MotionGPT 1.5
Introduction
The field of computer vision has witnessed significant advancements in the development of photorealistic avatars for various applications, including virtual reality, gaming, robotics, and medicine. However, generating realistic and seamless human motion compositions remains a challenging task due to the complex nature of human movement and the lack of datasets providing long motion sequences with diverse textual annotations.
Recent works have explored different approaches to address this problem. FlowMDM, a pioneering diffusion-based model, introduced Blended Positional Encodings (BPE) and Pose-Centric Cross-Attention (PCCAT) to generate smooth and realistic motion compositions without the need for post-processing or additional denoising steps. The model achieves state-of-the-art results on the HumanML3D and Babel datasets. Additionally, FlowMDM introduces two new metrics, Peak Jerk (PJ) and Area Under the Jerk (AUJ), to better assess the smoothness and realism of generated motion compositions.
Another notable work is MotionGPT, a unified motion-language model that handles multiple motion-relevant tasks by treating human motion as a specific language. MotionGPT employs discrete vector quantization to transfer 3D motion into motion tokens, enabling language modeling on both motion and text in a unified manner. The model achieves state-of-the-art performances on tasks such as text-driven motion generation, motion captioning, motion prediction, and motion in-between.
However, FlowMDM struggles with very complex descriptions and does not generalize well to out of distribution motions. This makes it hard to adapt to new motion generation applications. Additionally, FlowMDM is not powered by natural language descriptions, making it difficult to integrate in multimodal language models. Additionally, MotionGPT struggles to generate effective 3D motions via qualitative analysis, perhaps overfitting to the training dataset. By using a hybrid approach of combining aspects of FlowMDM and MotionGPT, we are able to improve generalizability of human composition models while providing greater accessibility to these systems via natural language-powered descriptions.
Building upon the groundbreaking work of FlowMDM and MotionGPT, we introduce MotionGPTv1.5, a language-enhanced human motion composition model that pushes the boundaries of seamless and realistic motion generation. Our approach makes the first steps to leverage the motion generation pipeline of these models and incorporates natural language text prompts to improve performance on out-of-distribution data.
By utilizing a language model to effectively prompt the motion generation backbone, MotionGPTv1.5 can generate more diverse and coherent motion compositions, even when faced with novel or unseen scenarios. The integration of natural language prompts allows for a more intuitive and user-friendly interface, enabling users to guide the motion generation process with simple textual descriptions as well as better generalizability to extrapolated motions.
Method
Our method works like the following (as summarized in the figure below).
- A user inputs a natural language prompt to interact with an off-the-shelf LLM (Llama 3 in our case). The user’s query is converted to an embedding and compares the similarity of the word embedding to relevant motions that FlowMDM was trained on which are stored in a vector database. The matching word embeddings in the vector database are then injected into the following system prompt for the LLM with a
{motion_dictionary}placeholder key that allows the model to contextualize the actions that the model, FlowMDM, was conditioned on. The assumption here is that FlowMDM has been sufficiently trained on a reasonable set of “base actions” that can be combined to produce a more complex action. - The LLM will generate an output a JSON object depending on the user’s request like the following (note that
<motion>and</motion>special tokens surround the JSON text to appropriately parse the following). In this stage, since the model has no prior knowledge of the required durations of each action, we omit the generation of action durations. This can optionally be included with a reasonable prompt as well, but we choose to fine-tune a custom motion duration prediction model with DistilBERT, yielding reasonable results. We have found that the model does not struggle at all to produce the expected format.
{ "text": [ "stand", "lift right leg", "move right leg away from left leg", "lower right leg" ]}- As explained previously, LLMs provide arbitrary information when asked to guess the duration of each motion of an exercise, so we fine-tune DistilBERT with a lightweight LSTM output layer proceeding the final hidden layer of BERT. We then proceed with a token regression task to predict the duration for each motion in seconds. For more information please refer to the supplementary code and the file in the repo.
- Finally, the output of DistilBERT is post-processed back to the word resolution by averaging the durations of the same word id for a given token because of how tokenization is handled by BERT. The duration is then scaled by the frames per second of our video (in this case 30 fps) yielding a final output that looks like this:
{ "text": [ "stand", "lift right leg", "move right leg away from left leg", "lower right leg" ], "lengths": [67, 94, 176, 91]}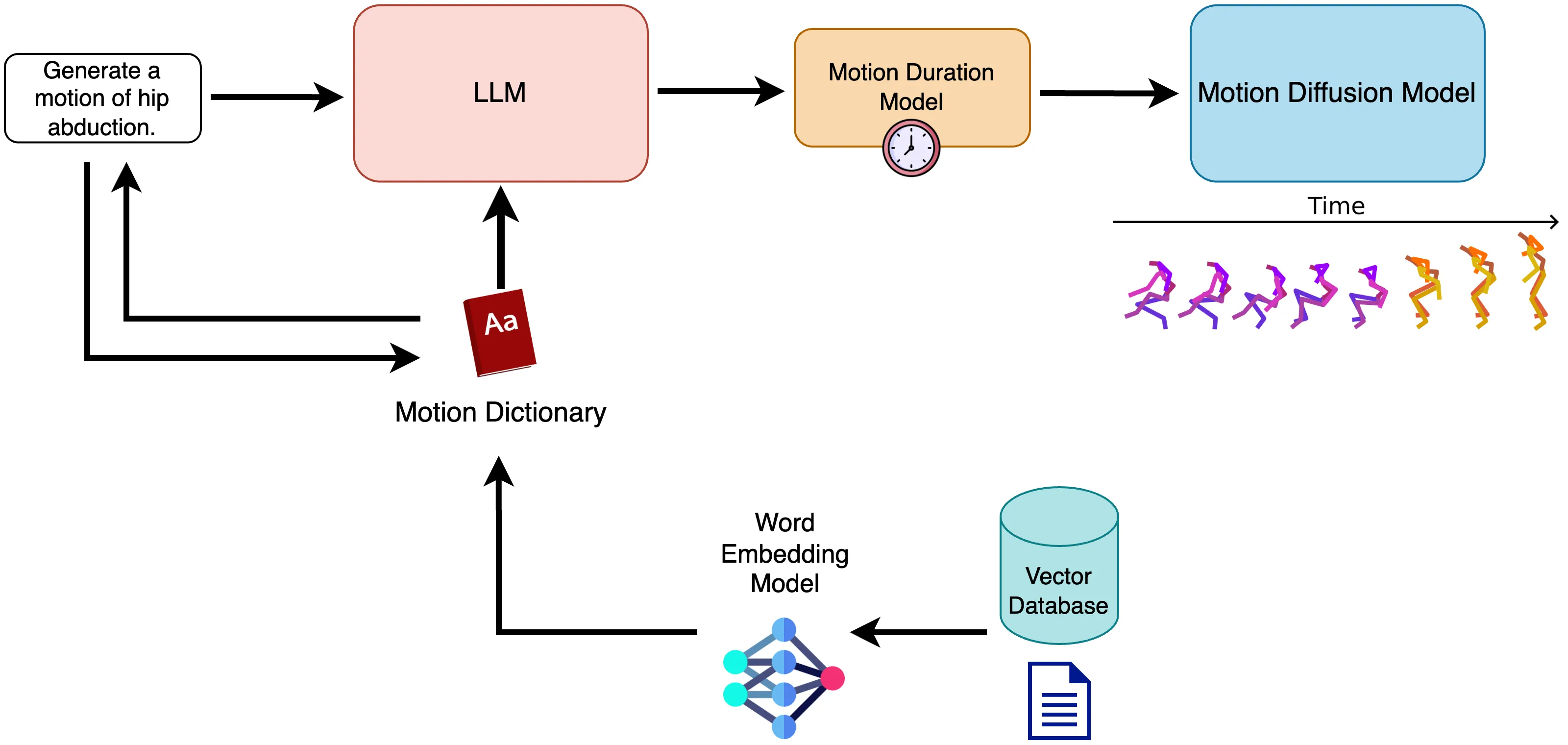
Results
MotionGPTv1.5 Generated Motion
Here is the same example for hip abduction on MotionGPTv1.5 using the user prompt: Can you generate the hip abduction motion?
Failure Cases of FlowMDM and MotionGPT
FlowMDM produces a similar failure case as well for the same hip abduction exercise:
{ "text": ["hip abduction"], "lengths": [300] # number of frames to generate at 30fps}For instance hip abduction, a common physical therapy exercise is not well supported by MotionGPT as seen below:
# Exercise: Hip Abduction
# Prompt:Stand straight, hold support. Lift one leg sideways, keep straight. Return leg. Alternate sides. Repeat.The results are obviously not ideal, but MotionGPTv1.5 is better than out-of-the-box for these models.
Applications
Assistive Physical Therapy Chatbot
One neat application is the ability of MotionGPTv1.5 to aid in the rehabilitation process of patients. Although very preliminary (not perfect), by improving motion generation and language models generalizability to new motions, we can naturally adapt them to represent unseen and more complex motions.
Conclusions
In conclusion, MotionGPTv1.5 represents a first step forward in the field of language-enhanced human motion composition. By building upon the existing frameworks of FlowMDM and MotionGPT, it offers improved performance on out-of-distribution data and more intuitive user interaction. While there remain challenges to overcome, particularly in the generation of complex and unseen motions, the progress made by MotionGPTv1.5 is promising. The potential applications, such as in physical therapy, highlight the value of further research and development in this area. We look forward to the continued evolution and refinement of this model.
👥 Collaborators
- None