GPT-5.4: The Real Leap Isn't Coding
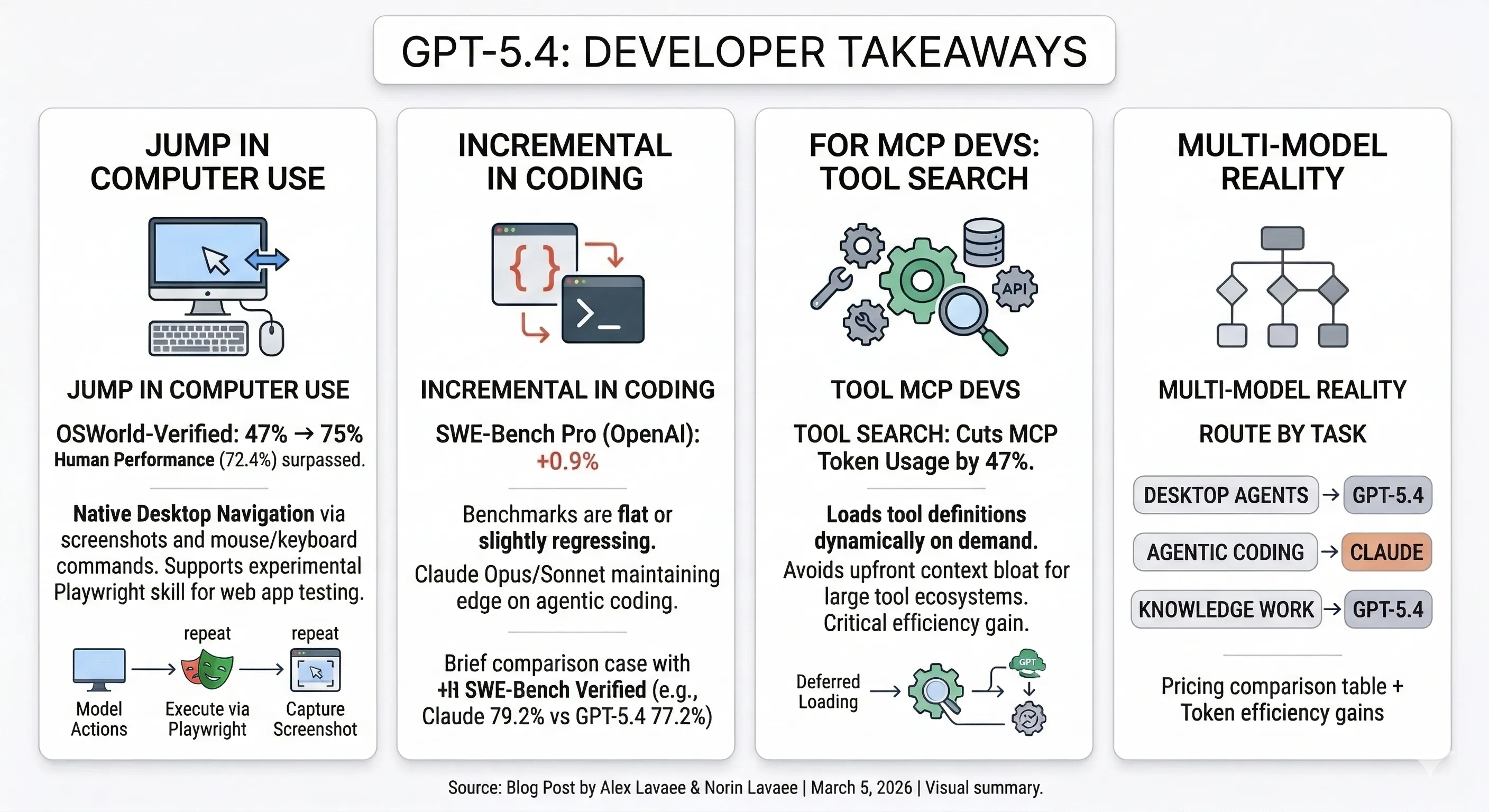
GPT-5.4 dropped today. The coding benchmarks barely moved. But three other capabilities made a significant jump — and they’re the ones that matter most for developers building agents and tool-heavy workflows.
OpenAI is calling it their “most capable and efficient frontier model for professional work.” Three variants: base, Thinking, and Pro. After spending time with the benchmarks, the API docs, and the Hacker News thread, here’s what actually changed and what it means for your stack.
Key Takeaways
- Computer use jumped from 47% to 75% on OSWorld-Verified, surpassing human performance (72.4%). GPT-5.4 is the first general-purpose OpenAI model with native desktop navigation via screenshots and mouse/keyboard commands. An experimental Playwright Interactive skill in Codex lets the model visually test web apps as it builds them.
- Coding benchmarks are flat. SWE-Bench Pro: 57.7% vs 56.8% for GPT-5.3-Codex. Terminal-Bench 2.0 actually regressed from 77.3% to 75.1%.
- Tool search cuts MCP token usage by 47% by loading tool definitions on demand instead of cramming them all into context. If you’re building with MCP, this is the feature.
- Knowledge work hits 83% across 44 professions on GDPval. Spreadsheet modeling jumped from 68.4% to 87.3%. Hallucinated claims dropped 33%.
- 1M token context window is experimentally supported in Codex, with up to 128K output tokens.
- No single best model. Claude leads on agentic coding (79.2% vs 77.2% on independent SWE-Bench Verified). GPT-5.4 leads on computer use and knowledge work. Route by task.
What the Benchmarks Actually Show
Let’s separate signal from noise. Here’s GPT-5.4 compared to its predecessors and competitors across the benchmarks that matter most for developers.
Coding: Incremental at Best
| Benchmark | GPT-5.4 | GPT-5.3-Codex | GPT-5.2 | Claude Opus 4.6 |
|---|---|---|---|---|
| SWE-Bench Pro (OpenAI) | 57.7% | 56.8% | 55.6% | — |
| SWE-Bench Verified (Vals.ai) | 77.2% | — | — | 79.2% |
| Terminal-Bench 2.0 (OpenAI) | 75.1% | 77.3% | 62.2% | 65.4%* |
*Anthropic self-reported. Independent tbench.ai leaderboard shows 74.7% with Terminus-KIRA agent scaffold.
SWE-Bench Pro moved less than one percentage point from GPT-5.3-Codex. Terminal-Bench regressed. On the independently-measured SWE-Bench Verified (Vals.ai), Claude Opus 4.6 still leads at 79.2% vs GPT-5.4’s 77.2%.
If you’re choosing a model primarily for coding agents, this release doesn’t change the calculus.
Computer Use: The Actual Leap
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Claude Sonnet 4.6 | Human | GPT-5.2 |
|---|---|---|---|---|---|
| OSWorld-Verified | 75.0% | 72.7% | 72.5% | 72.4% | 47.3% |
| WebArena-Verified | 67.3% | — | — | — | 65.4% |
This is where GPT-5.4 genuinely stands apart. A jump from 47.3% to 75.0% on desktop navigation isn’t incremental — it’s a capability unlock. GPT-5.4 is the first general-purpose OpenAI model that can navigate real desktop environments through screenshots and mouse/keyboard actions, and it now exceeds both human performance and Claude on this benchmark.
Knowledge Work and Tool Use
| Benchmark | GPT-5.4 | Claude Opus 4.6 | GPT-5.2 |
|---|---|---|---|
| GDPval (44 occupations) | 83.0% | 78.0% | 70.9% |
| BrowseComp | 82.7% | 84.0% | 65.8% |
| Toolathlon | 54.6% | — | 46.3% |
| GPQA Diamond | 92.8% | 91.3% | 92.4% |
GDPval is the standout: GPT-5.4 matches or exceeds industry professionals in 83% of comparisons across 44 occupations. Spreadsheet modeling jumped from 68.4% to 87.3% — a real improvement for financial and analytical workflows.
Interestingly, Claude Opus 4.6 still leads on BrowseComp (web search capability), suggesting Anthropic’s search remains ahead. The competition is model-by-model, benchmark-by-benchmark — not a clean sweep for anyone.
Computer Use: How It Works in the API
GPT-5.4 is the first general-purpose model where you just pass {"type": "computer"} as a tool. The agent loop is straightforward: send a task, the model returns actions (clicks, keystrokes, scrolls), you execute them in a browser or VM, capture a screenshot, and send it back.
Here’s the agent loop with Playwright, from OpenAI’s documentation:
from openai import OpenAIimport base64
client = OpenAI()
# Initial requestresponse = client.responses.create( model="gpt-5.4", tools=[{"type": "computer"}], input="Navigate to the settings page and enable dark mode.")
# Agent loopwhile True: computer_call = next( (item for item in response.output if item.type == "computer_call"), None ) if computer_call is None: break
# Execute the model's actions in Playwright handle_computer_actions(page, computer_call.actions)
# Capture and send screenshot screenshot = page.screenshot() screenshot_base64 = base64.b64encode(screenshot).decode("utf-8")
response = client.responses.create( model="gpt-5.4", tools=[{"type": "computer"}], previous_response_id=response.id, input=[{ "type": "computer_call_output", "call_id": computer_call.call_id, "output": { "type": "computer_screenshot", "image_url": f"data:image/png;base64,{screenshot_base64}", "detail": "original" } }] )The "detail": "original" parameter is new with GPT-5.4. It preserves full image fidelity up to 10.24 megapixels (6000px max dimension), which is critical for click accuracy on dense UIs. Previous models were limited to "high" (2048px max, 2.56M pixels).
The action handler maps the model’s outputs to Playwright commands:
def handle_computer_actions(page, actions): for action in actions: match action.type: case "click": page.mouse.click(action.x, action.y, button=getattr(action, "button", "left")) case "type": page.keyboard.type(action.text) case "scroll": page.mouse.move(action.x, action.y) page.mouse.wheel(action.scrollX or 0, action.scrollY or 0) case "keypress": for key in action.keys: page.keyboard.press(" " if key == "SPACE" else key)The model returns coordinate-based actions — click with x/y, type with text, scroll with deltas, keypress with key names, plus double_click, drag, mouse_move, screenshot, and wait.
OpenAI also released an experimental Codex skill called Playwright Interactive that combines these capabilities: the model can write code, run it in a browser, visually inspect the result, and iterate — all within a single Codex session. As a demo, they built a full theme park simulation game from a single prompt, using Playwright Interactive for automated playtesting and iteration.
Tool Search: The Feature MCP Developers Need
This is arguably the most impactful feature for developers building with MCP. The problem is simple: when you connect multiple MCP servers, their combined tool definitions can consume tens of thousands of tokens before any conversation begins. That’s expensive, slow, and crowds out actual context.
Tool search solves this by deferring tool definitions. Instead of loading everything upfront, GPT-5.4 receives a lightweight list of available tools and dynamically looks up definitions only when needed.
On 250 tasks from Scale’s MCP Atlas benchmark with all 36 MCP servers enabled, tool search reduced total token usage by 47% while achieving the same accuracy. That’s real money at scale.
Here’s how to enable it in the API — mark tools as deferred, and add the tool search capability. From OpenAI’s documentation:
from openai import OpenAI
client = OpenAI()
crm_namespace = { "type": "namespace", "name": "crm", "description": "CRM tools for customer lookup and order management.", "tools": [ { "type": "function", "name": "get_customer_profile", "description": "Fetch a customer profile by customer ID.", "parameters": { "type": "object", "properties": { "customer_id": {"type": "string"}, }, "required": ["customer_id"], "additionalProperties": False, }, }, { "type": "function", "name": "list_open_orders", "description": "List open orders for a customer.", "defer_loading": True, # Definition loaded on demand "parameters": { "type": "object", "properties": { "customer_id": {"type": "string"}, }, "required": ["customer_id"], "additionalProperties": False, }, }, ],}
response = client.responses.create( model="gpt-5.4", input="List open orders for customer CUST-12345.", tools=[ crm_namespace, {"type": "tool_search"}, # Enable tool search ],)The key details: defer_loading: True on tools you want loaded on demand, and {"type": "tool_search"} in your tools array. Group deferred functions into namespaces with clear descriptions and keep each namespace under 10 functions.
Anthropic has a similar feature on the Claude Developer Platform, though the approaches differ. OpenAI’s tool search is a model-level capability built into GPT-5.4 itself. Anthropic offers regex-based and BM25-based search tools at the platform level. Independent testing from Stacklok found Anthropic’s approach leads in token efficiency (2,823 tokens per request) while OpenAI claims higher accuracy preservation on the MCP Atlas benchmark. Both solve the same core problem: context window bloat from large tool ecosystems.
The Multi-Model Reality
The Hacker News thread for GPT-5.4 captures a pattern that’s now undeniable: no single model wins everything.
“Claude tends to produce better design, but from a system understanding and architecture perspective Codex is the far better model.”
“Codex actually planned worse than Claude but coded better once the plan is set, and faster.”
One commenter captured a deeper intelligence gap between the two:
“I can tell Claude to spawn a new coding agent, and it will understand what that is, what it should be told, and what it can approximately do. Codex on the other hand will spawn an agent and then tell it to continue with the work. It knows a coding agent can do work, but doesn’t know how you’d use it.”
The practical implication: more developers are routing between models based on task type.
This isn’t a failure of any single provider. Claude Opus 4.6 leads on coding (79.2% SWE-Bench Verified on Vals.ai vs 77.2%), BrowseComp (84.0% vs 82.7%), and tool-use reliability (99.3% vs 98.9% on tau2-bench Telecom). GPT-5.4 leads on computer use (75.0% vs 72.7%), knowledge work (83.0% vs 78.0% on GDPval), and brings a genuinely new capability with native tool search.
Pricing: What It Actually Costs
| Model | Input / MTok | Cached Input | Output / MTok |
|---|---|---|---|
| GPT-5.4 | $2.50 | $0.25 | $15.00 |
| GPT-5.2 | $1.75 | $0.175 | $14.00 |
| Claude Sonnet 4.6 | $3.00 | $0.30 | $15.00 |
| Claude Opus 4.6 | $5.00 | $0.50 | $25.00 |
| Gemini 3.1 Pro | $2.00 | $0.20 | $12.00 |
GPT-5.4 is 43% more expensive on input than GPT-5.2 ($2.50 vs $1.75). Output pricing barely moved ($15.00 vs $14.00). Compared to Claude Sonnet 4.6, GPT-5.4 is actually 17% cheaper on input ($2.50 vs $3.00) with identical output pricing ($15.00).
The real cost story is token efficiency. OpenAI claims GPT-5.4 is their “most token-efficient reasoning model yet, using significantly fewer tokens to solve problems compared to GPT-5.2.” If that holds in practice, the higher per-token cost could translate to lower total cost per task. Tool search amplifies this — a 47% token reduction on MCP-heavy workloads directly offsets the input price increase.
For the Pro tier: $30.00 input / $180.00 output per MTok. That’s for maximum performance on the most complex tasks — not for everyday development work.
Migration Fatigue Is Real
GPT-5.3 Instant shipped just two days before GPT-5.4. The Hacker News thread reflects growing exhaustion:
“I’ve officially got model fatigue. I don’t care anymore.”
“It is time for a product, not for a marginally improved model.”
Another commenter expanded on that point:
“ChatGPT is still just that: Chat. Meanwhile, Anthropic offers a desktop app with plugins that easily extend the data Claude has access to. Connect it to Confluence, Jira, and Outlook, and it’ll tell you what your top priorities are for the day. OpenAI doesn’t have a product the way Anthropic does.”
But a plasma physicist offered a counterpoint on raw capability:
“For tasks like manipulating analytic systems of equations, quickly developing new features for simulation codes, and interpreting and designing experiments — they suddenly have developed deep understanding and become very useful.”
The tension is real. The models are getting better, but the release cadence makes it hard to build stable workflows. As one commenter put it: “The models are so good that incremental improvements are not super impressive. We literally would benefit more from spending on implementation into services and industrial economy.”
The Bottom Line
GPT-5.4 isn’t a coding model upgrade. It’s a computer-use and knowledge-work upgrade that also happens to code.
If you’re building desktop automation agents, the jump from 47% to 75% on OSWorld is a capability unlock worth integrating immediately. If you’re running MCP-heavy workflows, tool search alone could cut your token costs in half. If you’re building coding agents, Claude Opus 4.6 and Sonnet 4.6 still lead on the benchmarks that matter most.
The era of picking one model and sticking with it is over. Route by task. Benchmark your own workloads. And budget for the migration overhead — the next release is probably two weeks away. For a deeper comparison of how Gemini 3.1 Pro, Opus 4.6, and Codex 5.3 differentiate architecturally, see our three-model technical breakdown. And for the agent teams and orchestration features that make multi-model workflows practical, see our Opus 4.6 and Agent Teams deep dive.
References
- Introducing GPT-5.4 — OpenAI, March 2026
- Computer Use API Documentation — OpenAI Developers
- Tool Search API Documentation — OpenAI Developers
- SWE-Bench Verified Leaderboard — Vals.ai (independent)
- Claude Opus 4.6 Benchmarks — Vellum
- GPT-5.4 Hacker News Discussion — Hacker News
- Anthropic API Pricing — Anthropic
- OpenAI API Pricing — OpenAI
- Google AI Pricing — Google
- Stacklok MCP Optimizer vs Anthropic Tool Search — Stacklok
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.