Building Self-Improving Coding Agents: How Factory's Signals Pipeline Closes the Feedback Loop
The Observability Gap in Coding Agents
Every team shipping a coding agent today has the basics covered. You know if tests pass. You know if code compiles. You know if the agent produced a syntactically valid diff. But there’s an entire layer of user experience that traditional telemetry misses.
You don’t know if your agent is frustrating users in ways they won’t bother reporting. You don’t know which failure modes drive abandonment versus which ones users recover from. And you don’t know what patterns of struggle exist beneath the surface of your existing metrics.
Factory recently published how their coding agent fixes itself—not in theory, but in production. Their system, called Signals, auto-resolved 73% of issues in under 4 hours. It’s a closed-loop pipeline that captures user friction at scale, without compromising privacy, and then automatically implements and validates fixes. This is the infrastructure that’s actually missing from the coding agent ecosystem, and it’s worth understanding in detail.
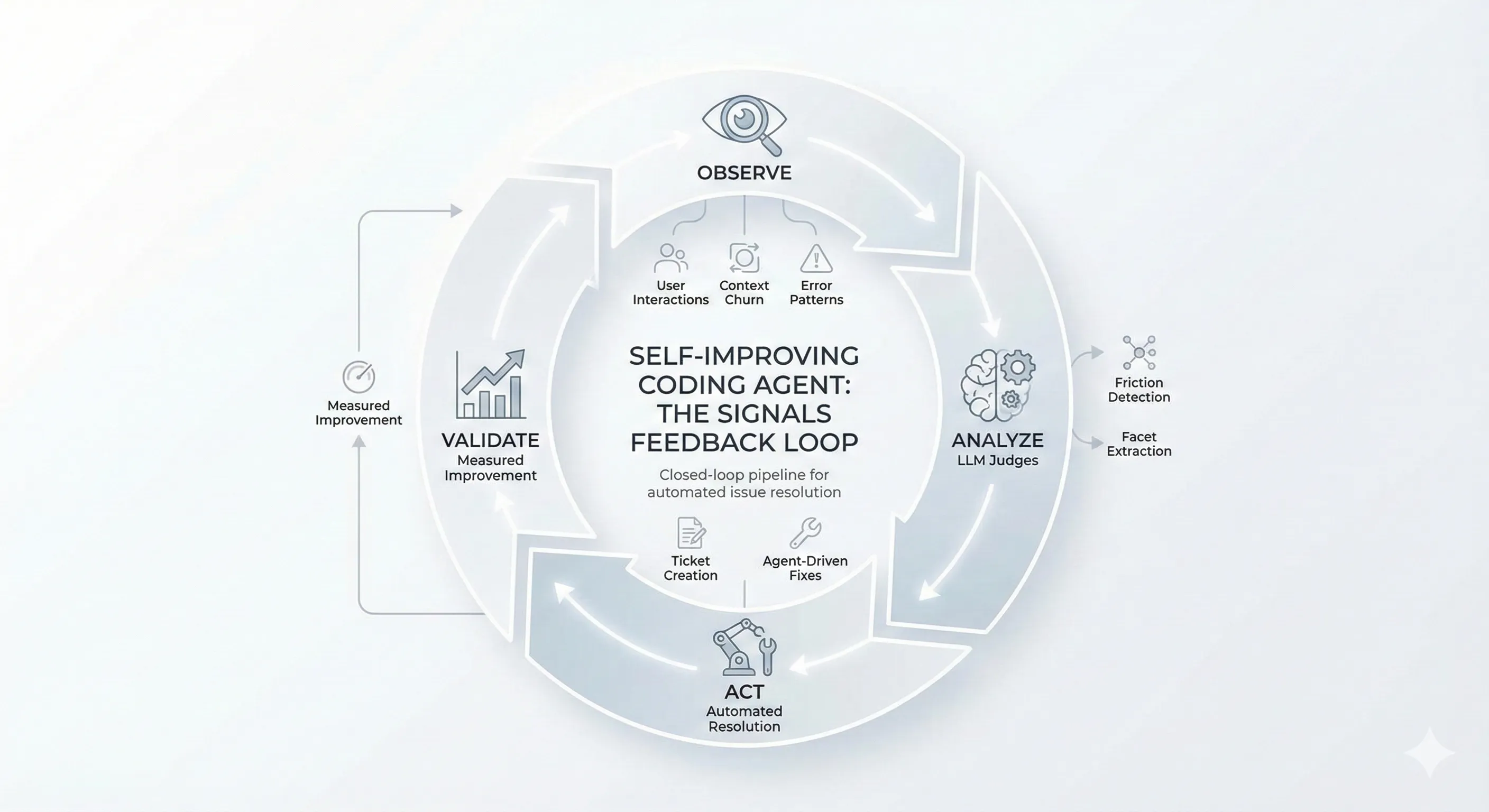
How the Signals Pipeline Works
The architecture is a daily batch pipeline with five stages: session ingestion, dual-pass LLM analysis, pattern aggregation, automated ticket creation, and agent-driven resolution.
Stage 1: Session Ingestion and Filtering
Sessions are stored in BigQuery. The daily batch job queries the past 24 hours and filters to sessions with at least 30 agentic steps, ensuring only meaningful interactions get analyzed. Short or trivial sessions are discarded upfront, keeping analysis costs manageable.
Stage 2: Dual-Pass LLM Analysis
Filtered sessions are sent to OpenAI’s batch API with dynamically adjusted token budgets. The 24-hour processing window of the batch API is a feature here, not a limitation. Signals is looking for patterns, not real-time alerts, and batching provides a 50% cost reduction over synchronous API calls.
Each session undergoes two parallel analysis passes:
Facet extraction decomposes each session into structured metadata: programming languages used, user intent, tool confirmation counts, success vs. abandonment status, and frameworks involved. Critically, the facet schema evolves autonomously through semantic clustering. When embeddings of session summaries reveal groups that don’t map to existing facets, the system proposes new dimensions.
Friction detection identifies seven categories of user struggle:
| Friction Type | High Severity % | What It Captures |
|---|---|---|
| Abandoned tool flows | 48% | Rejected or cancelled tool calls |
| Repeated rephrasing | 42% | 3+ consecutive rephrasings of the same request |
| Context churn | 38% | Repeated file add/remove cycles |
| Error events | 35% | Standard execution errors |
| Escalation tone markers | 28% | Language like “broken” or “frustrating” |
| Backtracking patterns | 22% | “Undo” or “revert” language |
| Platform confusion | 15% | Confusion about the agent’s own features |
Each friction moment receives a severity rating and an abstracted citation—something like “user expressed frustration after third failed tool call”—never raw quotes or PII.
Stage 3: Automated Ticket Creation
When friction patterns cross a statistical threshold across enough sessions, Signals automatically files a Linear ticket. The ticket includes the friction type, severity, frequency, and abstracted examples. One batch of 1,946 sessions produced 34 friction-affected sessions with 89 total friction points (2.6 per affected session), broken down as 12 high, 41 medium, and 36 low severity.
Stage 4: Agent-Driven Resolution
Factory’s Droid agent self-assigns the Linear ticket, implements the fix in code, creates a pull request, and self-reviews. There’s exactly one human approval gate before merge. After deployment, Signals automatically tracks whether the friction pattern changes in subsequent sessions, closing the loop without anyone having to read before-and-after conversations.
The Three Metrics That Matter Most
The behavioral data from Signals produced three findings that should change how you think about agent quality.
Context Churn: The Leading Indicator
Context churn, where users repeatedly add and remove the same file from context, turned out to be the strongest predictor of eventual frustration. This pattern appears minutes before more obvious signals like tone escalation, making it a leading indicator rather than a lagging one.
The implication for agent builders: if you can detect context churn in real-time, you can intervene proactively. The user is telling you through their behavior that the agent isn’t reading or using the file correctly—before they tell you with words.
// Pseudocode: detecting context churn in an agent sessioninterface ContextEvent { type: "add" | "remove"; filePath: string; timestamp: number;}
function detectContextChurn( events: ContextEvent[], windowMs: number = 120_000, // 2-minute window threshold: number = 3 // add/remove cycles): boolean { const fileToggleCounts = new Map<string, number>();
for (const event of events) { const recentEvents = events.filter( (e) => e.filePath === event.filePath && Math.abs(e.timestamp - event.timestamp) < windowMs );
// Count add→remove→add cycles for this file let cycles = 0; for (let i = 0; i < recentEvents.length - 1; i++) { if ( recentEvents[i].type === "add" && recentEvents[i + 1].type === "remove" ) { cycles++; } } fileToggleCounts.set( event.filePath, Math.max(fileToggleCounts.get(event.filePath) ?? 0, cycles) ); }
return [...fileToggleCounts.values()].some((count) => count >= threshold);}Rephrasing Cascades: The Compounding Failure
Three consecutive rephrasings of the same request correlate with approximately a 40% chance of a fourth. By the time a user hits 5+ rephrasings, completion rates drop drastically. The cascade compounds because each failed attempt erodes the user’s model of what the agent understands.
Factory responded by implementing proactive clarification. When Droid detects potential ambiguity, it asks for clarification before the cascade starts rather than attempting and failing. After shipping this change, the “repeated rephrasing” friction rate dropped by 30% within 48 hours.
Graceful Error Recovery > Perfection
This is the counterintuitive finding: sessions that hit errors but recovered gracefully scored higher on user satisfaction than error-free sessions. Users don’t expect perfection from an agent. They expect resilience. An agent that encounters a problem, acknowledges it, and works through it builds more trust than one that never errs but also never demonstrates adaptability.
This has direct implications for how you design agent error handling:
// ❌ Fragile: silently retry and hope for the bestasync function executeToolCall(tool: string, args: unknown): Promise<Result> { try { return await callTool(tool, args); } catch { return await callTool(tool, args); // silent retry }}
// ✅ Resilient: acknowledge, adapt, explainasync function executeToolCall(tool: string, args: unknown): Promise<Result> { try { return await callTool(tool, args); } catch (error) { const diagnosis = diagnoseError(error);
// Communicate what happened and what you're doing about it emitStatus(`Hit ${diagnosis.type}. ${diagnosis.recoveryPlan}`);
// Adapt strategy based on the error const fallback = selectFallbackStrategy(tool, diagnosis); return await fallback.execute(args); }}Adopting This Pattern: A Practical Blueprint
You don’t need Factory’s scale to benefit from this approach. The core pattern of LLM-as-judge over session data with automated feedback loops is implementable with tools most teams already have access to.
1. Instrument Your Sessions
Capture structured session logs with enough granularity to detect friction patterns. At minimum, track: tool calls and their outcomes, context window changes, user message edits/rephrasings, error events and recovery paths, and session completion status.
2. Run Batch Analysis with LLM Judges
Use OpenAI’s batch API (or any model with structured output) to analyze sessions in bulk. The key design choice is abstracted citations over raw quotes. This preserves privacy while still giving your team actionable signal.
FRICTION_ANALYSIS_PROMPT = """Analyze this coding agent session for friction indicators.
For each friction moment found, provide:- type: one of [context_churn, rephrasing_cascade, abandoned_tool, error_event, tone_escalation, backtracking, platform_confusion]- severity: high | medium | low- abstracted_citation: A description of what happened WITHOUT quoting the user directly. Example: "user rephrased file search request 3 times before abandoning"
Do NOT include any direct quotes from the user.Do NOT include filenames, variable names, or code from the session.
Session data:{session_data}"""3. Close the Loop
The difference between observability and self-improvement is whether the system acts on what it finds. Connect your analysis pipeline to your issue tracker. Even without full automation, a daily digest of friction patterns, filed as tickets with severity and frequency data, transforms how your team prioritizes agent improvements.
What This Means for the Ecosystem
The ability to capture user friction at scale, without compromising privacy, and then close the loop automatically is what separates agents that improve from agents that just ship. Most teams today are flying partially blind. You know the mechanical outcomes (tests pass, code compiles) but miss the experiential layer entirely.
Factory’s Signals is the first public implementation I’ve seen that closes the full loop from friction detection to automated resolution to validated improvement. The specific metrics (context churn as a leading indicator, rephrasing cascade thresholds, and resilience over perfection) aren’t just Factory-specific findings. They’re behavioral patterns that likely apply to any coding agent with context management and iterative prompting.
If you’re building or operating coding agents seriously, production observability that goes beyond pass/fail isn’t optional. It’s the infrastructure layer that determines whether your agent gets better over time or just accumulates undiscovered failure modes. For the academic research perspective on how agents can learn continuously without retraining, see our post on continuous self-learning in AI agents.
Key Takeaways
- Context churn (users repeatedly adding/removing files from context) is the strongest leading indicator of user frustration, often appearing minutes before escalation signals.
- Rephrasing cascades compound: 3 consecutive rephrasings correlate with a ~40% chance of another. At 5+, completion rates collapse.
- Sessions with graceful error recovery score higher on satisfaction than error-free sessions. Resilience beats flawlessness.
- Factory’s closed-loop pipeline (LLM judges → auto-filed tickets → agent-implemented fixes → automated re-measurement) represents a pattern every team shipping coding agents should study.
Sources
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.