The New SDLC: A Practical Guide to Agentic Engineering
The Shift Is Here
The creator of Claude Code hasn’t written a line of code by hand in over two months. He shipped 22 pull requests in a single day, each one 100% written by AI. Across Anthropic, “pretty much 100%” of code is now AI-generated.
This isn’t a prediction. It’s the current state at the company building one of the most widely used coding agents.
At the same time, one of the most respected AI researchers in the field has admitted his manual coding ability is “atrophying.” In the span of four weeks, he went from 80% manual coding to 80% agent-driven. This is real agentic engineering — the successor to vibe coding, but with oversight and scrutiny.
The profession is being refactored. The title “software engineer” may evolve into “builder” or “product manager” or persist as a vestigial label. But the people behind these tools are clear on one thing: engineers are more important than ever. Someone still has to decide what to build, talk to customers, write the specs, and verify the output.
The question isn’t whether this shift is happening. It’s whether you have a workflow that works with it instead of against it.
From Writing Code to Designing Systems
The barrier to writing code has dropped so far that coding itself is no longer the scarce skill. At Anthropic, every function codes — PMs, designers, engineering managers, finance. The value has migrated upstream: knowing what to build, why it matters, and how the system should work.
As Boris Cherny, creator of Claude Code, put it: the job now is to build for the user, then build for the model. First, deeply understand the user’s problem. Then, translate that understanding into specifications clear enough for an agent to execute. The two-step framing captures the entire shift — product thinking comes first, agent orchestration comes second.
This is the builder vs. coder split. Two camps are emerging:
| Coder | Builder | |
|---|---|---|
| Focus | Writing syntax, memorizing APIs | Requirements, architecture, system design |
| Core skill | Implementation speed | Specification clarity |
| AI relationship | Competing with the model | Directing the model |
| Output | Lines of code | Working systems |
The declining skills: typing syntax, memorizing APIs, writing boilerplate. The ascending skills: requirements gathering, system architecture, code review, and effective prompting — programming in English.
What “Generalist Engineer” Means in Practice
The hiring pattern at companies building AI tools has shifted toward generalists. Not because deep technical expertise has lost its value — it hasn’t — but because the role now demands wearing every hat. Engineers are simultaneously the PM defining requirements, the designer shaping the experience, the user researcher understanding the problem, and the developer verifying the implementation. Agents handle the raw coding, which means the engineer’s job expands to cover the full surface area of building a product:
- User research: Talking to customers, identifying pain points, understanding the real problem before writing a single spec
- Product sense: Translating user problems into clear requirements and prioritizing what to build next
- Design thinking: Shaping how the system feels to use, not just how it works internally
- System design: Knowing how components fit together, even if you don’t implement each one by hand
- Verification ability: Reading and reviewing AI-generated code with the same rigor you’d apply to a junior engineer’s PR
- Communication: The person who communicates the best will be the most valuable programmer. The new scarce skill is writing specifications that fully capture your intent.
The New SDLC: Spec-Driven Development
Vibe coding — asking an AI to build something from a loose description — works for prototypes. It falls apart for production systems. The reason is straightforward: AI-assisted development dramatically raises the cost of ambiguity. When an agent is involved, unclear intent doesn’t just slow things down. It actively creates risk.
Spec-driven development (SDD) is the methodology that’s emerging to solve this. It separates the design and implementation phases, using structured specifications as the contract between human intent and agent execution.
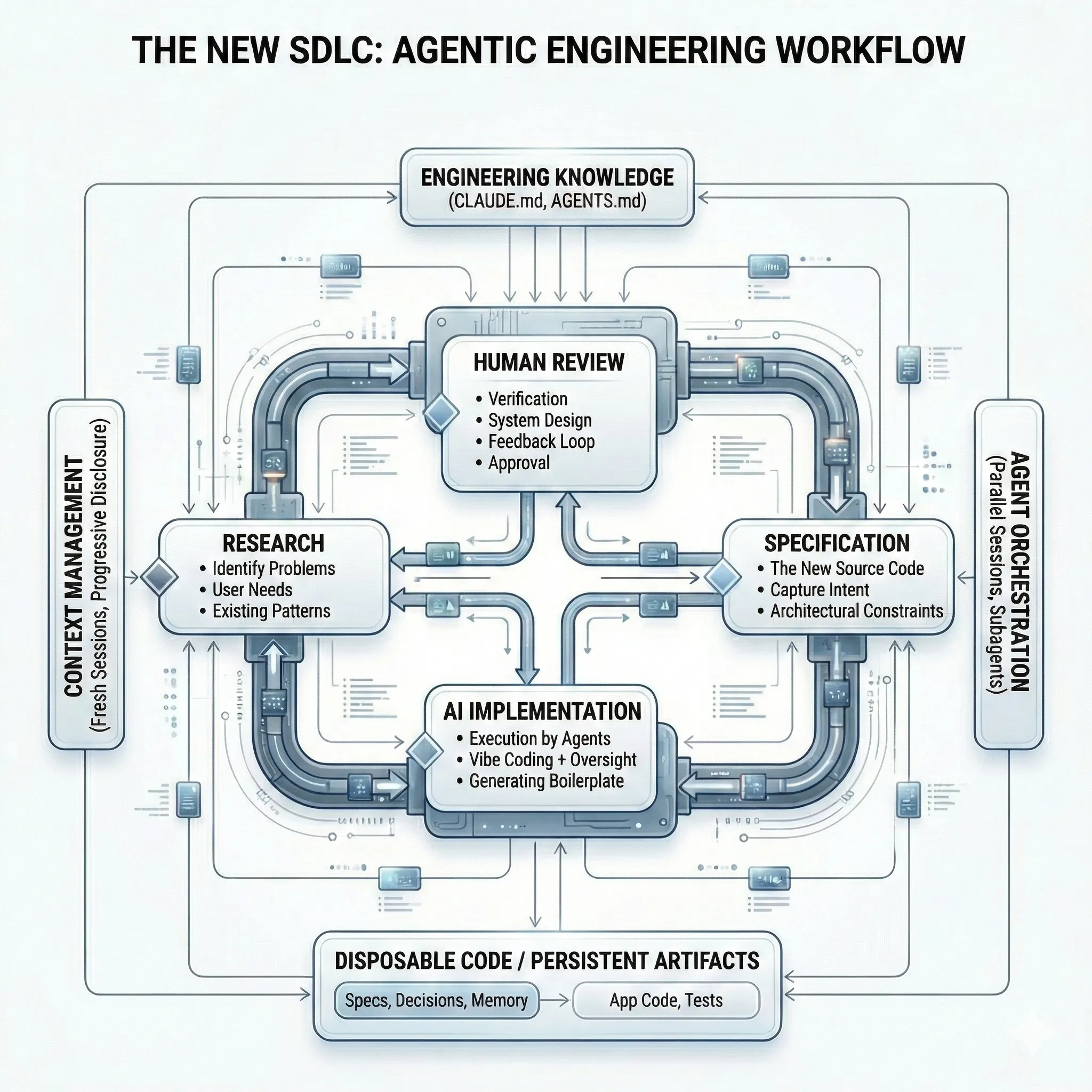
To see what this looks like in practice, consider Atomic — an open-source agent orchestration layer that implements the full spec-driven workflow end to end. Atomic’s core loop is: Research → Specify → Implement → Ship. Each phase produces a persistent artifact, and at every transition the human reviews before the agent proceeds.
The Core Workflow
Here’s how a feature moves through the pipeline in Atomic. Each phase produces an artifact that persists and compounds:
Phase 1: Research (/research-codebase) — Before writing a spec, you need to understand the codebase. Atomic spawns a fleet of specialized sub-agents in parallel — a codebase-locator to find relevant files, a codebase-analyzer to understand how specific code works, a codebase-pattern-finder to surface existing conventions, and a codebase-online-researcher to pull in external documentation. The findings are synthesized into a research document saved to research/docs/. You review the agent’s understanding before proceeding. This step replaces the informal “read the code for an hour” phase with structured, reusable knowledge.
Phase 2: Specify (/create-spec) — The research feeds into a technical specification — an RFC-style document with an executive summary, goals and non-goals, proposed architecture (with Mermaid diagrams), detailed design, alternatives considered, and open questions. This is the contract between your intent and the agent’s execution. You review and iterate on it. The spec is explicit enough that a fresh agent session can implement from it without any conversation history.
Phase 3: Implement (/ralph) — This is where Atomic’s autonomous execution engine takes over. Ralph reads the spec and automatically decomposes it into an ordered list of discrete tasks, each with verification criteria and identified dependencies. Then it spawns a worker sub-agent for the highest-priority pending task and loops: implement, test, validate, advance. Each worker follows test-driven development and SOLID principles by default. If a worker completes a task, Ralph picks up the next one. The loop continues until all tasks are done, a maximum iteration limit is hit, or you interrupt with Ctrl+C. Multiple Ralph sessions can run concurrently on different features.
Phase 4: Review and Ship (/gh-create-pr) — A fresh agent session reviews the implementation against the spec. This is the writer/reviewer separation — the reviewing agent has no bias toward the code it’s evaluating. Once approved, the PR is created and shipped.
Why This Works
The quality of AI output directly correlates with specification detail. Vague prompts produce vague code. Atomic enforces this by making you produce a research document and a spec before any code gets written. By the time an agent starts implementing, the ambiguity has already been resolved.
The multi-agent architecture matters too. Each sub-agent operates in a clean context window with a focused task. The research agents don’t carry implementation context. The implementation workers don’t carry research context. This prevents the context bloat that degrades agent performance in long sessions.
The spec also serves a second purpose: it’s the artifact that persists. When applications get rewritten (and they will), the spec carries forward. Atomic’s flywheel model captures this explicitly: Research → Specs → Execution → Outcomes → Specs. The code is disposable. The knowledge is not.
Knowledge-First Architecture
Here’s a pattern that’s becoming common at the frontier: Claude Code gets rewritten roughly every six months. None of the original code remains. Applications are treated as disposable expressions of the underlying knowledge.
This isn’t carelessness. It’s a deliberate strategy built around a core insight: when AI can regenerate code from specifications, the cost of rewriting drops below the cost of maintaining legacy implementations. The gaps you discover in design assumptions are cheaper to rebuild around than to retrofit.
The Practical Rule
When an implementation isn’t working after 1-2 days of agent iteration, throw it away and restart from scratch. The knowledge you gained from the failed attempt (the spec gaps, the edge cases, the architectural misses) makes the second attempt faster and better than any amount of patching would.
This means your investment should flow into the artifacts that survive rewrites:
- Specifications that capture intent, constraints, and acceptance criteria
- Architectural decision records that document the why behind choices
- Agent instructions (CLAUDE.md / AGENTS.md) that encode project-specific knowledge, conventions, and mistakes to avoid
- Research notes that preserve discoveries across sessions
CLAUDE.md / AGENTS.md: Your Codebase’s Constitution
CLAUDE.md (for Claude Code) and AGENTS.md (an open standard adopted by 20,000+ repositories) are markdown files that sit in your repo and brief AI agents at the start of every session. Think of them as a README for agents. For a hands-on look at how these files work in practice at scale, see our post on shipping 100k LOC with AI coding infrastructure.
Best practices for these files:
- Define the WHY, WHAT, and HOW. Give the agent a map of the codebase. Tell it how to build, test, and verify. Include per-file commands, not full builds.
- Keep it concise. Every token gets loaded every session. The ideal file is as small as possible while covering what matters. Currently, Anthropic’s own CLAUDE.md is 2.5k tokens.
- Use progressive disclosure. Don’t dump everything. Tell the agent how to find important information so it loads context only when needed.
- Log mistakes. Tag learnings from PRs into CLAUDE.md so the agent improves over time. Knowledge from code reviews should feed back into the instruction file.
- Maintain cross-tool compatibility. Symlink CLAUDE.md and AGENTS.md if your team uses multiple AI coding tools.
A Practical Guide: How to Work This Way Today
Here’s a concrete workflow you can adopt incrementally. Start with Step 1 and add steps as your comfort grows.
Step 1: Set Up Agent Instructions
Create a CLAUDE.md (or AGENTS.md) in your repository root. Tools like Atomic can generate these files automatically — its /init command analyzes your codebase and produces a CLAUDE.md/AGENTS.md following best practices learned from Anthropic, so you don’t have to start from a blank page. Whether you generate or handwrite it, the structure should look like:
# Project Overview[What the project does, its architecture, key patterns]
# Build & Test[Per-file commands for type checking, testing, linting]
# Conventions[Naming, file structure, patterns to follow]
# Known Issues[Common mistakes, gotchas, things the agent gets wrong]Step 2: Adopt Spec-Driven Workflows
Before any non-trivial feature, follow the Research → Specify → Implement pipeline. Each phase produces an artifact you review before the agent proceeds:
-
Research the codebase. Have the agent analyze the relevant code, surface existing patterns, and pull in external documentation. Save the findings to a research document (e.g.,
research/docs/). Review the agent’s understanding before moving on. This replaces the informal “read the code for an hour” phase with structured, reusable knowledge. -
Write a spec. Feed the research into a technical specification — an RFC-style document with an executive summary, goals and non-goals, proposed architecture, detailed design, alternatives considered, and open questions. This is the contract between your intent and the agent’s execution. Iterate on it until a fresh agent session could implement from it without any conversation history.
-
Decompose into tasks and implement. The agent reads the spec and breaks it into discrete tasks with verification criteria and dependencies. Each task is implemented, tested, and validated before the next one begins. The human reviews the final output against the spec, not against a vague mental model.
The key discipline: no code gets written until the research document and spec exist. By the time implementation starts, the ambiguity has already been resolved.
Step 3: Manage Context Deliberately
Context bloat is the primary failure mode of agentic coding. The agent’s performance degrades as the conversation history grows. Combat this with:
- Fresh sessions per task. Clear context between tasks. Pass state via a condensed summary file, not conversation history.
- Atomic changes. One feature per session. If a feature requires multiple sessions, it’s too large.
- Subagents for specialized work. Delegate research, code review, and security analysis to isolated subagents with their own context windows.
Step 4: Use the Writer/Reviewer Pattern
Never review code in the same session that wrote it. The agent will be biased toward its own output. Instead:
- Writer session: Implements the feature based on the spec
- Reviewer session: Opens a fresh context, reviews the code against the spec, flags issues
- Fix session: Addresses review feedback
This mirrors how top teams operate — at Anthropic, each PR gets reviewed by a fresh Claude instance.
Step 5: Scale to Parallel Agent Sessions
Once you’re comfortable with single-agent workflows, parallelize:
- Run multiple agent instances simultaneously (5+ is common at the frontier)
- Use git worktrees to prevent file conflicts between parallel sessions
- Assign each instance a different task from your task list
- Bake in verifiability through tests or contracts so you’re not as bottlenecked by review
Step 6: Automate the Safety Net
The quality concern is real — models make wrong assumptions, bloat abstractions, and don’t clean up dead code. Build deterministic guardrails:
- Pre-commit hooks: Linting, formatting, type checking, secret scanning
- CI/CD integration: Run Claude Code in headless mode (
-pflag) for automated tasks like issue triage or boilerplate generation - Test-first requirements: Include test specifications in your task definitions. No task is complete without passing tests.
- Coverage as a guardrail: Use code coverage tools to verify that AI-generated tests actually exercise the code they claim to test. Coverage alone doesn’t guarantee quality, but lack of coverage guarantees blind spots. A practical way to decide what meaningful coverage looks like for your codebase: ask the model to identify the hot paths — the 15-20% of your code where 80% of the logic lives. These are the functions with the most branching, the deepest call chains, and the highest blast radius if they break. Focus your coverage requirements there first, and expand outward. This turns coverage from a vanity metric into a targeted quality signal.
What to Watch For
This transition has real failure modes. Be aware of:
The slopacolypse. Low-quality AI-generated code that “mostly works” will flood repositories. Counter this with rigorous review, strong specs, and deterministic quality gates. AI reviewing AI is part of the answer, but human oversight remains essential.
Specification gap. Writing good specs is a skill most teams haven’t practiced since the waterfall era. Organizations will discover their teams don’t know how to write specs that agents can execute effectively. This is a real training need.
Over-formalization. Don’t let spec-driven development become waterfall 2.0. Specs should be living documents that evolve as you learn. The iterative cycle between spec and implementation is what makes this work — not rigid upfront planning.
Stale assumptions about model capabilities. Just because last month’s model couldn’t handle a task doesn’t mean this month’s can’t. Model capabilities are improving rapidly, and engineers who lock in assumptions about what AI “can’t do” will fall behind. Continuously re-test tasks you’ve been doing manually — the moment you stop updating your mental model of what’s possible, you start leaving leverage on the table. Let go of the pride of doing it yourself. Your ability to thrive in this new world depends on your willingness to adapt.
Bottom Line
The SDLC is being restructured around a new division of labor. Humans own the decisions: what to build, why, and how the system should work. Agents own the execution: writing the code, running the tests, generating the boilerplate.
The engineers who thrive in this paradigm won’t be the fastest coders. They’ll be the clearest thinkers — the ones who can write specifications that capture intent, design systems that scale, and verify output with rigor.
The practical starting point is straightforward: add a CLAUDE.md to your repo, write a spec before your next feature, and use a fresh agent session to review what the first session wrote. Build from there.
The old way of building is becoming obsolete in real time. The new way rewards the skills that made great engineers great in the first place: clear thinking, system design, and knowing what to build next.
Key Takeaways
- The role is shifting, not disappearing. Engineers are becoming system designers and agent orchestrators. The value is in knowing what to build, why, and how to verify the output.
- Specs are the new source code. In an era of disposable implementations, specifications, architectural decisions, and project memory are the artifacts that persist. Code is just the current expression.
- Spec-driven development replaces vibe coding. Structure your work as Research -> Plan (Specs) -> Tasks -> Implement. The quality of your spec determines the quality of your output.
- Context management is the new memory management. Fresh sessions, progressive disclosure, and atomic tasks prevent the context bloat that kills agent performance.
- Adopt incrementally. Start with CLAUDE.md/AGENTS.md, add spec-driven workflows, then scale to parallel agent sessions. You don’t need to change everything at once.
References
- Boris Cherny on YC’s Lightcone Podcast (Feb 17, 2026)
- Anthropic’s Claude Code Creator Predicts Software Engineering Title Will Start to ‘Go Away’
- Top Engineers at Anthropic, OpenAI Say AI Now Writes 100% of Their Code - Fortune
- Karpathy: “I’ve Never Felt This Much Behind as a Programmer”
- Vibe Coding Is Passe - Karpathy on Agentic Engineering - The New Stack
- Spec-Driven Development: Unpacking 2025’s Key New Practice - Thoughtworks
- AGENTS.md - Open Format for Guiding Coding Agents
- GitHub Spec-Kit: Toolkit for Spec-Driven Development
- How to Write a Good Spec for AI Agents - Addy Osmani
- Claude Code Best Practices
- Eight Trends Defining How Software Gets Built in 2026 - Anthropic
- Atomic: Agent Orchestration Layer
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.