OpenAI's Agent-First Codebase Learnings
The Experiment
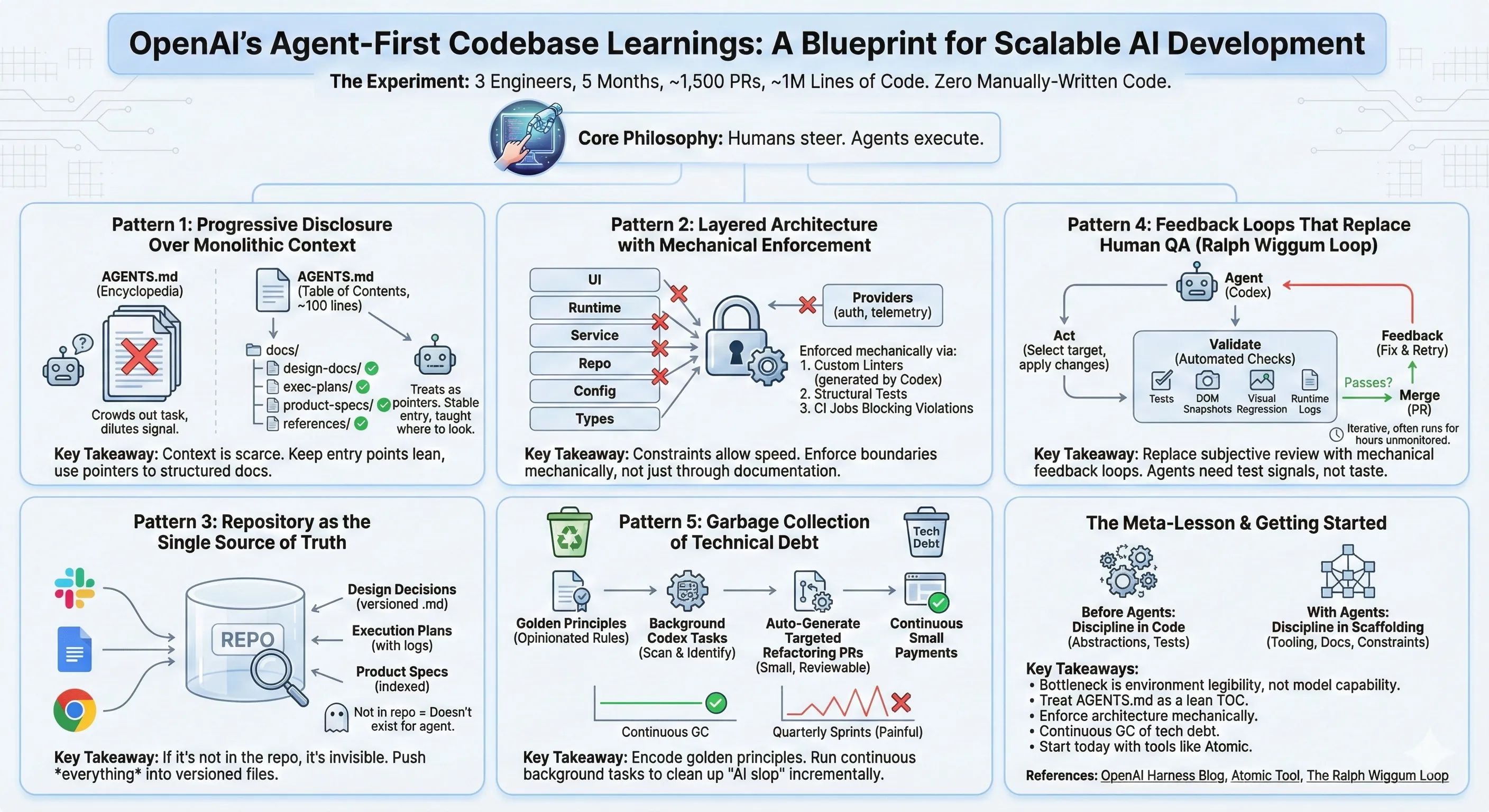
OpenAI’s Harness team ran a 5-month experiment: build and ship a real product with zero manually-written code. Every line—application logic, tests, CI configuration, documentation, observability tooling—was written by Codex agents.
The results are striking. Three engineers produced ~1,500 merged PRs across roughly a million lines of code. The product has daily internal users and external alpha testers. And as the team grew to seven engineers, throughput increased rather than plateauing.
But the interesting part isn’t the output numbers. It’s what broke along the way and the engineering discipline they developed to fix it.
Their core philosophy: Humans steer. Agents execute.
In practice, this meant no engineer ever wrote code directly. When something failed, the response was never “let me fix this by hand.” It was always: “what capability is missing, and how do we make it legible and enforceable for the agent?”
That question—and the patterns it produced—is what this post breaks down.
Pattern 1: Progressive Disclosure Over Monolithic Context
The Harness team’s first instinct was to write one comprehensive AGENTS.md file. It failed predictably:
Context is a scarce resource. A giant instruction file crowds out the task, the code, and the relevant docs—so the agent either misses key constraints or starts optimizing for the wrong ones.
Their solution: treat AGENTS.md as a table of contents (~100 lines), not an encyclopedia. The real knowledge lives in a structured docs/ directory:
AGENTS.md ← ~100 lines, pointers onlyARCHITECTURE.mddocs/├── design-docs/│ ├── index.md│ └── core-beliefs.md├── exec-plans/│ ├── active/│ ├── completed/│ └── tech-debt-tracker.md├── product-specs/│ ├── index.md│ └── new-user-onboarding.md├── references/│ └── design-system-reference-llms.txt├── DESIGN.md├── FRONTEND.md├── PLANS.md└── SECURITY.mdThis is progressive disclosure applied to agent context. The agent starts with a small, stable entry point and is taught where to look next, rather than being overwhelmed up front. These patterns aren’t unique to OpenAI — five independent teams converged on the same findings, as we explore in how harness engineering became the standard. For the developer-facing perspective on applying these techniques, see our guide to building products with agentic-powered IDEs.
Why this matters mechanically
Every token in the agent’s context window that isn’t directly relevant to the current task is noise. A 2,000-line instruction file doesn’t just waste tokens—it actively degrades performance by diluting the signal from task-specific code and documentation.
How to apply this today
If you’re using Claude Code, your CLAUDE.md serves this exact role. Keep it lean. Here’s the pattern from Atomic, which codifies this approach:
# CLAUDE.md — Optimization Checklist# Before finalizing, verify:# - ☐ Under 100 lines (ideally under 60)# - ☐ Every instruction universally applicable to all tasks# - ☐ No code style rules (use linters/formatters instead)# - ☐ No task-specific instructions (use progressive disclosure)# - ☐ Progressive disclosure table pointing to detailed docsThe key insight: anything that’s task-specific or domain-specific gets a pointer, not an inline explanation.
Pattern 2: Layered Architecture with Mechanical Enforcement
The Harness team built their application around a rigid architectural model. Each business domain is divided into fixed layers with strictly validated dependency directions:
Code can only depend “forward” through the layer chain: Types → Config → Repo → Service → Runtime → UI. Cross-cutting concerns (auth, telemetry, feature flags) enter through a single explicit interface: Providers.
The critical word here is enforced. Not documented. Enforced.
# These constraints are enforced mechanically via:# 1. Custom linters (themselves generated by Codex)# 2. Structural tests that validate dependency directions# 3. CI jobs that block PRs violating layer boundariesThis is the kind of architecture teams usually postpone until they have hundreds of engineers. With coding agents, it’s an early prerequisite—the constraints are what allow speed without architectural drift.
The lesson for your codebase
Agents replicate patterns that already exist in the repository—even suboptimal ones. Without mechanical enforcement, bad patterns compound exponentially. The Harness team found that custom linters with remediation-focused error messages worked best because the error message itself becomes part of the agent’s context when it fails:
// Bad: "Error: Invalid import"// Good: "Error: Service layer cannot import from UI layer.// Move this logic to a Provider or restructure// the dependency. See docs/ARCHITECTURE.md#layers"Pattern 3: Repository as the Single Source of Truth
The Harness team articulated a principle that sounds obvious but has deep implications:
From the agent’s point of view, anything it can’t access in-context while running effectively doesn’t exist.
That Slack thread where the team aligned on an architectural pattern? If it’s not in the repo, the agent doesn’t know about it. That Google Doc with the product spec? Invisible.
This forced them to push everything into the repository:
- Design decisions → versioned markdown in
docs/design-docs/ - Execution plans → checked into
docs/exec-plans/with progress logs - Product specs →
docs/product-specs/with indexed navigation - Technical debt → tracked in
docs/exec-plans/tech-debt-tracker.md
Parallels you can adopt
Atomic structures this with a research/ directory that persists agent findings across sessions:
# Research a codebase and generate persistent documentation/research-codebase "How does authentication work in this codebase?"
# The output becomes a versioned artifact:research/├── 2026-02-11-auth-flow.md # Findings with code references├── feature-list.json # Prioritized implementation tasks└── progress.txt # Session-to-session continuityThe research → spec → feature-list → implementation pipeline mirrors exactly what the Harness team built, but packaged as slash commands you can run today:
/research-codebase [question] # Spawn parallel sub-agents to analyze/create-spec [research-path] # Generate a technical design document/create-feature-list [spec-path] # Break spec into ordered, trackable tasks/implement-feature # Execute the next highest-priority itemEach command produces versioned artifacts that become context for future sessions. Research and specs become memory.
Pattern 4: Feedback Loops That Replace Human QA
As the Harness team’s code throughput increased, their bottleneck shifted from writing code to validating it. Their solution was to make the application itself directly legible to the agent.
They wired Chrome DevTools Protocol into the agent runtime so Codex could:
- Launch an isolated app instance per git worktree
- Snapshot DOM state before and after UI interactions
- Capture screenshots for visual regression
- Query runtime logs via LogQL and metrics via PromQL
- Loop: fix → restart → revalidate until clean
This is the Ralph Wiggum Loop—an iterative pattern where the agent acts, checks its work against concrete criteria, feeds the result back into the next attempt, and repeats until success. The Harness team regularly observed single Codex runs working on a single task for six hours straight, often while the engineers slept.
The pattern works because it replaces subjective “does this look right?” with mechanical “does this pass?” The agent doesn’t need taste. It needs test signals.
Making this concrete
Atomic implements a version of this loop via the /ralph:ralph-loop command. It wraps the implementation cycle in an iterative harness:
- Requirements: Extended conversation establishing specs
- Planning loop: Gap analysis generating prioritized tasks
- Building loop: Iterative implementation with automated test validation
The loop runs until objective criteria are met—tests pass, type checks succeed, builds complete. Each iteration spawns fresh context, with memory persisting through filesystem artifacts: git commits, markdown specs, the codebase itself.
Pattern 5: Garbage Collection of Technical Debt
Full agent autonomy introduces a novel problem: agents replicate patterns that already exist—even suboptimal ones. The Harness team initially spent every Friday (20% of their week) cleaning up “AI slop.” That didn’t scale.
Their solution was to encode golden principles directly into the repository and build a recurring cleanup process:
- Define opinionated, mechanical rules (prefer shared utilities over hand-rolled helpers; validate at boundaries instead of probing data “YOLO-style”)
- Run background Codex tasks on a regular cadence that scan for deviations
- Auto-generate targeted refactoring PRs (most reviewable in under a minute)
- Track quality grades per domain and architectural layer
This functions like garbage collection. Technical debt is a high-interest loan—continuous small payments beat painful quarterly sprints.
Human taste is captured once, then enforced continuously on every line of code.
Applying this incrementally
You don’t need a full GC pipeline to start. The minimum viable version:
- Encode one golden principle as a custom lint rule or a note in your agent instructions
- Track deviations in a
tech-debt-tracker.mdfile that agents can read and update - Periodically prompt the agent to scan for violations: “Find all places where we hand-roll a retry loop instead of using our shared utility”
Over time, you build up a library of mechanical checks that compound. Each rule you encode is one less thing you manually review.
The Meta-Lesson: Discipline Shifts From Code to Scaffolding
The deepest insight from the Harness experiment isn’t any single pattern. It’s the fundamental shift in what “engineering discipline” means:
Before agents: Discipline shows up in the code—clean abstractions, good tests, consistent style.
With agents: Discipline shows up in the scaffolding—the tooling, documentation structure, feedback loops, and architectural constraints that keep the codebase coherent while agents generate the code.
The Harness team describes it as leading a large platform organization: enforce boundaries centrally, allow autonomy locally. You care about correctness, reproducibility, and architectural coherence. Within those boundaries, the agent has significant freedom in how it expresses solutions.
The code won’t always match your stylistic preferences. That’s fine. As long as it’s correct, maintainable, and legible to future agent runs, it meets the bar.
Getting Started
If you want to start applying these patterns, here’s a practical entry point:
-
Audit your
CLAUDE.mdorAGENTS.md. Is it under 100 lines? Does it use progressive disclosure? Cut anything task-specific and replace it with a pointer to a dedicated doc. -
Pick one architectural boundary and enforce it mechanically. A single lint rule that prevents imports across layer boundaries is worth more than a page of documentation.
-
Structure your agent workflow as a pipeline: research → spec → implementation → validation. Tools like Atomic provide this pipeline out of the box with slash commands that produce versioned artifacts.
-
Build one feedback loop. Start with “run tests after every change” and expand from there. The Ralph Wiggum Loop pattern—act, check, feed back, repeat—is the foundation.
-
Encode one taste decision as a rule. The next time you fix something an agent got wrong, don’t just fix it. Ask: “Can I make this a lint rule or a documented principle so it never happens again?”
The Harness team’s experiment validates something many of us have felt: the hardest part of working with coding agents isn’t prompting. It’s building the environment where agents can do reliable, sustained work. The good news is that the patterns are learnable, incremental, and available today.
Key Takeaways
- OpenAI’s Harness team shipped ~1M lines of agent-generated code over 5 months with 3 engineers averaging 3.5 PRs/day each
- The biggest bottleneck isn’t model capability—it’s environment legibility. Agents fail when they can’t find or reason about the information they need
- Treat your
AGENTS.md/CLAUDE.mdas a table of contents (~100 lines), not an encyclopedia - Enforce architecture mechanically through linters and structural tests, not documentation alone
- Continuous “garbage collection” of tech debt beats weekly cleanup sprints
- You can start applying these patterns today with tools like Atomic
References
- Harness engineering: leveraging Codex in an agent-first world — OpenAI, Ryan Lopopolo
- Atomic: Ship complex features with AI agents — Open-source tool for research-to-execution agent workflows
- The Ralph Wiggum Loop — Technical breakdown of the iterative agent pattern
- Unlocking the Codex harness: how we built the App Server — Follow-up on the Codex architecture
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.