Google DeepMind's Delegation Framework for Coding Agent Architecture
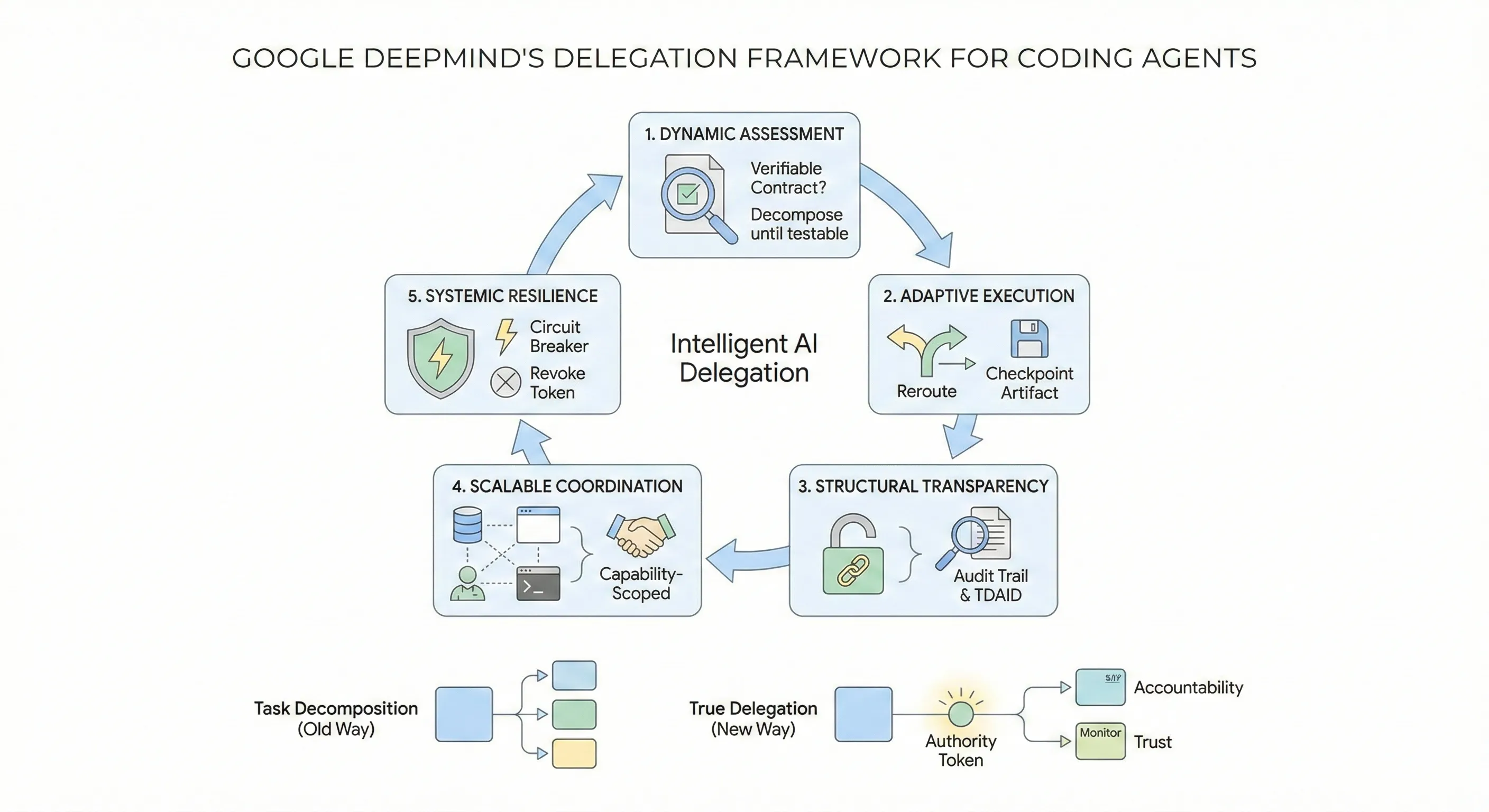
The Gap Between Task Splitting and True Delegation
Most coding agents decompose tasks the same way: take a complex request, break it into subtasks, execute them sequentially or in parallel, merge the results. It works for small problems. It falls apart at scale.
Google DeepMind’s Intelligent AI Delegation paper, published February 12, 2026 by Nenad Tomasev, Matija Franklin, and Simon Osindero, argues this is because we’ve been confusing task decomposition with delegation. Decomposition is mechanical. Delegation is a sociotechnical transfer of authority, responsibility, accountability, and trust. Without formalizing those transfers, multi-agent systems are prone to silent failures, responsibility diffusion, and cascading errors.
The paper is primarily a conceptual framework, not an empirical study. But it crystallizes patterns that the best coding agent teams have already discovered independently, and it provides a vocabulary for the problems everyone else is hitting. This post breaks down the framework’s five pillars, maps each to concrete coding agent patterns, and gives you actionable takeaways.
The Five Pillars, Applied to Coding Agents
The framework rests on five pillars: dynamic assessment, adaptive execution, structural transparency, scalable market coordination, and systemic resilience. Here’s what each one means for coding agents specifically.
1. Dynamic Assessment: Know What Your Agents Can Actually Do
The paper frames task decomposition as an optimization problem — not a heuristic. The goal is to recursively decompose until every subtask’s output is verifiable. This is the contract-first principle: don’t delegate what you can’t check.
In practice, this is the difference between how Cursor’s 1,000-agent browser experiment and Anthropic’s 16-agent compiler project approached decomposition. Both converged on hierarchical structures where planner agents assess complexity and match subtasks to workers based on demonstrated capability, not just availability.
The key insight for coding agents: decompose until you can write a test for each subtask’s output. If you can’t express the success criteria programmatically, the subtask isn’t granular enough.
Every delegation contract should specify four things: what the subtask is, how to verify it was done correctly (a test suite, type check, lint pass, build check, or human review), what tools the agent is allowed to use (scoped permissions), and what to do if it fails (retry, reassign to a different agent, or escalate to a human). If you can’t fill in the verification field, the subtask isn’t granular enough yet.
2. Adaptive Execution: Plans Will Break, Build for It
Static execution plans assume the environment won’t change mid-task. In coding, this assumption is always wrong. A dependency update breaks the build. A test reveals a deeper architectural issue. A file conflict emerges because two agents touched the same module.
The paper proposes adaptive coordination cycles — continuous monitoring that triggers re-delegation based on internal signals (performance degradation, anomalies) or external events (resource changes, specification shifts). This is backed by checkpoint artifact serialization: standardized schemas for saving partial work so a different agent can resume without starting over.
This maps directly to how Anthropic’s long-running agent harness works in practice. Their effective harnesses pattern enforces a session initialization ritual: read progress logs, review git history, verify baseline functionality. Each session ends with a descriptive git commit and progress file update. This is checkpoint serialization using Git as the substrate.
# Anthropic's agent session loop — checkpoint serialization via Gitwhile true; do # 1. Restore context from last checkpoint git pull origin main cat claude-progress.txt # What was done, what's next
# 2. Execute one feature (not the whole plan) claude --dangerously-skip-permissions \ -p "$(cat AGENT_PROMPT.md)" \ --model claude-opus-4-6
# 3. Checkpoint: serialize state for next agent/session git add -A && git commit -m "feat: implement <feature>" echo "Completed: <feature>. Next: <next-feature>" >> claude-progress.txt git push origin maindoneThe critical pattern: never rely on a single context window for multi-step work. Each agent session should be recoverable from its checkpoint artifacts alone.
3. Structural Transparency: Verify Everything, Trust Nothing
The paper’s strongest claim is that delegation should operate under a zero-trust model, borrowing from the principal-agent problem in economics. Don’t assume a sub-agent performed correctly because the prompt was well-structured. Verify.
For coding agents, this manifests as multi-layered verification. The most effective pattern emerging in 2026 is Test-Driven AI Development (TDAID): Plan, Red, Green, Refactor, Validate. Tests serve double duty — they’re both the specification and the exit criteria for the agent loop.
A key finding from practitioners implementing TDD with coding agents: context isolation between phases is critical. When the test writer and implementer share a context window, the implementer’s knowledge of the test internals bleeds into its implementation, defeating the purpose of TDD. Claude Code’s subagent architecture addresses this by giving each phase its own isolated context:
tdd-test-writer— creates failing tests (the contract)tdd-implementer— writes minimal code to pass (the deliverable)tdd-refactorer— evaluates and cleans (the audit)
This maps directly to the paper’s recursive verification pattern: each agent verifies its immediate delegatee’s work and submits attestations upstream.
4. Scalable Coordination: Matching Tasks to the Right Agent
The paper proposes decentralized market-based coordination where agents bid on tasks based on capability and cost. While this sounds like infrastructure for the distant future, a simpler version of this pattern already exists in coding agent architectures.
Claude Code’s orchestrator-worker model uses exactly this principle. The lead agent (Opus) decomposes queries into subtasks and delegates to worker subagents (Sonnet for cost-efficiency). Each subagent gets a focused prompt with clear objectives, output format requirements, tool restrictions, and task boundaries. Anthropic’s own benchmarks show this multi-agent system outperforms a single Opus agent by 90.2% on their internal research eval.
The practical version of market coordination for coding agents today is capability-scoped delegation:
# Claude Code custom subagent — capability-scoped---name: db-migration-specialistdescription: Handles database schema changes and migration scriptstools: Read, Edit, Bash, Grep, GlobpermissionMode: acceptEditshooks: PreToolUse: - matcher: "Bash" hooks: - type: command command: "./scripts/validate-migration-safety.sh"---
You specialize in database migrations. Before making changes:1. Read the current schema2. Check for existing migrations that conflict3. Write reversible migrations only4. Run migration dry-run before committing
You CANNOT modify application code. Only migration files and schema definitions.The key principle: restrict each agent’s blast radius through permission scoping, not just prompt instructions. Telling an agent “don’t modify application code” is fragile. Removing Write access to application directories is structural.
5. Systemic Resilience: Contain Failures Before They Cascade
The paper introduces Delegation Capability Tokens (DCTs) — cryptographic tokens based on Macaroons or Biscuits that enforce least-privilege through “cryptographic caveats.” An agent receives a token allowing READ on a specific resource but forbidding WRITE. Permissions attenuate as they propagate down delegation chains.
This is conceptually identical to how Claude Code’s PreToolUse hooks work today. You can define validation scripts that intercept tool calls and block unauthorized operations:
#!/bin/bash# Block destructive Git operations from subagentsINPUT=$(cat)COMMAND=$(echo "$INPUT" | jq -r '.tool_input.command // empty')
# Block force pushes, hard resets, and branch deletionsif echo "$COMMAND" | grep -iE 'push --force|reset --hard|branch -D' > /dev/null; then echo "Blocked: Destructive git operation not permitted for this agent" >&2 exit 2 # Exit code 2 = block the operationfi
exit 0The paper also proposes algorithmic circuit breakers — automated revocation triggered by reputation drops or anomaly detection. In coding agent terms, this is: if an agent produces three consecutive failing builds, stop delegating to it and escalate.
Where Current Systems Fall Short
The paper evaluates existing protocols and finds gaps that directly affect coding agents:
| Protocol | What It Does Well | What’s Missing |
|---|---|---|
| MCP | Universal tool interface (“USB-C for AI”) | No semantic permissions, no liability tracking |
| A2A | Peer discovery, status streaming | No cryptographic verification of outputs |
| Current agent scaffolds | Basic orchestration | No formal accountability in delegation chains |
The most actionable gap: no current system tracks accountability through delegation chains. When Agent A delegates to Agent B, which sub-delegates to Agent C, and C introduces a bug — who is responsible? The paper proposes transitive accountability with cryptographic attestations. Today’s practical equivalent: structured logging with agent attribution at every checkpoint.
Three Patterns to Implement Now
You don’t need to wait for DCTs or decentralized agent markets. These patterns from the framework are implementable today:
1. Contract-first decomposition. Before delegating any subtask, define the verification criteria. If you can’t write a test or check for it, decompose further.
2. Checkpoint everything. Use Git commits and progress files as checkpoint artifacts. Every agent session should be resumable by a different agent from the last checkpoint alone.
3. Scope permissions structurally. Use tool restrictions and validation hooks, not just prompt instructions, to enforce what agents can and cannot do. Constraints beat instructions.
The paper frames delegation as a first-class concern for the emerging agentic web. For coding agents specifically, the implication is clear: the teams that formalize their delegation patterns — with verifiable contracts, scoped permissions, and checkpoint-based recovery — will build systems that scale. The teams that treat delegation as “just split the task up” will hit the same walls that every flat agent architecture hits.
The gap between AI assistance (60% of developer work) and AI autonomy (0-20% fully delegated) is a delegation engineering problem, not a model capability problem. This framework gives us the vocabulary to close it. For how these delegation patterns manifest in real multi-agent systems, see our analysis of the five architectural primitives every agent swarm rediscovers. And for the broader workflow shift from code author to systems architect, see The New SDLC for Agentic Engineering.
References:
- Tomasev, N., Franklin, M., Osindero, S. (2026). Intelligent AI Delegation. arXiv:2602.11865
- Anthropic. (2026). Eight Trends Defining How Software Gets Built in 2026. claude.com/blog
- Anthropic. (2025). Building Effective Harnesses for Long-Running Agents. anthropic.com/engineering
- SWE-bench Leaderboards. swebench.com
- Claude Code Documentation: Custom Subagents. code.claude.com/docs/en/sub-agents
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.