Your Agent's Bottleneck Isn't the Model. It's the Context.
Your AI coding agent doesn’t have a model problem. It has a context problem.
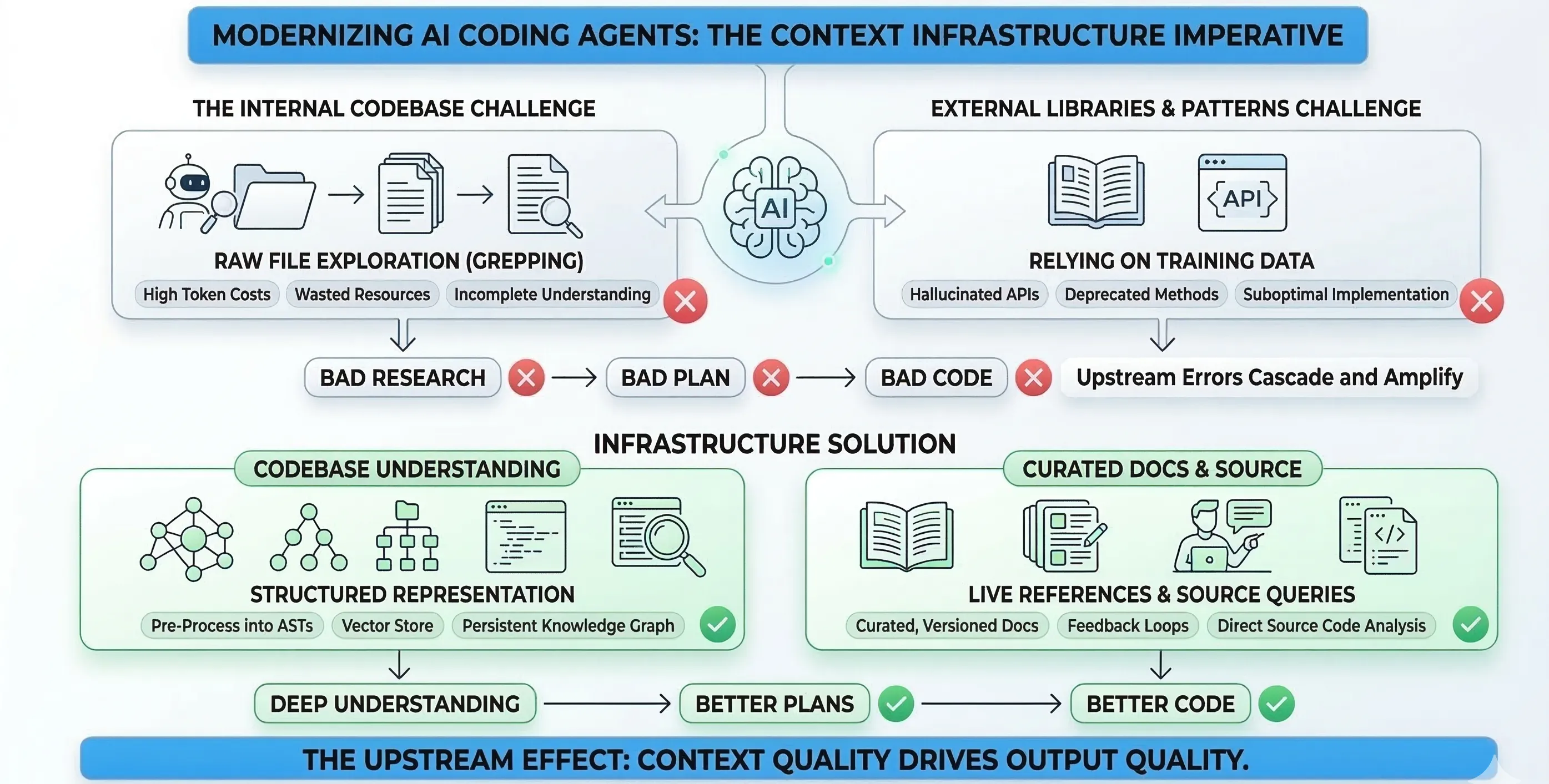
It greps through your codebase file by file, burning hundreds of thousands of tokens to answer a question that a structured index could resolve in a few hundred. It hallucinates API methods that don’t exist, references deprecated parameters, and builds suboptimal implementations — because it’s working from training data, not from actual source code. And this isn’t limited to external libraries. Even for general implementation patterns — how to structure error handling, which algorithm to reach for, how to design a module boundary — the agent defaults to whatever it learned during training, which may not be the best or most current approach.
Better models won’t fix this. A model with a larger context window still wastes tokens if the retrieval mechanism is “read every file and hope.” A model trained on more data still hallucinates when the library it needs shipped a breaking change six months after the training cutoff.
The fix is infrastructure. And in early 2026, a new class of tools is emerging to build it.
Key Takeaways
- Model quality does not solve context quality. Bigger context windows and stronger models still fail when retrieval is brute-force file reading or stale training data.
- Internal and external context failures produce the same outcome: bad code. Poor codebase understanding and outdated library knowledge both degrade research, planning, and implementation quality.
- Structured indexing can reduce token burn by orders of magnitude. AST-aware and semantic indexing approaches consistently outperform file-by-file grep workflows for the same information needs.
- Retrieval execution is becoming its own layer. Search can run as a dedicated subagent (for example, WarpGrep) backed by fast primitives such as ripgrep instead of bloating the parent agent’s context.
- Fresh, grounded external context beats memory. Tools like Context Hub and Better Context improve reliability by grounding generation in current docs or source code instead of model recall.
- Context infrastructure is now a first-class engineering investment. Teams getting the best agent output are optimizing research and context pipelines, not just swapping to newer models.
Two Gaps, Same Failure Mode
Agents face two distinct context problems that produce the same downstream result: bad code.
Internal context: the agent doesn’t understand your codebase cost-effectively. It explores by reading files sequentially, summarizing what it finds, and passing results back. This works, but it’s wildly inefficient. A question about your project’s authentication flow might require the agent to read dozens of files before it pieces together the answer.
External context and implementation patterns: the agent doesn’t have access to accurate, current documentation for the libraries and APIs it uses — and more broadly, it relies on training data for general implementation decisions. It falls back on patterns it learned during training, which may be months or years stale. For libraries, the result is code that calls methods that no longer exist, passes parameters in the wrong order, or misses entirely that a simpler, better-supported approach was added in the latest release. For implementation patterns more generally, the agent may reach for a suboptimal algorithm, structure code in ways that don’t match current best practices, or miss idioms that the ecosystem has converged on since the training cutoff.
Both problems feed into the same failure chain: bad research produces bad plans, and bad plans produce bad code. Dex Horthy, founder of HumanLayer, articulated this clearly in his Advanced Context Engineering post: a bad line of code is a bad line of code, but a bad line in a plan leads to hundreds of bad lines of code, and bad research leads to thousands. Upstream errors cascade and amplify downstream.
His conclusion is blunt: the contents of your context window are the only lever you have to affect output quality.
The tools emerging in early 2026 are making that lever easier to pull.
The Internal Context Problem: Stop Grepping, Start Indexing
The brute-force approach to codebase exploration — spawn a sub-agent, let it grep through files, summarize what it found — technically works. But the token costs are staggering.
A developer built an MCP server called codebase-memory-mcp that indexes repositories into a persistent knowledge graph using Tree-sitter and SQLite. In project-reported benchmarking published in the repository README and discussed on Hacker News, five structural queries consumed approximately 3,400 tokens via the indexed approach versus approximately 412,000 tokens via file-by-file grep exploration. That’s roughly a 120x reduction for the same information. This is not an independent or official benchmark.
The approach matters more than the specific tool. Instead of letting the agent read raw files, you pre-process the codebase into a structured representation — an AST-aware index, a knowledge graph, a vector store — and let the agent query that structure directly.
CocoIndex-Code, built by Linghua Jin (ex-Google tech lead), takes this approach with vector embeddings and AST-aware chunking. It uses Tree-sitter to parse code into meaningful chunks — functions, classes, logical blocks — rather than arbitrary text splits, then indexes them into local SQLite with vector search. The agent queries semantic representations instead of grepping raw files. Jin reports approximately 70% token savings in her own usage, though this figure is self-reported and hasn’t been independently benchmarked.
Aristidis Vasilopoulos formalized the broader pattern in a recent paper, Codified Context: Infrastructure for AI Agents in a Complex Codebase. Drawing on 283 development sessions with a large C# distributed system, Vasilopoulos describes an infrastructure framework comprising a constitution (project-wide rules), nineteen specialized domain-expert agents, and thirty-four specification documents. The key insight: structuring context as queryable infrastructure rather than ad hoc file reading fundamentally changes agent effectiveness.
The Retrieval Execution Layer: Search as a Subagent
Indexes are one answer to the internal context problem. Another emerging answer is retrieval execution: move search into a dedicated execution layer that can run many targeted tool calls and return only the relevant spans to the parent agent.
Morph’s WarpGrep packages this as a dedicated code-search subagent. In Morph’s documented protocol, the search agent runs a bounded multi-turn tool loop (ripgrep, read, list_directory, then finish) and sends back narrowed snippets rather than every intermediate step. The design goal is to keep the main coding agent focused on planning and synthesis while retrieval-specific work happens in a separate context window.
That separation is the key architectural shift. With indexing, you precompute structure and query it. With retrieval execution, you orchestrate live search calls efficiently at runtime. In practice, teams often combine both: indexed retrieval for high-recall structural queries, and execution-layer search for fast, tactical narrowing when the agent needs exact lines or surrounding implementation detail.
Open-source primitives are what make this layer practical. ripgrep is widely used because it is fast on large repos, respects ignore files by default, and composes cleanly with tool-driven workflows. Local and remote search systems frequently expose rg-style lexical search as the first pass, then follow with targeted file reads or higher-level ranking.
As with any fast-moving tooling category, treat benchmark and quality claims carefully. Morph’s speed and quality numbers are vendor-reported, and behavior can vary across repository size, language mix, and tool adapter quality.
The External Context Problem: Training Data Isn’t Documentation
The internal problem is expensive. The external problem is dangerous.
When an agent needs to use a library it wasn’t trained on — or was trained on an outdated version of — it has three options: hallucinate, use stale knowledge, or give up. None of these produce correct code.
Two tools are attacking this from different angles.
Context Hub: Curated Docs with a Feedback Loop
Andrew Ng’s team built Context Hub, an open-source CLI tool that gives coding agents access to curated, versioned API documentation. The core design is straightforward: a registry of markdown documentation files optimized for LLM consumption, fetchable via a simple CLI.
# Installnpm install -g @aisuite/chub
# Search for available docschub search stripe
# Fetch language-specific API docschub get openai/chat --lang py
# Fetch a specific reference file (saves tokens)chub get stripe/api --file webhooksWhat makes it interesting is the feedback loop. Agents can attach annotations to documentation that persist across sessions. If an agent discovers that Stripe’s webhook verification requires raw body access, it can annotate that finding, and every future session benefits from that knowledge automatically. Agents can also vote documentation up or down, creating real-world usage signals that flow back to documentation authors.
This solves the freshness problem through curation rather than training. The documentation is maintained as open markdown files in the repository — inspectable, version-controlled, and community-contributed.
Better Context: Skip the Docs, Read the Source
Better Context, built by Ben Davis, takes a more radical approach: it skips documentation entirely and queries actual library source code.
The reasoning is pragmatic. Documentation is frequently outdated, incomplete, or misleading. The implementation is the only source of truth. When you need to know how a function actually behaves — what edge cases it handles, what exceptions it throws, what the default parameters are — reading the source code gives you the definitive answer.
Better Context is a CLI tool and web interface that lets you ask AI-powered questions about libraries and frameworks, grounding the answers in real implementation files rather than documentation. It supports multiple AI providers and models.
These two approaches aren’t competing. They’re complementary. Context Hub works well when documentation is actively maintained and the API surface is the primary concern. Better Context works well when documentation is stale or when you need implementation-level detail that docs don’t cover. Both are better than the status quo of hoping the model remembers correctly.
The Evidence: Context Quality Drives Output Quality
This isn’t theoretical. Multiple practitioners are converging on the same finding: improving context infrastructure directly improves agent output.
Dex Horthy demonstrated this through his Research-Plan-Implement methodology at HumanLayer. Working on BAML, a 300,000 LOC Rust codebase, he and a colleague reported shipping 35,000 lines in 7 hours by investing heavily in the research phase before letting the agent plan or write code. The key was front-loading context quality — understanding the codebase deeply before generating a single line (source).
Calvin French-Owen, co-founder of Segment, reached a similar conclusion from a different direction. In his February 2026 retrospective on coding agents, he described a workflow where the planning and context-gathering phase — not the code generation — was the bottleneck that determined output quality. He identified context coordination as one of the primary barriers to continuous agent execution.
The pattern is consistent: the agents that produce the best code are the ones with the best context, not the ones with the most capable models.
What This Means for Your Stack
If you’re building with AI coding agents today, the practical takeaway is straightforward.
For internal context: treat this as an infrastructure choice with three valid options.
Option 1: Index your codebase. Tools like codebase-memory-mcp and CocoIndex-Code pre-process your repository into structured indexes — knowledge graphs, vector stores, AST-aware chunks — so the agent can query for relevant context directly instead of grepping file by file. This can reduce token usage by 100x+ for structural queries. If you can maintain the index, this is usually the highest-throughput path.
Option 2: Add a retrieval execution layer. Tools like Morph WarpGrep run code search as a dedicated subagent that executes concrete search/read tools and returns a compact result set to the parent agent. This is useful when you want lower setup overhead than full indexing, but still want retrieval to be structured and bounded instead of ad hoc file-by-file exploration.
Option 3: Deep codebase research with skills and subagents. Even without a pre-built index, you can still get high-quality context by structuring how the agent explores the codebase. Instead of letting it grep blindly, use a systematic research workflow that dispatches specialized subagents to map architecture, trace dependencies, and document conventions before any code gets written. Atomic’s research-codebase skill is one example: it uses a set of coordinated subagents to build contextual understanding before planning and implementation.
Both approaches serve the same goal: closing the gap between what the agent sees and what it needs to understand. Pick based on your team’s constraints, but avoid unstructured file-by-file discovery as the default.
For external context: don’t rely on training data for library knowledge. Use tools like Context Hub or Better Context to give your agent access to current, accurate API documentation or source code. This is especially critical for fast-moving libraries where the API surface changes between releases.
For workflow: invest in the research phase. Horthy’s Research-Plan-Implement framework and French-Owen’s planning-first workflow both point the same direction — the quality of your agent’s output is bounded by the quality of its understanding, and understanding is bounded by context.
We spent 2025 assuming models would get good enough to figure it out on their own. The evidence from early 2026 suggests otherwise. The agents that work well are the ones with good context infrastructure underneath them. The model is the engine, but context is the fuel. Better fuel produces better output — regardless of the engine.
References
- DeusData. codebase-memory-mcp. GitHub. Benchmarked across 64 real-world repositories.
- Linghua Jin. CocoIndex-Code. GitHub. AST-based code MCP with semantic search.
- Andrew Ng et al. Context Hub. GitHub.
- Ben Davis. Better Context. GitHub. Source-code-based library exploration.
- Dex Horthy. Advanced Context Engineering for Coding Agents. HumanLayer Blog. August 29, 2025.
- Aristidis Vasilopoulos. Codified Context: Infrastructure for AI Agents in a Complex Codebase. arXiv. February 24, 2026.
- Calvin French-Owen. Coding Agents in Feb 2026. February 17, 2026.
- Morph. WarpGrep Overview. Morph Documentation.
- Morph. WarpGrep API Reference. Morph Documentation.
- Morph. WarpGrep Tool Integrations. Morph Documentation.
- Morph. WarpGrep Examples. GitHub.
- Andrew Gallant. ripgrep. GitHub.
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.