralph
- Addy Osmani, Agentic Engineering: addyosmani.com/blog/agentic-engineering
- Charlie Guo, “The Emerging Harness Engineering Playbook”: ignorance.ai/p/the-emerging-harness-engineering
- Martin Fowler, Harness Engineering: martinfowler.com/articles/exploring-gen-ai/harness-engineering.html
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.