From RPI to QRSPI: Rebuilding the First Structured Workflow for Coding Agents
Key Takeaways
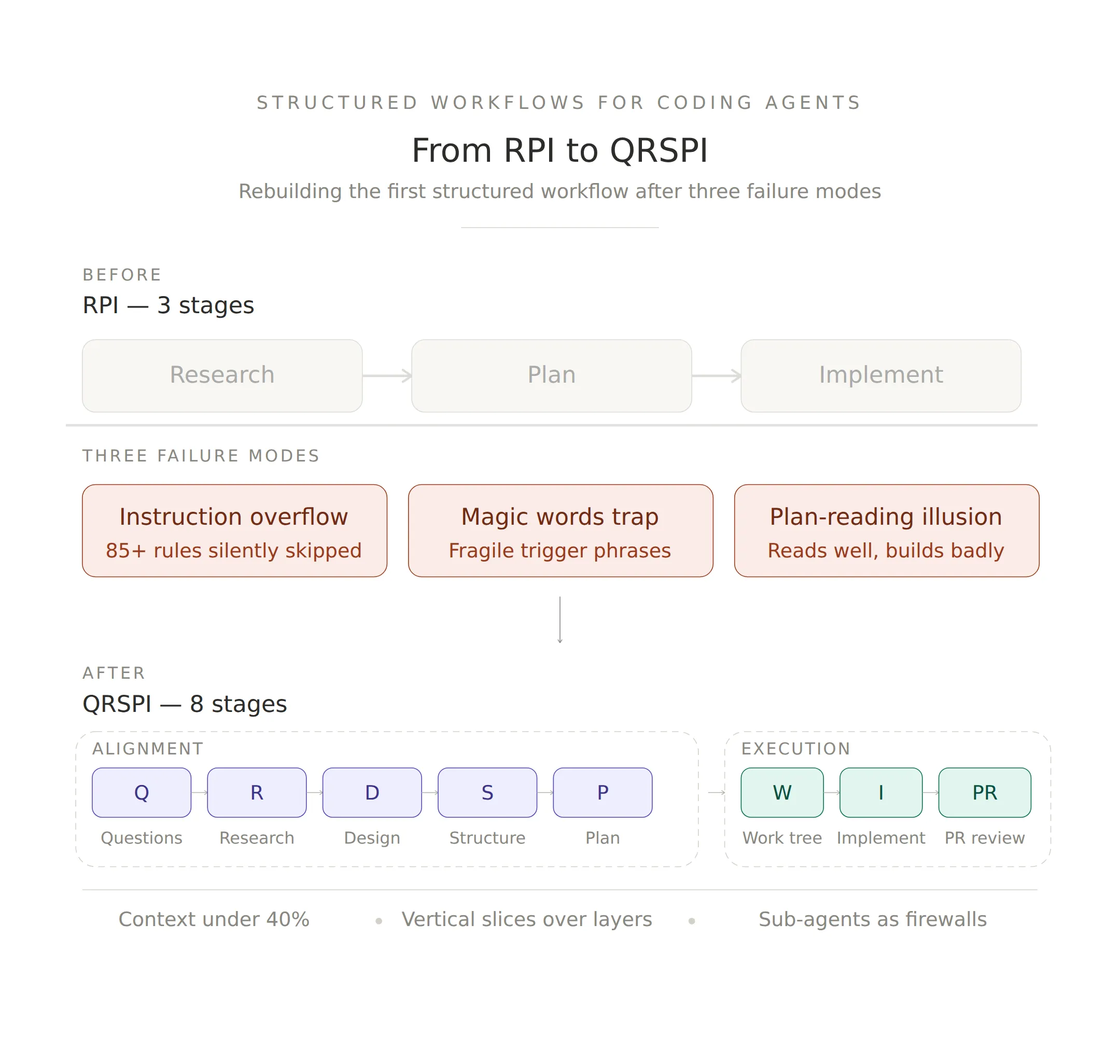
- The first widely-adopted coding agent workflow had to be rebuilt. Dex Horthy’s Research-Plan-Implement (RPI) hit three failure modes — instruction budget overflow, magic word dependencies, and a plan-reading illusion — that only surface at real-world scale.
- QRSPI replaces three stages with eight — five for alignment, three for execution. The key design moves: hide the feature ticket during research so the agent gathers codebase facts without premature opinions, then perform “brain surgery” on the agent’s understanding through structured design discussion before a single line of code is planned.
- Context window utilization has a hard ceiling. Practitioners independently validate the same finding: keep context under 40%, start fresh at 60%. Bigger windows don’t help if you fill them with noise.
- Vertical slices beat horizontal layers for agent work. Mock API → front-end → database with checkpoints produces more reliable outcomes than completing all database work, then all API work, then all front-end work.
- The differentiator is shifting from models to harness configuration. Context management, instruction budgets, sub-agent architecture, and deterministic hooks matter more than which frontier model you’re using.
“A 1,000-line plan contains as many surprises as 1,000 lines of code.”
Dex Horthy (CEO of HumanLayer, YC F24) just publicly reversed one of his own core recommendations. The creator of Research-Plan-Implement — the first structured workflow for AI coding agents that saw independent adoption across DEV Community, Hacker News, and GitHub — rebuilt it from scratch after three failures that only became visible at scale.
The failures are more instructive than the fix. They reveal a pattern that every team building with coding agents will eventually encounter: the techniques that work at demo scale break at production scale, and the failure modes are subtle enough that you don’t notice until significant architectural debt has accumulated.
This post breaks down what broke, what replaced it, and what practitioners are independently validating about where AI-assisted development is headed. For the foundational infrastructure patterns that make these workflows reliable, see our earlier post on harness engineering.
What RPI Was and Why It Mattered
Research-Plan-Implement was deliberately simple: three phases, each with a dedicated Claude Code slash command. Research the codebase to gather context. Plan the implementation by writing a detailed spec. Implement against the plan.
The framework mattered because it solved a real problem. Engineers working with coding agents in 2025 were hitting the same wall: they’d prompt the agent, get plausible-looking code, discover it didn’t integrate with the existing codebase, then spend more time fixing the agent’s output than they would have spent writing it themselves. RPI addressed this by forcing the agent to understand the codebase before writing code.
It worked well enough that adoption happened without marketing. Engineers on DEV Community started building on it after hallucination disasters with unstructured prompting. Hacker News threads referenced it as a known technique. Independent implementations appeared on GitHub.
But wider adoption exposed failure modes that weren’t visible when the framework creator was the primary user.
Three Failures That Forced a Rethink
The Instruction Budget
Frontier LLMs lose consistency after approximately 150-200 instructions in a single prompt. RPI’s system prompt had grown to 85+ instructions across its research, planning, and implementation phases.
The failure mode was silent. The model didn’t error out or refuse. It silently skipped critical alignment steps — the ones buried deepest in the instruction list. The agent appeared to follow the workflow while quietly dropping the constraints that made it reliable. You’d only discover the skipped steps after reviewing the output and noticing the agent hadn’t done something that was explicitly specified.
The lesson: instruction budgets are a real constraint, and they don’t announce themselves. If your agent prompt has grown to dozens of instructions, the model is almost certainly not following all of them. The fix isn’t better prompting — it’s reducing the instruction count by restructuring the workflow so each phase carries fewer directives.
The Magic Words Trap
RPI required users to include specific phrases to trigger correct agent behavior. To get the planning phase to work properly, users had to say something like:
“Work back and forth with me, sharing your open questions and phases outline before writing the plan.”
Without that exact phrasing, the agent would skip the interactive design discussion and jump straight to writing a plan file — producing output that looked right but hadn’t been aligned through conversation.
Horthy’s conclusion was direct: if a tool requires magic words for basic functionality, the tool itself is broken. The user shouldn’t need to know the secret handshake. The workflow should produce correct behavior by default.
The lesson: if your agent workflow depends on users knowing specific trigger phrases, you’ve built a fragile system. The agent’s default behavior — what it does when the user provides a straightforward request — needs to be the correct behavior.
The Plan-Reading Illusion
This was the most insidious failure. Plans felt like progress. The team would review a detailed implementation plan, approve it, and move to implementation feeling confident about the direction.
But plans that read well don’t necessarily build well. Architectural debt accumulated underneath because the plan’s prose was convincing while its technical assumptions were wrong. The agent could write a coherent narrative about how components should interact without actually understanding the existing codebase’s constraints, dependency patterns, or implicit contracts.
The lesson: reading a plan is not the same as validating a plan. Plans are persuasive artifacts by nature — LLMs are very good at producing text that reads as authoritative. The verification mechanism needs to go deeper than “does this plan make sense when I read it?”
QRSPI: The Replacement
The replacement is a framework Horthy calls CRISPY (technically QRSPI) — eight stages that front-load alignment before a single line of code is written. The jump from three to eight sounds like added complexity. It is. But each new stage replaces ad-hoc work that was happening anyway — just happening badly.
Alignment Phases
Questions (q). The process starts by identifying what the agent doesn’t know. A skilled engineer writes questions that force the model to touch all relevant parts of the codebase — moving from a vague ticket to a concrete list of technical inquiries. This is the first defense against the instruction budget problem: instead of cramming alignment into a mega-prompt, it happens through targeted questions.
Research (R). The agent gathers objective facts about the current codebase. The key design move: the original feature ticket is hidden during this phase. The agent traces logic flows and identifies existing endpoints without forming opinions on how to change them. It produces a technical map — not a plan, not a recommendation. A factual record of what the code does, which the human reviews before any implementation thinking begins. This directly addresses the plan-reading illusion: the agent builds a factual record, not a persuasive narrative.
Design Discussion (D). The highest-leverage stage. The agent “brain dumps” its understanding into a ~200-line markdown artifact covering current state, desired end state, and design decisions. The engineer reviews the agent’s proposed patterns. If the agent picks a legacy pattern the team has moved away from, the human performs what Horthy calls “brain surgery” — redirecting the agent toward correct architectural standards before any code is planned. This replaces the magic words trap with an explicit alignment conversation that happens by default, not by incantation.
Structure Outline (S). If the design is “where we’re going,” the structure outline is “how we get there.” Horthy compares it to a C header file — it defines signatures, new types, and high-level phases. This is where vertical slices get enforced: build a mock API, then the front end, then the database, with checkpoints after each slice. Not horizontal plans that can’t be tested until everything is assembled.
Plan (P). The tactical implementation document. Because alignment was achieved during Design and Structure, the engineer only needs to spot-check this rather than performing a deep line-by-line review. By the time you reach this stage, the plan is constrained by design decisions and structure that were already validated — the plan-reading illusion has no room to operate.
Execution Phases
Work Tree. The agent organizes tasks into a manageable hierarchy based on the vertical slices from the Structure Outline. Each branch maps to a testable unit of work.
Implement (I). The agent writes code. Horthy notes that while AI speedups make this phase fast (20 minutes instead of 4 hours in some cases), implementation is a small fraction of the overall feature cycle when you account for alignment and testing. The speed comes from the alignment phases — not from the model writing faster.
Pull Request (PR). Human review of the code. Horthy emphasizes that engineers must read and own the code. No exceptions. But because the team already aligned on Design and Structure documents, reviews are faster and contain fewer surprises. The craft standard: no slop makes it into production.
Three Insights Practitioners Are Validating
These aren’t theoretical. Engineers across multiple teams are arriving at the same conclusions independently.
Context Windows Under 40%
Keep context window utilization under 40%. At 60%, start a fresh session. This holds regardless of how large context windows get.
The intuition is counterintuitive: shouldn’t more context help? In practice, filling the context window with accumulated conversation history, verbose documentation, and tool outputs pushes the model into territory where hallucinations increase, tool calls become malformed, and code quality degrades. For a deeper breakdown of this dynamic, see the smart zone vs. dumb zone analysis in our harness engineering post.
The practical implication: design your workflows around frequent, clean starts rather than long-running sessions. Persist progress to disk — research documents, specs, task lists — then start fresh sessions that load only what’s needed for the current phase.
Vertical Slices Over Horizontal Layers
Structure agent work as vertical slices — mock API → front-end → database with checkpoints — rather than horizontal layers where the agent completes all database work, then all API work, then all UI work.
Vertical slices create natural verification points. After each slice, you have a working end-to-end path that can be tested and reviewed. Horizontal layers defer integration to the end, where the agent is deep in a context window full of accumulated work and least equipped to handle integration complexity.
This also maps to the context management insight: each vertical slice can be a fresh session with clean context, while horizontal layers force long-running sessions with growing context.
Sub-Agents as Context Firewalls
Use sub-agents to isolate context, not to create personas. Expensive models for orchestration and decision-making. Cheaper, faster models for scoped sub-tasks like searching the codebase, running tests, or formatting output.
The key insight: sub-agents aren’t “the researcher” and “the planner” as character roles. They’re context boundaries. Each sub-agent operates in its own context window with only the information it needs. The orchestrating agent receives condensed results, keeping its own context lean. This is the same pattern that made Anthropic’s 100K-line compiler project work — sixteen parallel agents, each specialized, coordinating through filesystem artifacts rather than shared context.
Community Response: Validation and Pushback
The community response to QRSPI has been mixed but deeply engaged — which is itself a signal about where the field is.
Validation. Hacker News engineers confirm context degradation from firsthand experience. The 40% threshold resonates with practitioners who’ve watched agent quality collapse in long sessions. Engineers on DEV Community who adopted RPI independently — often after hallucination disasters with unstructured prompting — recognize the failure modes because they hit the same walls.
Pushback. The framework grew from 3 steps to 8. That’s added complexity for something originally designed to reduce complexity. The concern is legitimate — if the workflow requires too much ceremony, engineers will skip steps, and you’re back to the problems you started with. The counter-argument: the additional steps replace ad-hoc work that was happening anyway. The question is whether making that work explicit and structured produces better outcomes than leaving it implicit.
The deeper engagement pattern: practitioners aren’t debating whether structured workflows are necessary. That argument is settled. They’re debating how much structure and what kind. That’s a maturing discipline.
The Deeper Signal
The evolution from RPI to QRSPI illustrates a pattern that goes beyond any single framework.
Differentiation in AI-assisted development is shifting from which model you use to how you configure and constrain the agent. Context management. Instruction budgets. Sub-agent architecture. Deterministic hooks. Verification pipelines. These are the variables that determine whether an agent produces reliable output or plausible-looking code that quietly falls apart.
The model is the engine. The harness is what makes it work.
And harnesses, like any engineering artifact, improve through iteration. RPI was a good first answer. QRSPI is a better second answer. The fact that it needed to be rebuilt isn’t a failure — it’s exactly how engineering disciplines mature. You ship, you discover where it breaks at scale, and you rebuild with what you learned.
We’re still early. The workflows we’re building today will get rebuilt too. The teams that iterate fastest — informed by real failure data, not theoretical frameworks — will build the most reliable systems.
That’s not a limitation. That’s the process working.
References
- Dex Horthy, “CRISPY / QRSPI Framework Talk”: youtube.com/watch?v=YwZR6tc7qYg
- HumanLayer, “Skill Issue: Harness Engineering for Coding Agents”: humanlayer.dev/blog/skill-issue-harness-engineering-for-coding-agents
- The Humans in the Loop Interview (Mar 26, 2026): thehumansintheloop.substack.com
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.