If Your Claws Aren't Out, You're Already Falling Behind
Key Takeaways
- The Claws layer is the bottleneck, not model capability. Karpathy named the orchestration, scheduling, context, and persistence infrastructure that sits on top of LLM agents. Without it, you’re using frontier models at a fraction of their potential.
- Agent capability is doubling every 4 months. METR data shows the 50%-success time horizon hit 870 hours with Opus 4.6—tasks that would take a human expert over five weeks. The curve isn’t flattening.
- Experienced users give agents more autonomy and more guardrails. Anthropic’s data shows power users auto-approve 40% of actions (double beginners) while also interrupting at nearly double the rate. They steer, not spectate.
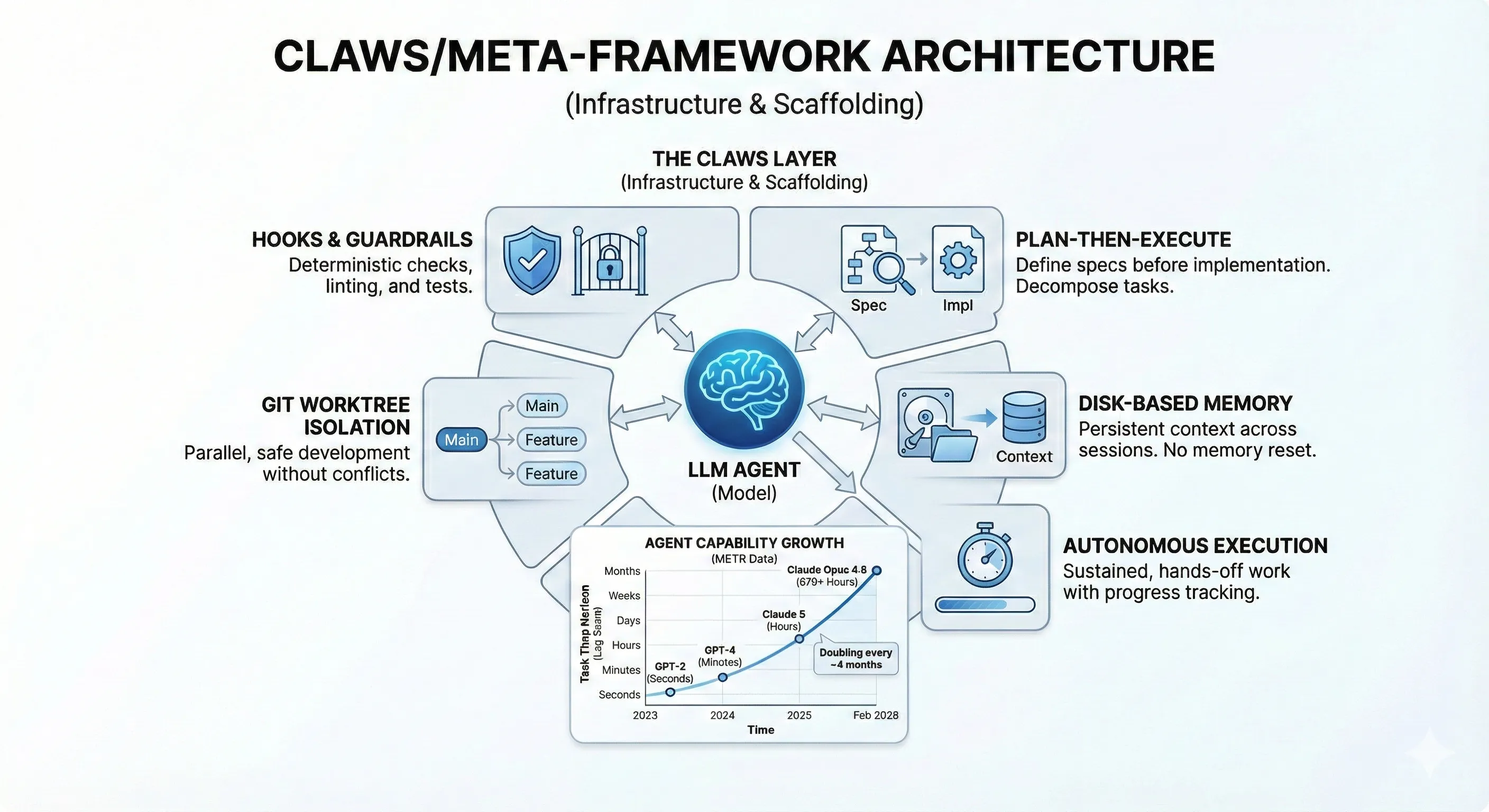
- Five primitives make sustained autonomy work: hooks and guardrails, plan-then-execute, disk-based memory, autonomous execution sessions, and git worktree isolation. These are buildable today.
- Every month without this layer widens the gap between what your agents could do and what they actually do.
Most engineers are using AI coding agents at a fraction of their potential. There’s an architectural layer on top of these agents—Karpathy just named it “Claws”—that turns agents from interactive assistants into autonomous systems that run for hours. “A new layer on top of LLM agents, taking the orchestration, scheduling, context, tool calls and a kind of persistence to a next level.” The engineers who build this layer are shipping features overnight.
The numbers are higher than most people think
Anthropic published research on agent autonomy. The headline number: the 99.9th percentile for autonomous agent turn duration—the longest continuous stretches of uninterrupted agent work—nearly doubled, from under 25 minutes to over 45 minutes between October 2025 and January 2026.
Most engineers look at that 45-minute number and think that’s the upper bound. It’s not.
When I’m working on complex features—multi-file implementations, large refactors, anything that touches several parts of the codebase—I regularly run sessions that go 75 minutes. I’ve run overnight sessions where agents implement features across dozens of files, run tests, fix failures, and iterate until done. The difference isn’t the model. It’s the infrastructure around it.
The more interesting finding from Anthropic’s data: experienced users (750+ sessions) auto-approve agent actions 40% of the time—double the rate of beginners. But they also interrupt at nearly double the rate: 9% versus 5%. They’re not hands-off. They’re not reckless. They’re steering while giving the agent more room to execute.
That’s someone working with a system, not someone watching a demo.
Human interventions per session dropped from 5.4 to 3.3 between August and December. Not because users stopped caring—because the combination of better models and better scaffolding made fewer interventions necessary. The success rate on challenging tasks doubled in the same period.
The right takeaway isn’t “sessions got longer.” It’s that the bottleneck shifted from model capability to the infrastructure around the model.
Agent capability is doubling every four months
METR—the research nonprofit that measures AI task-completion ability—tracks what they call the “time horizon”: the task duration (measured by human expert completion time) at which an AI agent succeeds with a given reliability. Their latest data is worth looking at closely.
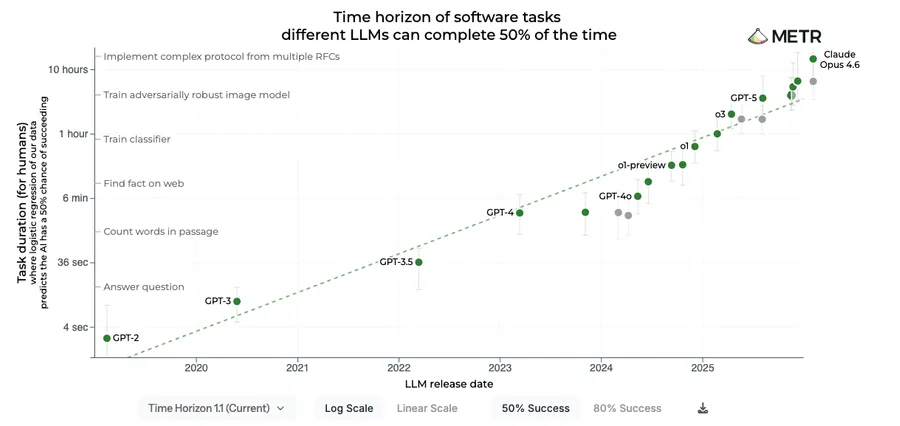
Source: METR — Time Horizon of Software Tasks Different LLMs Can Complete 50% of the Time, February 2026
The trend line is exponential. The 50%-success time horizon—the task duration where an agent succeeds half the time—is doubling roughly every 4 months. Claude Opus 4.6 now sits at an 870-hour time horizon: tasks that would take a human expert over five weeks of continuous work. Six months ago, the frontier was under two weeks. In half a year, the complexity of tasks agents can handle more than tripled.
The 80%-success time horizon tells a similar story. Opus 4.6 hits 63 hours at 80% reliability—tasks taking a human expert nearly three full work days, completed reliably eight times out of ten.
This curve isn’t flattening. And at every point on it, the scaffolding around the model—not the model itself—is what becomes the limiting factor.
Enter Claws: the layer most engineers are missing
Karpathy’s framing is clear. Claws are “a new layer on top of LLM agents” handling orchestration, scheduling, context management, tool calls, and persistence. This isn’t about prompting better. It’s about building infrastructure that lets agents operate at the capability level the models already support.
The models can already do far more than most people ask of them. What’s missing is the layer that gives them the right context, the right constraints, and the ability to persist work across sessions.
A couple months ago, I started building this exact layer—a meta-framework CLI that sits on top of coding agents to handle orchestration, session management, and context persistence. I called it Atomic and open-sourced it. (For the full backstory, see how we shipped 100k LOC in two weeks with coding agents.) Karpathy just gave the concept a name. The Claws layer he’s describing is what I’ve been building and running.
The pattern that makes autonomy work
The technical pattern isn’t complicated. It’s five primitives (which closely mirror the five architectural primitives every agent swarm rediscovers):
Hooks and guardrails. Deterministic checks that run before, during, and after agent actions. Pre-commit validation. Lint enforcement. Test suite gates. These are hard constraints that let the agent run autonomously because the guardrails catch problems the model misses. Anthropic’s data backs this up: experienced users don’t remove guardrails as they gain trust. They add more precise ones.
Plan-then-execute. The agent doesn’t go from prompt to code. It goes from research to specification to feature decomposition to atomic implementation. Each phase produces artifacts that persist—research documents, specs, feature lists, progress tracking. The specification is the decision point where you steer. The implementation is where the agent runs.
Disk-based memory. Context windows reset. Disk doesn’t. Research findings, architectural decisions, debugging discoveries—all persisted to specs/ and research/ directories that survive across sessions. When a new session starts, the agent reads existing specs to understand context. The system gets smarter over time instead of restarting from zero.
Autonomous execution sessions. This is where the primitives above come together into sustained, hands-off work. We use a dedicated executor agent—Ralph—that runs implementation sessions with active working memory. As Ralph works, it writes progress to disk: which tasks are done, which are in progress, what blockers it hit. That progress file is the session’s heartbeat. If a session is interrupted or a new one picks up the work, the agent reads the progress file and continues where it left off instead of restarting from scratch. The key is well-defined completion criteria and effective task decomposition—each task has clear acceptance criteria so the agent knows when it’s done. And the agent is smart enough to recognize when a task is too large for a single pass. When that happens, it breaks the task down further into smaller atomic units before executing, rather than attempting a monolithic implementation that’s likely to drift. This self-decomposition is what makes long autonomous sessions reliable: the agent never bites off more than it can chew.
Git worktree isolation. Parallel implementations run safely on separate branches. If an agent’s implementation fails, it doesn’t contaminate main. If two features are independent, two agents can work simultaneously without merge conflict risk. This is what turns a single-threaded workflow into a parallel pipeline.
Together, these give you a system where you make the decisions (approve specs, review feature decomposition, set guardrails) and agents handle the execution (research codebases, write implementations, run tests, create PRs). That division of labor is the whole point.
Delegating complex work to agents
Not every task needs a 75-minute autonomous session. But the complex ones—large features, multi-file refactors, anything that requires sustained context—that’s where this layer pays off. And we should be getting more comfortable delegating that kind of work.
Boris Cherny—a Claude Code developer at Anthropic—runs coding sessions spanning days. Cursor users kick off 52-hour tasks. OpenAI reports Codex working for 24+ hours autonomously. These are teams that built the scaffolding to support it.
When I’m working on something complex, I’ll run a 75-minute autonomous session. My longest overnight runs have had agents implementing features across dozens of files, running full test suites, fixing failures, and iterating until every check passes. The agent doesn’t stop because it got tired or lost context. It stops because the feature is done.
What makes this work isn’t a special model. It’s the Claws layer: hooks that catch mistakes before they compound, specifications that keep the agent aligned with the intended architecture, disk-based memory that prevents context loss, and worktree isolation that makes parallel execution safe.
Without that layer, a long session falls apart. The agent drifts from the original intent. Small errors compound into architectural problems. The context window fills with noise. You spend more time fixing the agent’s output than you would have spent writing the code yourself.
With it, the same model produces very different results. The point isn’t that every task should be a marathon. It’s that when the work is genuinely complex, you should be comfortable handing it off and letting the agent run.
You can build this today
Atomic is open source. The patterns—hooks, plan-then-execute, disk-based memory, autonomous execution sessions, git worktree isolation—are documented and ready to use.
Atomic ships with Ralph, a dedicated executor agent that runs autonomous implementation sessions out of the box. Ralph maintains active working memory by writing progress to disk as it works, so sessions can be interrupted and resumed without losing state. It decomposes features into atomic tasks with clear completion criteria—and when it encounters a task that’s too large, it breaks it down further automatically before executing. You define the spec, Ralph handles the sustained execution.
But tools alone aren’t enough. You also need to change how you work with agents. Less “prompt and watch,” more “set up the system so the agent can run.” That means:
- Invest time in specification before implementation. The 20 minutes you spend reviewing a spec saves hours of agent drift. Specs are your steering wheel.
- Build deterministic guardrails, not manual review loops. If you’re manually checking every agent action, you’ve built a system that doesn’t scale. Codify your quality standards into hooks that run automatically.
- Treat context as infrastructure, not conversation. Persistent memory isn’t a nice-to-have. It’s what separates a tool that restarts every session from a system that compounds knowledge over time.
- Decompose before you execute. Large features fail. Small, atomic features with clear acceptance criteria succeed. If an implementation requires more than one session, the feature is too big—decompose further.
I think this shift matters more than most people realize. METR’s data shows capability doubling every four months. Every month you spend without the Claws layer is a month where the gap between what your agents could do and what they actually do keeps growing.
The gap is already here
The engineers who build this layer aren’t just faster. They work differently. Most engineers prompt an agent, watch it work, fix its mistakes, and repeat—a workflow that scales linearly with their attention. Teams with proper Claws infrastructure are running parallel autonomous sessions overnight, waking up to completed features with passing tests.
Agent capability will keep doubling. The question is whether you’re building the infrastructure to actually use it.
The models are ready. The patterns exist. Start building the Claws layer.
References
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.