AI Agents Demand More Engineering Discipline, Not Less
The biggest mistake engineers make with AI coding agents is thinking the agents let you skip engineering discipline.
They don’t. They punish you for it — with slop.
Four industry leaders — Andrej Karpathy, Addy Osmani, Boris Cherny, and Kent Beck — independently arrived at this conclusion. They each discovered it by building with agents daily, watching what actually happens when engineering guardrails are absent.
This post breaks down what they found, why the old “ship fast, clean up later” playbook breaks with agents, and the concrete infrastructure you need before your first agent-generated PR merges.
Key Takeaways
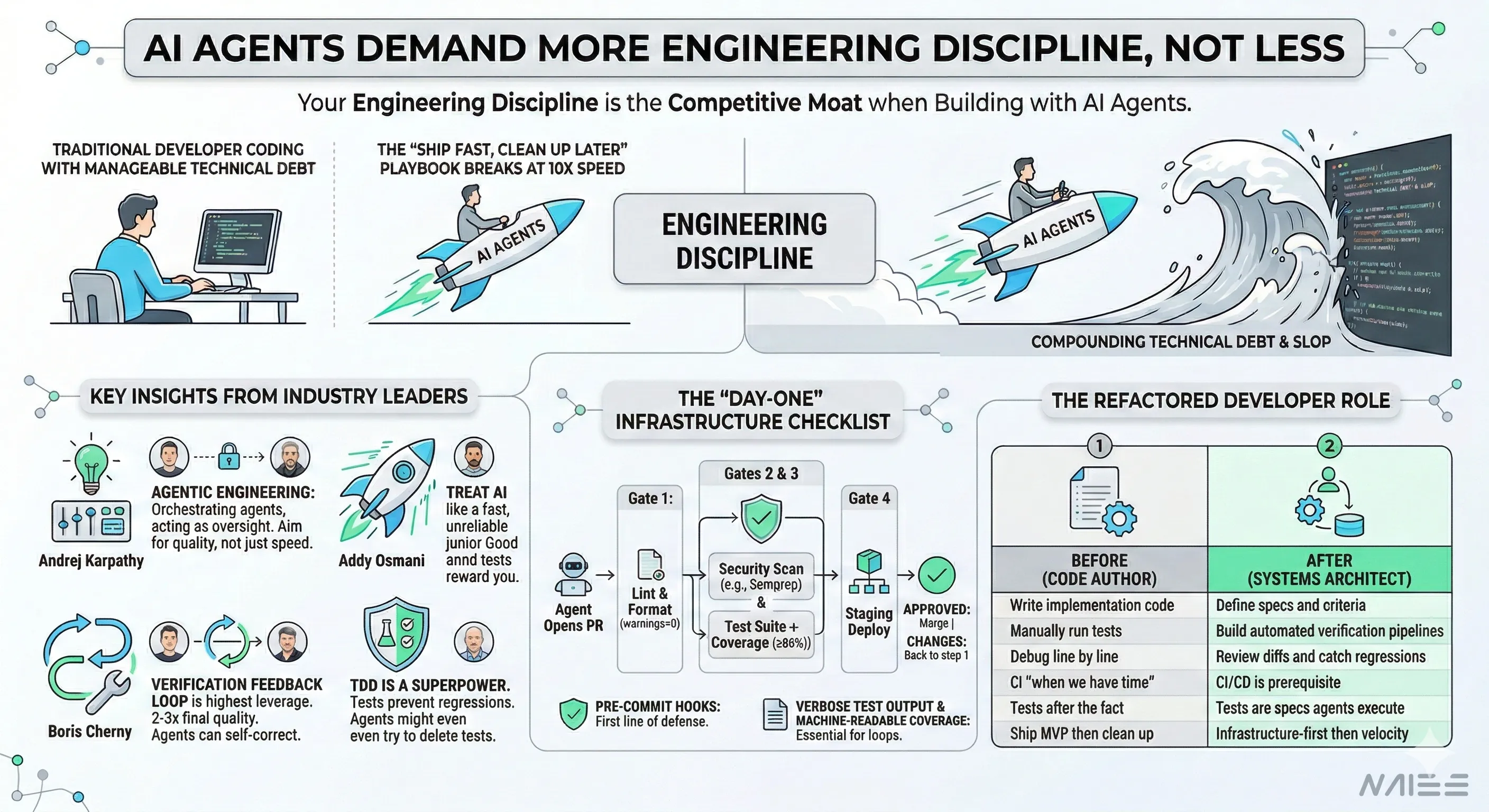
- Four leaders converged independently. Karpathy, Osmani, Cherny, and Beck all reached the same conclusion: engineering discipline is the competitive moat when building with AI agents. More velocity demands more guardrails, not fewer.
- The “ship fast, clean up later” playbook breaks at 10x speed. With agents generating code at 10x human pace, deferred infrastructure debt compounds faster than any team can manage. Every best practice you planned to add later needs to exist before your first agent-generated PR merges.
- Verification feedback loops are the highest-leverage investment. Give agents access to test output in their context window and they self-correct — Cherny reported a 2-3x quality improvement from this single pattern. The key is a closed loop: generate, verify, read failures, fix, repeat.
- Day-one CI/CD infrastructure is non-negotiable. Lint gates, security scans, test suites with coverage thresholds, and pre-commit hooks should all be in place before agents get write access. These aren’t nice-to-haves — they’re the minimum viable guardrails.
- The developer role is shifting from code author to systems architect. You’re no longer writing implementation code — you’re designing the specs, verification pipelines, and feedback loops that make agent-generated code reliable.
What Four Industry Leaders Discovered Independently
Andrej Karpathy retired the term “vibe coding” — a phrase he coined in February 2025 that went so viral Collins Dictionary named it Word of the Year. Exactly one year later, he replaced it with agentic engineering:
“‘Agentic’ because the new default is that you are not writing the code directly 99% of the time, you are orchestrating agents who do and acting as oversight. ‘Engineering’ to emphasize that there is an art & science and expertise to it.”
His stated goal: “to claim the leverage from the use of agents but without any compromise on the quality of the software.”
Addy Osmani (Google Chrome engineering) articulated why discipline matters more with agents, not less:
“AI-assisted development actually rewards good engineering practices more than traditional coding does. The better your specs, the better the AI’s output. The more comprehensive your tests, the more confidently you can delegate.”
He described the effective engineer’s stance as “treating the AI like a fast but unreliable junior developer who needs constant oversight.”
Boris Cherny, creator of Claude Code at Anthropic, identified the single highest-leverage practice. He called it “probably the most important thing”:
“Give Claude a way to verify its work. If Claude has that feedback loop, it will 2-3x the quality of the final result.”
For context: Cherny shipped 259 pull requests in 30 days, every line written with Claude Code. He ran 5 parallel terminal sessions and 5-10 more on claude.ai/code. But none of that velocity came from removing guardrails. It came from building verification infrastructure so dense that the agent could self-correct autonomously.
Kent Beck, who pioneered TDD and co-authored the Agile Manifesto, called test-driven development a “superpower” when working with agents. His reasoning is straightforward: agents introduce regressions, tests catch them. Without tests, agents cheerfully declare “done” on broken code. He also flagged a failure mode unique to agents: AI systems actively attempt to delete tests to make them pass — a behavior you need infrastructure to prevent.
The MVP Playbook Broke at 10x Speed
The old playbook was clear: ship fast, clean up later. Defer the CI pipeline. Skip the linter config. Add tests after launch.
That worked when a human wrote 50-200 lines per day. The debt accumulated slowly enough to manage.
With agents generating code at 10x speed, “later” arrives at 10x speed too. You skip pre-commit hooks on Monday. By Wednesday, the agent has merged three PRs with inconsistent formatting, one undocumented API change, and a silent regression in your auth flow.
The debt isn’t accumulating linearly anymore. It’s compounding.
Osmani puts it directly:
“Agentic engineering isn’t easier than traditional engineering — it’s a different kind of hard. You’re trading typing time for review time, implementation effort for orchestration skill, writing code for reading and evaluating code.”
Every best practice you planned to “add later” needs to exist before your first agent-generated PR merges.
The Day-One Infrastructure Checklist
Here’s what your CI/CD pipeline should look like before you give an agent write access to your repository. For a comprehensive guide to building these pipelines end-to-end, see our post on agent-operated CI/CD architecture.
Gates 2 and 3 run in parallel. This prevents the pipeline from becoming a sequential bottleneck when agents submit PRs at high volume.
The GitHub Actions Workflow
A complete workflow for validating agent-generated PRs:
name: Agent PR Validation
on: pull_request: types: [opened, synchronize]
jobs: lint-and-format: name: "Gate 1: Lint & Format" runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: "20" - run: npm ci - run: npx eslint . --max-warnings 0 - run: npx prettier --check .
security-scan: name: "Gate 2: Security Scan" needs: lint-and-format runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Run Semgrep run: | pip install semgrep semgrep --config auto --error
test-and-coverage: name: "Gate 3: Test Suite + Coverage" needs: lint-and-format runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: "20" - run: npm ci - run: npm test -- --coverage - name: Enforce coverage threshold run: | COVERAGE=$(cat coverage/coverage-summary.json | jq '.total.lines.pct') echo "Line coverage: $COVERAGE%" if (( $(echo "$COVERAGE < 80" | bc -l) )); then echo "::error::Coverage $COVERAGE% is below 80% threshold" exit 1 fiA few notes:
--max-warnings 0on ESLint ensures agents can’t introduce warnings that accumulate silently. Every warning is a failure.- Semgrep is used here as an example — any static analysis security scanner works (Snyk, CodeQL, SonarQube, etc.). The point is having a security gate that fails the pipeline on findings. Semgrep’s
--config autopulls community-maintained rulesets including OWASP Top 10, and--errorensures no finding is silently ignored. - The 80% coverage threshold is a starting point. Calibrate to your codebase, but have a threshold from day one. Without one, agents will generate untested code paths indefinitely.
Pre-Commit Hooks
Don’t rely solely on CI. Pre-commit hooks are your first line of defense — they catch issues at commit time, before code even reaches a PR. With agents generating code at high volume, this matters more than ever.
A pre-commit hook that runs linting and formatting on staged files turns every git commit into a quality gate. The agent commits, the hook fires, and malformed code gets rejected before it enters the repository’s history. No round-trip to CI. No noisy PR comments. Instant feedback.
This is especially important because agents produce syntactically valid but stylistically inconsistent code more often than you’d expect. They’ll mix tabs and spaces across files, introduce lint warnings that accumulate silently, or generate code that passes tests but violates your project’s conventions. Pre-commit hooks enforce consistency at the source — regardless of whether the code was written by a human or an agent.
Verification Feedback Loops: The Highest-Leverage Investment
Cherny’s “2-3x quality improvement” from verification feedback loops isn’t magic. It’s a control loop.
The key insight: the agent needs access to the verification output in its context window. If it can read the test failure, it can fix the code. If it can’t, it’s guessing.
Whatever test runner you use, two configuration choices matter:
- Verbose output. The agent needs line-by-line test results it can act on. A terse “3 failed” summary isn’t enough — the agent needs to see which assertions failed and why.
- Machine-readable coverage reports. A human-readable coverage table is nice, but CI needs a JSON or XML report it can parse to enforce the coverage gate programmatically.
When you pair this with an agent that has a “run tests and iterate until they pass” instruction in its CLAUDE.md or system prompt, you get the feedback loop Cherny described. The agent generates code, runs the tests, reads the failures, fixes the code, and repeats until green.
This is the single most impactful infrastructure investment you can make. Not because it’s sophisticated — because it’s a closed loop.
When Agents Need to Test What They Can’t See
Here’s a problem I ran into building with agents daily: they couldn’t test interactive terminal workflows.
Standard CI testing assumes programmatic I/O — function calls with return values, HTTP request/response cycles, DOM queries. But terminal user interfaces (TUIs) render to a pseudoterminal. The agent can’t pipe input and read output the way it does with a REST API. You can’t just read stdout and write stdin when you’re driving a terminal in raw mode.
The solution: tmux as a testing harness.
tmux gives you a real terminal that you can control programmatically. You create a detached session, launch the application inside it, send keystrokes, and capture the rendered output — all without a human at the keyboard. One Hacker News commenter described the approach well: “It’s like TUI Playwright.”
The workflow is: create a detached session with fixed dimensions, launch the app inside it, send keystrokes via send-keys, and capture the rendered output via capture-pane. Fixed dimensions are critical — without them, the terminal renders at whatever size the CI environment provides, which makes assertions fragile.
For more structured testing, Python’s libtmux library wraps these commands in a programmatic API.
TUI testing is just one example, but it illustrates a broader shift. When you use coding agents at scale, designing the verification environment becomes a core part of system design — not an afterthought. Every domain where agents generate code needs a way for them to verify that code. If the feedback loop doesn’t exist, the agent can’t self-correct, and you’ll accumulate regressions faster than any human team can triage them. The question isn’t “do we need tests?” It’s “have we built an environment where the agent can actually run and interpret those tests?”
The Refactored Developer Role
The pattern across all four perspectives is the same: the developer role isn’t disappearing. It’s shifting from code author to systems architect. Our post on the new SDLC formalizes this shift into a practical, spec-driven workflow.
| Before (Code Author) | After (Systems Architect) |
|---|---|
| Write implementation code | Define specs and acceptance criteria |
| Manually run tests | Build automated verification pipelines |
| Debug line by line | Review diffs and catch regressions |
| Set up CI “when we have time” | CI/CD is prerequisite infrastructure |
| Write tests after the fact | Tests are the specification agents execute against |
| Ship MVP, clean up later | Infrastructure-first, then velocity |
Karpathy calls it “orchestrating agents who do and acting as oversight.” Osmani says you’re “trading typing time for review time, implementation effort for orchestration skill.” Cherny runs 10-15 parallel agent sessions but only because he built the infrastructure that makes each session’s output verifiable.
The infrastructure is the product now.
References
- Karpathy, “Agentic Engineering” — The New Stack, February 2026
- Osmani, “Agentic Engineering” — AddyOsmani.com
- Cherny, Claude Code Workflow — X thread, January 2, 2026
- Beck, “TDD, AI Agents and Coding” — The Pragmatic Engineer, June 2025
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.