Claude Sonnet 4.6: What Developers Actually Need to Know
The Benchmark Reality
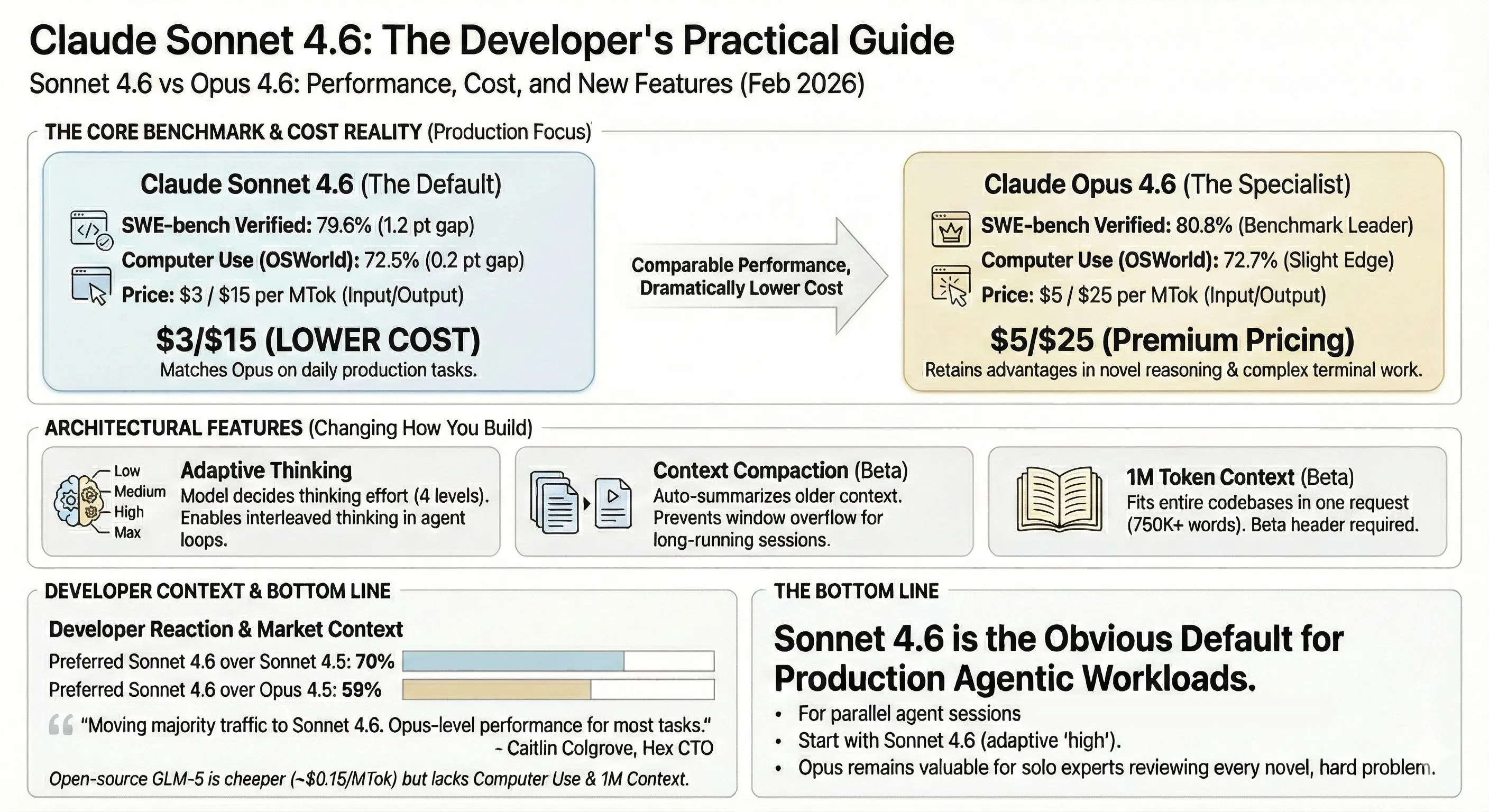
The numbers that matter for developers shipping code: Sonnet 4.6 nearly matches Opus 4.6 on the benchmarks enterprise teams actually use to evaluate models for agentic workflows.
| Benchmark | Sonnet 4.6 | Opus 4.6 | GPT-5.3 Codex | GPT-5.2 |
|---|---|---|---|---|
| SWE-bench Verified | 79.6% | 80.8% | — | 80.0% |
| SWE-Bench Pro (Public) | — | — | 56.8% | 55.6% |
| OSWorld (Computer Use) | 72.5% | 72.7% | 64.7% | 37.9% |
| GDPval (Office Tasks) | 1633 Elo | 1606 Elo | 70.9%* | 1462 Elo |
| Agentic Financial Analysis | 63.3% | 60.1% | — | 59.0% |
| Terminal-Bench 2.0 | 59.1% | 65.4% | 77.3% | 62.2% |
| Cybersecurity CTF | — | — | 77.6% | 67.7% |
| SWE-Lancer IC Diamond | — | — | 81.4% | 74.6% |
*GDPval score for GPT-5.3 Codex is wins-or-ties percentage; all other GDPval scores are Elo ratings. Higher is better in both metrics.
Note on SWE-bench variants: Anthropic reports on SWE-bench Verified while OpenAI reports on SWE-Bench Pro — these are different benchmark splits and not directly comparable. Anthropic’s model documentation page lists Sonnet 4.6 at 74.6% (10-trial average) and 80.2% with prompt modification on Verified. The 79.6% figure comes from the announcement post under conditions comparable to Opus.
The pattern: Sonnet 4.6 matches or beats Opus on production-oriented benchmarks (office tasks, financial analysis, coding) while Opus retains advantages on novel reasoning (~10 pt gap on ARC-AGI-2), deep agentic search (~9 pt gap on BrowseComp), and terminal work (65.4% vs 59.1% on Terminal-Bench 2.0). GPT-5.3 Codex leads all models on Terminal-Bench 2.0 (77.3%) and cybersecurity CTFs (77.6%), but trails on computer use — 64.7% vs Sonnet 4.6’s 72.5% on OSWorld. Notably, GPT-5.2 hits 80.0% on SWE-bench Verified — competitive with Opus 4.6’s 80.8% at lower per-token cost, though effective cost per task is often higher due to token consumption (see pricing section). For most teams, the production-oriented tasks where Sonnet competes with Opus are the ones that show up in daily work.
Architecture: Three Features That Change How You Build
Sonnet 4.6 introduces three architectural capabilities that directly affect how you structure agentic applications.
1. Adaptive Thinking
Previously, extended thinking required setting a fixed budget_tokens — you had to guess how much reasoning the model needed. Adaptive thinking replaces this with a type: "adaptive" mode where the model decides when and how much to think, guided by an effort parameter.
Four effort levels:
| Level | Behavior | Use Case |
|---|---|---|
max | Always thinks, no depth limit (Opus 4.6 only) | Hardest problems requiring maximum reasoning |
high (default) | Always thinks, deep reasoning | Complex coding, multi-step analysis |
medium | Moderate thinking, may skip for simple queries | Balanced latency and quality |
low | Minimal thinking, skips for simple tasks | High-throughput, latency-sensitive |
This matters because adaptive thinking also automatically enables interleaved thinking — the model can reason between tool calls in agentic loops, not just at the start of a response. For multi-step coding workflows where the agent calls tools, reads results, and decides next steps, this is a meaningful improvement.
Here’s how to use it with the Python SDK (from Anthropic’s docs):
import anthropic
client = anthropic.Anthropic()
response = client.messages.create( model="claude-sonnet-4-6", max_tokens=16000, thinking={"type": "adaptive"}, output_config={"effort": "medium"}, messages=[ { "role": "user", "content": "Refactor this module to use the repository pattern.", } ],)
for block in response.content: if block.type == "thinking": print(f"Thinking: {block.thinking}") elif block.type == "text": print(f"Response: {block.text}")Or in TypeScript:
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const response = await client.messages.create({ model: "claude-sonnet-4-6", max_tokens: 16000, thinking: { type: "adaptive" }, output_config: { effort: "medium" }, messages: [{ role: "user", content: "Refactor this module to use the repository pattern." }]});
for (const block of response.content) { if (block.type === "thinking") { console.log(`Thinking: ${block.thinking}`); } else if (block.type === "text") { console.log(`Response: ${block.text}`); }}Note: thinking.type: "enabled" with budget_tokens is deprecated on Sonnet 4.6 and Opus 4.6. It still works, but Anthropic recommends migrating to adaptive mode.
2. Context Compaction
For long-running agent sessions, context compaction (beta) automatically summarizes older conversation context when approaching the window limit. Instead of your agent session crashing when it hits 200K tokens, the API compresses the history and keeps going. This is particularly relevant for agentic coding workflows where tool-use loops can burn through context fast.
How it works: when input tokens exceed a configurable trigger threshold (minimum 50K tokens, default 150K), the API generates a summary of the conversation so far. On subsequent requests, all message blocks prior to the compaction summary are automatically dropped, and the conversation continues from the compressed state. You can also provide custom summarization instructions to preserve domain-specific context like variable names or architectural decisions.
See the compaction docs for API usage and code examples.
3. 1M Token Context Window (Beta)
Both Sonnet 4.6 and Opus 4.6 support a 1M token context window via a beta header. This is roughly 750K words — enough to fit entire codebases, lengthy contracts, or dozens of research papers in a single request.
from anthropic import Anthropic
client = Anthropic()
response = client.beta.messages.create( model="claude-sonnet-4-6", max_tokens=1024, messages=[{"role": "user", "content": "Analyze this codebase..."}], betas=["context-1m-2025-08-07"],)Important constraints:
- Tier requirement: Available to organizations in usage tier 4 and above
- Pricing: Requests exceeding 200K tokens are charged at 2x input and 1.5x output rates
- Rate limits: Long context requests have dedicated (lower) rate limits
The Pricing Math
This is where the release gets consequential for teams running parallel agent sessions at scale.
| Model | Input (per MTok) | Output (per MTok) | SWE-bench | Cost Ratio (vs Sonnet) |
|---|---|---|---|---|
| Claude Sonnet 4.6 | $3 | $15 | 79.6% (Verified) | 1x |
| Claude Opus 4.6 | $5 | $25 | 80.8% (Verified) | ~1.7x |
| GPT-5.3 Codex | $1.75** | $14** | 56.8% (Pro) | ~0.6x input / ~0.9x output |
| GPT-5.2 | $1.75 | $14 | 80.0% (Verified) | ~0.6x input / ~0.9x output |
| GLM-5 (open-source) | ~$1.00 | ~$3.20 | 77.8% | ~0.3x input / ~0.2x output |
The comparison that matters most: an agent processing 10M tokens/day costs roughly $30 in Sonnet 4.6 input vs $50 in Opus 4.6 input. Over a month, that’s ~$900 vs ~$1,500 per agent — and most teams run multiple agents in parallel.
On paper, GPT-5 series models look ~40% cheaper per token ($1.75 vs $3 input). In practice, the savings often evaporate. GPT-5.2 and GPT-5.3 Codex tend to consume significantly more tokens per task — reasoning tokens (billed at output rates of $14/MTok) inflate the actual cost, and agentic loops frequently require more iterations to converge. The effective cost per completed task can match or exceed Sonnet 4.6, particularly for complex agentic workflows. When evaluating the GPT-5 series, compare total cost per task, not per-token rates.
GPT-5.2 is competitive on SWE-bench Verified (80.0%) and GPT-5.3 Codex leads on terminal and cybersecurity benchmarks, but both trail on computer use (64.7% and 37.9% vs 72.5% OSWorld). GLM-5 is dramatically cheaper but lacks computer use, 1M token context, and — according to practitioners — the consistent instruction following needed for production agentic workflows.
*GPT-5.3 Codex scores 56.8% on SWE-Bench Pro, a different and harder benchmark split not directly comparable to Verified. The ~81% estimated Verified score uses GPT-5.2 as a calibration point (80.0% Verified / 55.6% Pro), applying the same ratio: 56.8 / 55.6 × 80.0 ≈ 81.7%.
**GPT-5.3 Codex API pricing has not been officially published by OpenAI as of Feb 17, 2026. Figures shown are estimated based on GPT-5.2 pricing.
Computer Use: 14.9% → 72.5% in 16 Months
The progression on OSWorld-Verified tells a story about compound improvement:
| Model | Date | OSWorld Score |
|---|---|---|
| Sonnet 3.5 | Oct 2024 | 14.9% |
| Sonnet 3.7 | Feb 2025 | 28.0% |
| Sonnet 4 | Jun 2025 | 42.2% |
| Sonnet 4.5 | Oct 2025 | 61.4% |
| Sonnet 4.6 | Feb 2026 | 72.5% |
That’s nearly a 5x improvement in 16 months. GPT-5.3 Codex reaches 64.7% — closing the gap but still behind Sonnet 4.6’s 72.5%. GPT-5.2 sits at 37.9%, roughly where Sonnet 4 was eight months ago.
Why this matters for developers: computer use is the capability that unlocks automation of legacy systems that lack APIs. Insurance portals, government databases, ERP systems, hospital scheduling tools — any software with a GUI but no programmatic interface becomes automatable. Jamie Cuffe, CEO of Pace, reported Sonnet 4.6 hit 94% accuracy on their complex insurance computer use benchmark: “It reasons through failures and self-corrects in ways we haven’t seen before.”
Anthropic also notes significant improvements in prompt injection resistance for computer use — critical when your agent browses the web and interacts with external systems where malicious actors can embed instructions.
What Developers Are Actually Saying
Developer reactions have been notably specific about cost-performance tradeoffs rather than generic praise. Here’s a sampling from early testers:
Moving to Sonnet 4.6 from Opus:
- Caitlin Colgrove, CTO of Hex Technologies: “We’re moving the majority of our traffic to Sonnet 4.6. With adaptive thinking and high effort, we see Opus-level performance on all but our hardest analytical tasks.”
- Leo Tchourakov, Factory AI: “We are transitioning our Sonnet traffic over to this model.”
- Brendan Falk, CEO of Hercules: “Opus 4.6 level accuracy, instruction following, and UI, all for a meaningfully lower cost.”
Coding-specific feedback:
- David Loker, VP of AI at CodeRabbit: “Punches way above its weight class for the vast majority of real-world PRs.”
- Joe Binder, VP of Product at GitHub: “Already excelling at complex code fixes, especially when searching across large codebases is essential.”
- Ben Kus, CTO of Box: Outperformed Sonnet 4.5 in heavy reasoning Q&A by 15 percentage points across real enterprise documents.
- Ryan Wiggins, Mercury Banking: “Faster, cheaper, and more likely to nail things on the first try.”
The dissenting view:
Boris Cherny, Claude Code’s creator, still prefers Opus for all coding work. His reasoning: the bottleneck isn’t token cost, it’s human time spent correcting AI mistakes. When a 1.2-point SWE-bench gap translates to even slightly more errors on hard problems, the time cost of debugging outweighs the savings. This is a valid perspective for solo developers or small teams where one person is deeply reviewing every output. For teams running dozens of parallel agent sessions where aggregate throughput matters more than peak accuracy, the calculus favors Sonnet.
Model Specs at a Glance
Quick reference for integrating Sonnet 4.6 into your stack:
| Spec | Sonnet 4.6 | Opus 4.6 |
|---|---|---|
| API Model ID | claude-sonnet-4-6 | claude-opus-4-6 |
| AWS Bedrock ID | anthropic.claude-sonnet-4-6 | anthropic.claude-opus-4-6-v1 |
| GCP Vertex AI ID | claude-sonnet-4-6 | claude-opus-4-6 |
| Context Window | 200K (standard) / 1M (beta) | 200K (standard) / 1M (beta) |
| Max Output | 64K tokens | 128K tokens |
| Training Data Cutoff | Jan 2026 | Aug 2025 |
| Adaptive Thinking | Yes | Yes |
| Extended Thinking | Yes | Yes |
| Latency | Fast | Moderate |
Where Open-Source Stands
GLM-5 deserves mention because it represents where the open-source frontier is heading. At 77.8% SWE-bench and roughly $1.00/MTok input (3x cheaper than Sonnet 4.6), the raw coding capability gap is narrowing fast.
But capability convergence isn’t the full story. No open model currently offers:
- Computer use (GUI automation)
- 1M token context windows
- Context compaction for effectively infinite sessions
- Adaptive thinking with effort controls
- Consistent instruction following across production-scale agentic workflows
Model capability is converging. The moat is increasingly in infrastructure, tooling, and the ecosystem around the model — not the model weights themselves. For a detailed comparison of how Sonnet 4.6 stacks up against Gemini 3.1 Pro and Codex 5.3 across architectures and benchmarks, see our three-model technical breakdown.
Bottom Line
For teams running parallel agent sessions where cost per autonomous hour matters more than peak capability on the hardest 5% of problems, the ~1.7x Opus premium may not be justified — though the gap is narrow enough that many teams will find Opus worth the extra spend. Sonnet 4.6 remains a strong default for the majority of production agentic workloads.
For solo developers or teams where one expert is closely reviewing every output and working on novel, hard problems — Opus still has an edge worth paying for, particularly on complex terminal work, novel reasoning, and deep agentic search.
The practical migration: start with claude-sonnet-4-6 using adaptive thinking at high effort. If you notice quality drops on your specific workload, bump to Opus selectively for those tasks. Most teams will find they rarely need to.
Key Takeaways
- SWE-bench Verified: 79.6% vs Opus 4.6’s 80.8% — a 1.2 point gap at ~1.7x lower cost ($3/$15 vs $5/$25 per MTok)
- Computer use: OSWorld went from 14.9% to 72.5% in 16 months. GPT-5.3 Codex reaches 64.7% — closing the gap but still behind
- GPT-5 series pricing caveat: Per-token rates are ~40% cheaper ($1.75 vs $3 input), but higher token consumption per task — especially reasoning tokens — often levels out or exceeds effective cost
- New architecture features: Adaptive thinking (4 effort levels), context compaction (beta), and a 1M token context window (beta)
- Developer preference: 70% preferred over Sonnet 4.5 in Claude Code; 59% preferred over Opus 4.5
- Open-source pressure: GLM-5 hits 77.8% SWE-bench at ~$1.00/MTok input — 3x cheaper, but lacks computer use and 1M context
References:
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.