DAPO: A Case Study with Small Language Models

Introduction
Over the past year, we’ve seen reinforcement-learning-based fine-tuning methods supercharge large language models (LLMs), giving them the ability to “think through” problems step by step. Proximal Policy Optimization (PPO) got us started, then DeepSeek’s Group Relative Policy Optimization (GRPO) showed how you can skip a heavyweight critic network by comparing groups of sampled outputs. Building on that, Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) took things further with:
- Clip-Higher Strategy: separate clipping thresholds for “too small” and “too large” policy updates
- Dynamic Sampling: drop prompts that give no learning signal (all-correct or all-wrong)
- Token-Level Loss: compute gradients per token to avoid bias against long, detailed answers
- Overlong Filtering & Reward Shaping: handle truncated or overly verbose responses more gracefully
Those tricks unlocked better reasoning benchmarks on huge 30-50B-parameter models—so we asked ourselves: can a 0.5B-parameter model learn the same tricks? In this experiment, we applied DAPO to the lightweight Qwen2.5-0.5B and ran ablations to see which pieces really matter when using a smaller language model. For the purposes of this exploration we considered small language models to be less than one billion parameters.
Background
Proximal Policy Optimization (PPO)
PPO is a workhorse policy-gradient algorithm that strikes a sweet spot between stability and simplicity. At each step, it:
- Samples a batch of trajectories
- Optimizes a clipped surrogate objective to keep policy changes small
- Uses only first-order gradients—no expensive second-order trust region calculations
This gives you reliable, DRL-style training without wrestling with hard constraints. PPO’s proved itself on robotics and Atari; we’re now using it to steer LLMs toward better answers.
🤓 Math highlight (clipped objective)
where .
Group Relative Policy Optimization (GRPO)
The DeepSeek paper introduces an innovative approach for enhancing reasoning capabilities in large language models using reinforcement learning, specifically focusing on Group Relative Policy Optimization (GRPO). Unlike conventional RL methods that rely on separate critic models for evaluating policy performance, GRPO reduces computational costs by estimating performance baselines directly from sampled group outputs.
GRPO works by initially sampling multiple outputs from the existing policy model for each input query. The policy is then optimized by maximizing an objective function that compares the current policy outputs against these sampled outputs. This optimization process uses a clipped policy ratio to stabilize training, closely related to PPO, but notably avoids using an additional large-scale critic model. The optimization reward signals in GRPO are derived from both the accuracy and the correctness of the format, encouraging the model to provide correct answers and adhere to structured response formats.
🔍 GRPO loss (high-level)
- Generate answers for each query
- Compute a “pseudo-advantage” by comparing each token’s reward to the group
- Apply a clipped update just like PPO, but no separate critic required
🤓 Math highlight GRPO Loss function
Compared to previous methods, GRPO demonstrates superior efficiency by substantially reducing the requirements and complexity of training resources. DeepSeek’s experimental results show significant improvements in reasoning tasks, outperforming conventional supervised fine-tuning methods. Models fine-tuned with GRPO exhibit strong reasoning capabilities, achieving benchmark performance comparable to industry-leading models like OpenAI’s o1 series. Thus, GRPO represents a highly effective and resource-efficient approach for training advanced reasoning capabilities into LLMs.
Decoupled Clip & Dynamic Sampling Policy Optimization (DAPO)
DAPO keeps the GRPO spirit but adds four critical tricks for stability and diversity:
-
Clip-Higher Strategy
- Use two epsilons () so you don’t squash exploration too aggressively.
-
Dynamic Sampling
- Skip prompts where all answers are identical (all right or all wrong). Pull fresh samples so gradients aren’t wasted.
-
Token-Level Loss
- Instead of averaging at the sequence level (which underweights long, detailed answers), sum up per-token contributions.
-
Overlong Filtering & Reward Shaping
- Mask or softly penalize answers truncated by token limits, and apply a gentle length penalty to discourage rambling without crushing good content.
🤓 Math highlight DAPO Loss function
Together, these tweaks gave DAPO a clear win on the AIME 2024 benchmark, beating GRPO on a 32B-parameter model in half the steps. We wanted to see if those benefits survive down-sizing.
Dr. GRPO – A “Done Right” Revision
Dr. GRPO refines GRPO by removing two subtle biases:
- Length bias: penalizing longer correct answers
- Difficulty bias: skew from question hardness
It replaces group-normalized rewards with a simple “subtract the group mean” advantage:
This brings GRPO closer to vanilla PPO principles—but still without a standalone critic.
Our Setup
Integrating DAPO into TRL
We used the TRL library, the de-facto RL-for-LLM toolkit, and added DAPO’s algorithms as new methods. Since there was no proper implementation of DAPO on TRL, we implemented a basic version of DAPO in the library. This let us spin up ablations by toggling each feature in a few lines of code.
Dataset: GSM8K
We fine-tuned on the OpenAI Grade School Math 8K (GSM8K) dataset. It is a dataset with 8.5K diverse word problems requiring multi-step reasoning. Below is an example of the structure of an instance in the dataset.
{ "question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = $<<48/2=24>>24$ clips in May. Natalia sold 48+24 = $<<48+24=72>>72$ clips altogether in April and May. 72"}Reward Functions
We combined:
- Exact-answer reward (big bonus if final answer matches)
- Format reward (smaller bonus for correct JSON/LaTeX-style structure)
- Partial credits for close or partially correct formats
- Soft length penalties if needed (overlong shaping)
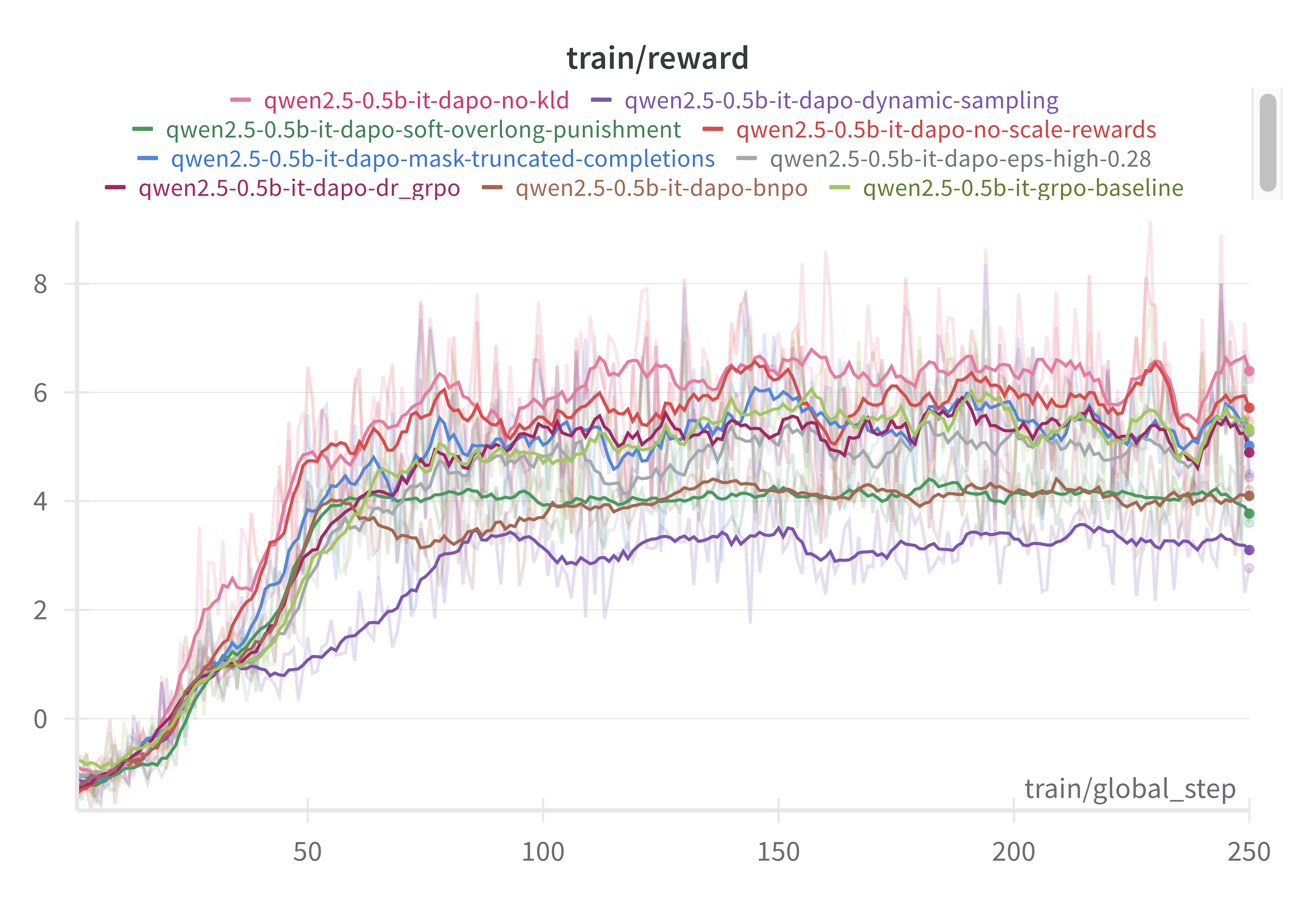
Ablation Studies
We ran 250-step experiments on Qwen2.5-0.5B. Starting from a base GRPO setup, we flipped one switch at a time. The experiments can be viewed here:
| Method | Reward |
|---|---|
| Base GRPO | 7.63 |
| + Overlong Filtering | 8.36 |
| + Clip-Higher | 7.19 |
| + Soft Overlong Punishment | 5.03 |
| + DAPO Token-Level Loss | 5.45 |
| + Dr. GRPO Token-Level Loss | 8.00 |
| + Disable Reward Scaling | 8.13 |
| + Remove KL Divergence | 9.16 |
| + Dynamic Sampling | 4.58 |
DAPO (BNPO) Token-Level Loss
After establishing a baseline, we ran ablation experiments one by one with each of our methods. The first method implemented was DAPO Token-Level loss. While GRPO’s loss is sequence-level, this loss is token-level. Token-level policy loss calculates gradients per token across a batch, unlike sample-level loss which averages per response and can underweight tokens in longer sequences. This approach ensures fairer gradient contributions regardless of response length, improving training stability and providing healthier control over output length dynamics in long-CoT scenarios.
Dr. GRPO Token-Level Loss
In this experiment we changed the loss function to the Dr. GRPO Loss function. This approach removes the length and biases inherent in the original GRPO objective, providing unbiased policy gradients and improving token efficiency by mitigating artificial response length increases.
Disable Reward Scaling
In this experiment we disabled the scaling of rewards by the reward standard deviation, as it has shown to introduce bias. This method was suggested in the Dr. GRPO implementation. The Dr. GRPO paper integrates this with their loss function but we are testing them separately.
Clip-Higher Strategy
The first method implemented was the Clip-Higher strategy. Inside the GRPO loss function, the clip function’s epsilon value is decoupled into epsilon-low and epsilon-high. If epsilon-high is increased, then this increases the probability for low-probability token samples to be selected. This results in the increased diversity of samples.
Overlong Filtering
For this experiment we implement Overlong Filtering. The rewards for all truncated responses are masked. This prevents confusing the model by penalizing a sound reasoning process because the response is too long.
Soft Overlong Punishment
For this experiment we implement a Soft Overlong Punishment to the reward. Consider a punishment threshold . This threshold determines how close to the maximum completion length (number of tokens) a response can be before it is penalized with a soft punishment. Once the response length exceeds the maximum completion length, a hard reward penalty of -1 is applied.
Dynamic Sampling
For this experiment we implement Dynamic Sampling as it is defined in the DAPO paper. If all of a response’s tokens are the same value, then they are filtered out and replaced with a new sample. This helps filter out responses where the model is overconfident on or completely lost on. These responses are replaced with responses where the model can learn more constructively.
Remove KL Divergence Penalty
For this experiment we removed the KL Divergence penalty term. During training of reasoning models, the model distribution may diverge significantly from the initial model, and thus the term may not be necessary.
Key takeaways:
- Dr. GRPO loss, Overlong Filtering, no KL penalty, and no reward scaling all boosted rewards.
- DAPO’s clip-higher, soft overlong punishment, token-level loss, and dynamic sampling actually hurt on this tiny model.
Final Configuration vs. Baseline
Our final recipe for Qwen2.5-0.5B:
- Loss: Dr. GRPO token-level
- Techniques enabled: Overlong Filtering
- Techniques disabled: Reward Scaling, KL penalty, Clip-Higher, Dynamic Sampling, Soft Overlong Punishment
Compared to vanilla GRPO:
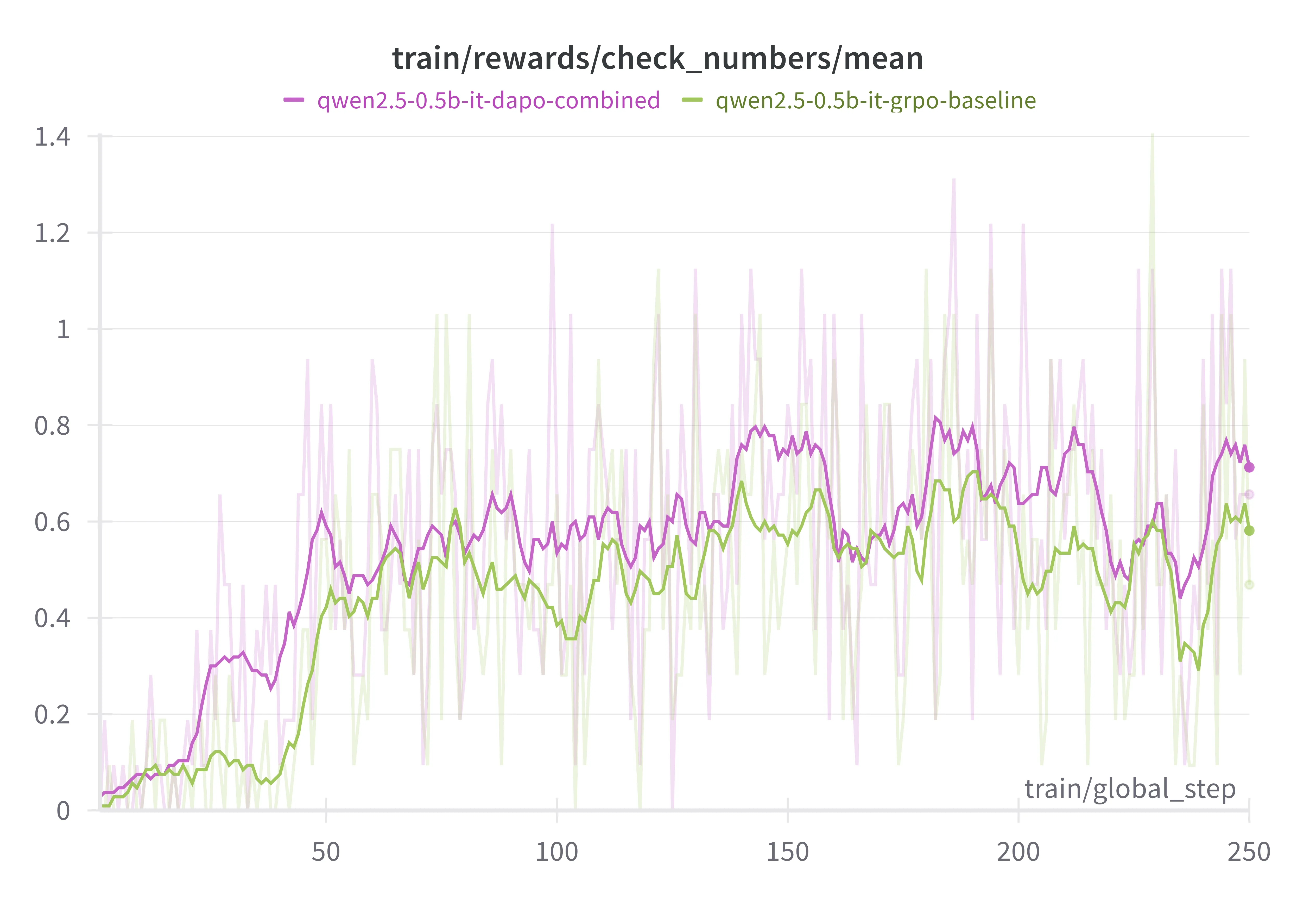
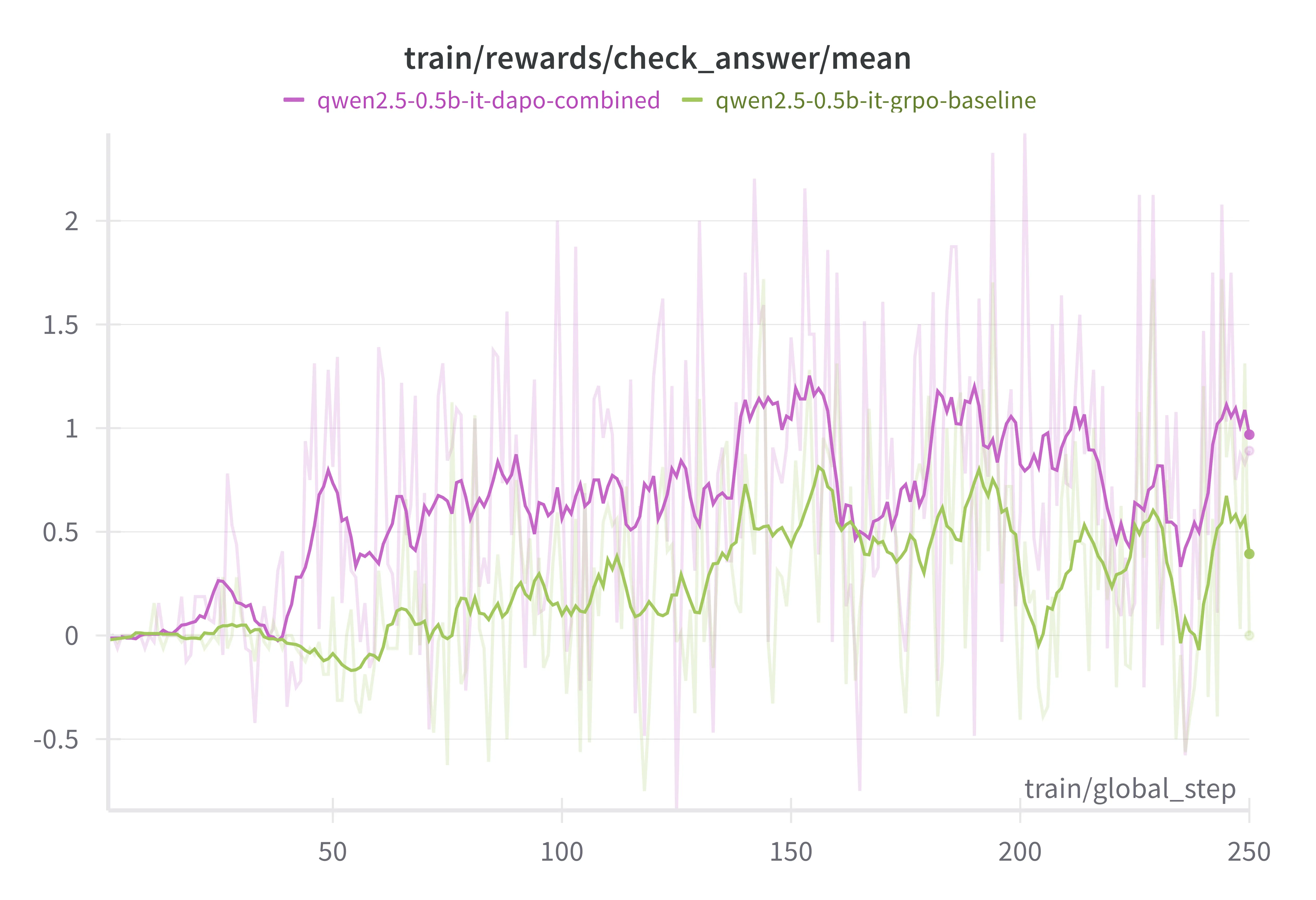
- Numerical accuracy improved steadily.
- Format correctness saw an even bigger lift—a sign our tweaks help the model stay “on-script” with answer formatting.
Results
Here is a test question:
Question: John runs a telethon to raise money. For the first 12 hours,he generates $5000 per hour. The remaining 14 hours,he generates 20% more per hour. How much total money does he make?
Answer: 144000Here is the full reasoning-style answer output by the model:
Response:<start_working_out> John generates $5000 per hour for the first 12 hours, so that’s $5000 × 12 = $60000. For the remaining 14 hours, 20% more per hour means $5000 × 20% = $1000 extra, so $5000 + $1000 = $6000 per hour. Over 14 hours that’s $6000 × 14 = $84000. In total: $60000 + $84000 = $144000.<end_working_out><SOLUTION>144000</SOLUTION>Discussion
- Dr. GRPO is surprisingly powerful on small models—removing that sequence-length bias really matters.
- Overlong Filtering prevents punishing good reasoning just because you hit a token cap.
- DAPO’s fancy token-level loss and dynamic sampling might be overkill (or need retuning) when parameters are limited.
- We suspect that tiny models benefit more from bias-fixing and stability tweaks than from aggressive exploration strategies.
Instruction Tuning Is Crucial
We found that the quality of the base instruction-tuned model shapes everything downstream. For instance, when we tried Google’s Gemma 3 1B (with a lighter instruction-tuning regimen), fine-tuned outputs often derailed into gibberish by the end of the reasoning trace. In contrast, the Qwen family—already robustly instruction-tuned on reasoning datasets—delivered crisp, human-readable step-by-step answers right out of the gate. This suggests tiny-model DAPO is only as good as your starting point.
Precision & Attention Kernels
We also observed that mixed-precision (bfloat16 vs. fp16) and attention implementation (SDPA vs. FlashAttention2) can make or break training stability—worth tuning alongside your RL tricks.
Conclusion & Future Work
- Small-scale DAPO isn’t just a “big-model only” party. With the right subset of techniques (Dr. GRPO, overlong filtering, no KL/reg scaling), you can teach a 0.5B-parameter model to reason effectively.
- Next steps: compare against Group Policy Gradient (GPG), a minimal RL objective for LLMs, and explore curriculum scheduling on prompt difficulty.
Feel free to clone, tinker, and let us know what works—or doesn’t—at small scale!
👥 Collaborators
- Zach Gentile (Boston University)