The Rise of Edge AI — A New Layer in the Coding Agent Stack
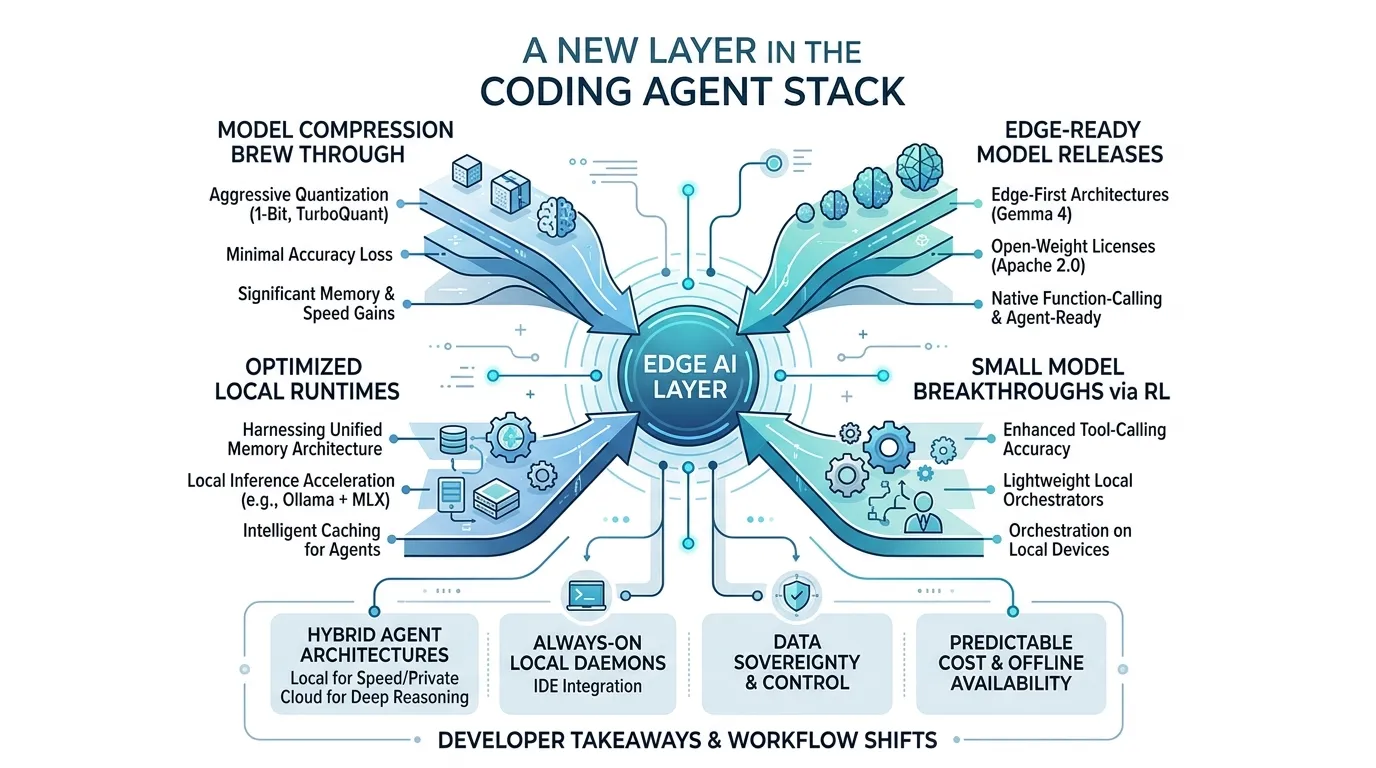
Key Takeaways
- Compression breakthroughs are collapsing the hardware barrier. TurboQuant achieves 6x memory reduction with zero quality loss, and PrismML’s 1-bit Bonsai 8B fits a competitive model in 1.15 GB — 14x smaller than its 16-bit equivalent. Models that required data center GPUs now run on a MacBook Pro or even a phone.
- Edge AI is earning a permanent place in the coding agent stack, not replacing the cloud. The open-source capability gap has closed to roughly three months. Gemma 4 ships edge-first with native function-calling under Apache 2.0, and Reflection AI’s $2.5B raise signals that enterprises and infrastructure providers are investing in locally-deployable coding models as a complement to cloud services.
- Reinforcement learning is making tiny models genuinely useful for agent orchestration. LiquidAI’s 350M-parameter model — 1/20th the size of GPT-2 — achieves over 95% accuracy in multi-turn tool-calling, running on hardware as small as a Raspberry Pi. Tool use is the capability that separates a coding agent from a chatbot, and it no longer requires billions of parameters.
- The local runtime is being purpose-built for coding agents. Ollama’s MLX integration delivers 2x faster decode on Apple Silicon with caching designed specifically for agentic coding patterns — long, iterative conversations with repeated file context.
- A fully edge-native coding stack is viable today for cost-constrained and regulated environments. When local inference is free at the margin, the question shifts from “is edge good enough?” to “why am I paying for something I can run myself?” — and for air-gapped or compliance-bound teams, edge AI isn’t a fallback, it’s the only way AI enters the workflow.
The next major shift in coding agents isn’t about replacing the cloud. It’s about complementing it — from your own hardware.
Today, the most capable coding agents — Claude Code, Codex, Copilot — route every keystroke through remote inference servers. The assumption baked into the entire ecosystem is that frontier-quality AI requires frontier-scale hardware, which means renting compute from someone else. That assumption still holds for the hardest reasoning tasks. But a cascade of breakthroughs in the first quarter of 2026 is opening up a parallel track: model compression, edge-optimized releases, local runtime optimization, and reinforcement learning for small models are converging to make local AI not just possible, but genuinely useful for a growing class of developer workflows.
Edge AI isn’t arriving to kill the cloud. It’s emerging as its own category — one that earns a permanent place in the development stack for specific, high-value scenarios where latency, privacy, cost, or availability matter more than peak reasoning power.
This post walks through the evidence — paper by paper, release by release — and maps out the scenarios where edge AI will be the preferred choice for developers building and using coding agents. The audience is software engineers who use these tools daily, whether or not you’ve ever read a machine learning paper.
The compression revolution: making big models edge-ready
The most direct path to edge AI is making existing models smaller without making them dumber. Two breakthroughs in early 2026 moved the needle dramatically, bringing frontier-class capabilities within reach of consumer hardware.
Google’s TurboQuant: 6x memory reduction, zero quality loss
Google Research revealed TurboQuant[1] in March 2026 — a compression algorithm that reduces the memory footprint of large language models while boosting speed and maintaining accuracy. The technique targets the key-value cache, which Google describes as a “digital cheat sheet” storing previously computed attention states so the model doesn’t recompute them from scratch.
TurboQuant is a two-step process. First, PolarQuant converts the traditional Cartesian vector representation into polar coordinates — reducing each vector to a radius (data strength) and direction (semantic meaning). Google’s analogy: instead of “go 3 blocks East, 4 blocks North,” you say “go 5 blocks at 37 degrees.” Less data, same destination, and no expensive normalization steps. Second, a technique called Quantized Johnson-Lindenstrauss applies a 1-bit error-correction layer, reducing residual quantization noise while preserving the distance relationships that attention scores depend on.
The numbers: 6x memory reduction in the KV cache with perfect downstream accuracy across long-context benchmarks using both Gemma and Mistral models. Computing attention with 4-bit TurboQuant runs 8x faster than 32-bit unquantized keys on NVIDIA H100 accelerators. And critically, TurboQuant quantizes to 3 bits with no additional training — it can be applied to existing models off the shelf.
For software engineers, here’s the translation: a model that previously required 48 GB of VRAM could fit in 8 GB. That’s the difference between a data center GPU and a MacBook Pro.
Caltech/PrismML: 1-bit models on your phone
If TurboQuant is aggressive, PrismML’s work — emerging from breakthrough research at Caltech[2] — is radical. They’ve achieved true end-to-end 1-bit quantization: embeddings, attention layers, MLP layers, and the language model head are all compressed to a single bit per parameter. No higher-precision escape hatches.
The result is their Bonsai 8B model[3]: a model that competes with leading 8-billion-parameter models while occupying just 1.15 GB — 14x smaller than its 16-bit equivalent. PrismML measures this with an “Intelligence Density Score” of 1.06 per GB, compared to Qwen3 8B’s 0.10 per GB. That’s a 10.6x improvement in intelligence per unit of memory.
What does this look like in practice? The Bonsai 8B runs at approximately 40 tokens per second on an iPhone 17 Pro and 131 tokens per second on an M4 Pro Mac — with an energy cost of just 0.068 mWh per token on the iPhone 17 Pro Max.
An 8B-class model, competitive on benchmarks, running at interactive speeds on a phone. A year ago, that was a research fantasy.
The edge-ready model wave: from cloud-only to run-anywhere
Compression makes models smaller. But the edge story isn’t just about shrinking existing models — it’s about an entire class of models being designed, released, and optimized for local deployment. Open-weight releases, edge-first architectures, and purpose-built small models are all expanding what’s possible without a cloud connection.
The capability gap is closing fast
Dave Friedman’s analysis[4] quantifies the trend. In 2023, closed-source models scored approximately 88% on MMLU benchmarks while open models managed 70.5% — a meaningful gap. By 2026, that gap is effectively zero on knowledge benchmarks and single digits on most reasoning tasks. Open-source models now trail the state of the art by approximately three months, down from roughly a year in late 2024.
The efficiency story is equally compelling. DeepSeek’s V3 model used 2.6 million GPU hours versus Llama 3 405B’s 30.8 million — a tenfold efficiency improvement for comparable performance. DeepSeek’s R1 reasoning model matched OpenAI’s o1 at roughly 3% of the cost.
For edge AI, the implication is direct: the models available for local deployment are no longer second-tier. Many of the tasks developers perform daily — code completion, documentation, refactoring, test generation — fall well within the capability range of models that can run on consumer hardware. The cloud retains its advantage for the hardest reasoning tasks, but the floor of “good enough for local” keeps rising.
With LLM inference costs dropping roughly 10x annually and edge-capable models improving every quarter, the set of tasks that require cloud inference is shrinking. Cloud APIs will continue to lead on frontier reasoning, complex multi-step planning, and large-context tasks — but the everyday development workflows that consume the most tokens are increasingly viable on local hardware.
Gemma 4: edge-first by design
Google’s Gemma 4 release[5] in April 2026 is a landmark for the edge AI category. The Gemma 4 family ships in four sizes — E2B, E4B, 26B MoE, and 31B Dense — under an Apache 2.0 license, with the smaller variants explicitly designed for on-device deployment.
The performance is no longer “good for a local model.” It’s simply good. The 31B model is the #3 open model in the world on the Arena AI text leaderboard. The 26B MoE is #6, outcompeting models 20x its size. The MoE architecture activates only 3.8 billion of its 26 billion total parameters during inference — frontier-level reasoning at a fraction of the compute cost.
For edge deployment specifically, Gemma 4’s E2B and E4B models run completely offline with near-zero latency across phones, Raspberry Pi, and NVIDIA Jetson Orin Nano. They feature 128K context windows, native multimodal capabilities (vision, audio), and — critically for coding agents — native function-calling, structured JSON output, and system instructions. These aren’t toy models. They’re agent-ready and edge-first, representing a new design philosophy: models built for the edge from the ground up, not cloud models shrunk down as an afterthought.
Reflection AI: $2.5 billion bet on deployable coding models
The capital markets are backing the edge thesis. Reflection AI, founded in 2024 by former DeepMind researchers Misha Laskin and Ioannis Antonoglou, is raising $2.5 billion at a $25 billion valuation[6] — backed by NVIDIA and JPMorgan Chase. The company’s valuation went from $545 million to $25 billion in under 12 months. A 46x increase.
Reflection builds open-weight models focused explicitly on automating software development — AI systems that write, test, and maintain code. Positioned as “the DeepSeek of the West,” they’re building a model network for enterprises, research institutions, and universities — models designed to run on your infrastructure, not just through an API.
When NVIDIA pours nearly a billion dollars into a coding AI lab building locally-deployable models, and JPMorgan participates through its Security and Resiliency Initiative, the strategic message is clear: edge-deployable AI models aren’t a research curiosity. They’re a category that enterprises, governments, and infrastructure providers are investing in as a complement to cloud-based AI services.
The small model breakthrough: RL changes everything
Compression makes big models edge-ready. Open weights and edge-first architectures give you deployment flexibility. But the third force might be the most surprising: small models are getting dramatically smarter through reinforcement learning.
LiquidAI: a 350-million-parameter model that can use tools
LiquidAI’s LFM 2.5 350M[7] is a 350-million-parameter model — roughly 1/20th the size of GPT-2 — that delivers performance previously associated with models many times its size. The key innovation is applying large-scale reinforcement learning to a small model after expanded pre-training (28 trillion tokens, up from 10 trillion).
The results redefine what “small” means:
- 76.96% on IFEval (instruction following), up from 64.96% in the previous version
- 44.11 on BFCLv3 (tool use), roughly double the prior version’s 22.95
- Over 95% accuracy in multi-turn tool-calling interactions across smart home, banking, and terminal use cases
- Runs at 40,400 tokens per second on an NVIDIA H100, and inference works on everything from a Raspberry Pi 5 to an Apple M5 Max
A 350-million-parameter model with reliable tool use. Think about what that means for coding agents. Tool use — calling functions, reading files, executing shell commands — is the foundational capability that separates a coding agent from a chatbot. If a model small enough to run on a Raspberry Pi can reliably call tools, the minimum hardware bar for a useful coding agent drops to essentially nothing.
LiquidAI’s model isn’t recommended for complex math, code generation, or creative writing — those tasks still demand larger models. But for the orchestration layer — deciding which tools to call, in what order, with what arguments — a 350M model with strong tool-calling accuracy could serve as a lightweight local coordinator that dispatches heavier tasks to larger models only when necessary.
The runtime is ready: Ollama’s Apple Silicon moment
Models don’t run in a vacuum. They need runtime infrastructure optimized for local hardware. Ollama’s March 2026 update[8] delivered exactly this.
Ollama 0.19 is now built on Apple’s MLX framework, directly leveraging the unified memory architecture of Apple Silicon. The performance gains are substantial: 1.6x faster prefill and roughly 2x faster decode speed compared to the previous version. On M5-series chips, Ollama taps the new GPU Neural Accelerators for further acceleration.
But the most telling detail is what Ollama chose to optimize for. Their announcement explicitly names coding agents — Claude Code, OpenCode, Codex — as the primary beneficiaries. The new caching system reuses context across conversations, stores intelligent checkpoints within prompts, and implements smarter eviction policies where shared prefixes survive longer. These are features designed specifically for the pattern of agentic coding: long, iterative conversations where the model keeps returning to the same files and context.
The infrastructure layer is no longer an afterthought. The local runtime is being purpose-built for coding agents — a clear signal that edge AI is maturing from experiment to product category.
The trust and control gap: where edge AI earns its place
There’s a reason edge AI matters that goes deeper than latency and cost. Stanford’s 2026 AI Index[9] quantified a growing disconnect: only 10% of Americans say they’re more excited than concerned about AI, compared to 56% of AI experts. On whether AI will help with jobs, 73% of experts say yes — only 23% of the public agrees.
This trust gap creates real demand for alternatives. Frontier models like Anthropic’s Mythos are expensive to serve, and AI power demand is now comparable to Switzerland’s entire national electricity consumption. For developers and organizations who need AI capabilities but have concerns about data sovereignty, cost predictability, or availability, cloud-only isn’t always the right answer.
This is precisely the market that edge AI serves. It’s not about choosing sides in a cloud-versus-local debate — it’s about recognizing that different scenarios call for different deployment models:
- Data-sensitive development: When working with proprietary codebases, regulated data, or pre-disclosure work, local inference means your code never leaves your machine.
- Cost-predictable workflows: For high-volume, routine tasks (linting, code completion, documentation), local models eliminate per-token costs entirely.
- Offline and low-latency scenarios: Air-gapped environments, travel, unreliable networks, or latency-sensitive workflows where round-trip times to a cloud API are unacceptable.
- Developer autonomy: The ability to fine-tune, customize, and control the model stack without vendor dependency.
Edge AI isn’t replacing cloud AI. It’s filling gaps that cloud AI structurally cannot — and giving developers more options in how they architect their workflows.
Predictions: how edge AI reshapes the coding agent stack
Here’s where the evidence points. These aren’t about cloud AI disappearing — they’re about a new layer emerging alongside it, with its own strengths and use cases.
1. Hybrid agent architectures become the default
Coding agents will increasingly run a lightweight local model for orchestration, tool-calling, and context management, while dispatching complex reasoning tasks to cloud models when the task demands it. LiquidAI’s 350M model demonstrates that tool-calling reliability doesn’t require billions of parameters. Gemma 4’s E4B shows that meaningful code understanding fits in a phone-sized footprint. The architecture will be hybrid by design — local for speed, cost, and privacy; cloud for frontier reasoning when needed.
2. The always-on local coding daemon emerges
Today, you start a coding agent session that connects to a remote API. Within two years, your IDE will also ship with a background process — a daemon — running a compressed model locally, always warm, always available. Ollama’s caching improvements (cross-conversation reuse, intelligent checkpoints) are the early infrastructure for exactly this pattern. This local daemon handles the fast, repetitive work — completions, refactors, linting suggestions — while cloud agents remain available for deep reasoning and complex multi-file tasks.
3. Edge creates a new cost tier for AI-assisted development
As compression techniques like TurboQuant and Bonsai-style 1-bit quantization make local inference effectively free, a new pricing tier emerges: tasks that can run locally cost nothing at the margin. This doesn’t eliminate cloud AI’s value proposition — frontier reasoning, large-context synthesis, and model-as-a-service convenience remain worth paying for. But for the high-volume, routine tokens that make up the majority of a developer’s daily AI usage, local inference is a compelling alternative. The strategic differentiation shifts toward which tasks each deployment model handles best.
4. Data sovereignty becomes a first-class developer concern
When a coding agent can run locally, proprietary code never has to leave your machine. For enterprises in regulated industries — finance, healthcare, defense — this unlocks AI-assisted development in contexts where cloud APIs were never an option. For individual developers, it means control over what data is shared and with whom. “Runs locally” will become a first-class feature in coding tool evaluations, not just a nice-to-have.
5. Edge-optimized coding models become a distinct category
Reflection AI is raising $2.5 billion specifically to build deployable models for automated software development. Gemma 4 already ships with native function-calling and code generation in edge-friendly form factors. The trajectory is clear: by mid-2027, models fine-tuned specifically for coding, compressed to run on consumer hardware, and wrapped in polished local agent harnesses will be a recognized product category — not replacements for cloud coding agents, but purpose-built alternatives optimized for the scenarios where local deployment wins.
6. Some developers go fully edge — and never look back
The preceding predictions frame edge AI as a complement to the cloud. But for a meaningful segment of developers, edge won’t just be one layer — it will be the entire stack. The evidence already supports it: Bonsai 8B delivers competitive code understanding in 1.15 GB. Gemma 4’s E4B provides native function-calling, 128K context, and structured output — everything a coding agent needs to operate autonomously. LiquidAI’s 350M model handles tool orchestration on a Raspberry Pi. Ollama’s runtime is purpose-built for agentic coding patterns. Stack these together and every component of a self-contained coding agent — orchestration, code comprehension, tool use, and runtime — runs on consumer hardware today.
Two populations will drive this shift. First, cost-constrained developers — indie builders, students, and developers in emerging markets where per-token API costs are a real barrier. When local inference is free at the margin, the calculus isn’t “is edge good enough?” — it’s “why am I paying for something I can run myself?” Second, developers in regulated and air-gapped environments — defense contractors, healthcare organizations bound by HIPAA, government agencies with no external network access. For them, “cloud is not an option” isn’t a preference; it’s a hard constraint. Full-edge AI doesn’t just complement their workflow — it’s the only way AI enters their workflow at all.
The natural objection is that models alone aren’t enough — that cloud coding agents like Claude Code and Codex derive their real advantage from the harness, not just the model. The harness is the orchestration layer: the tool-calling logic, the context management, the workflow patterns that turn a raw model into a useful coding partner. And today, that’s a real advantage. But it’s an eroding one. The developer community is rapidly learning how to build its own harnesses — open-source agent frameworks, custom tool integrations, workflow automation that codifies exactly how a specific engineer or team works. Every month, more developers ship their own agentic workflows tailored to their stack, their codebase, their preferences. Simultaneously, the models themselves are getting better at leveraging these harnesses. A more capable local model doesn’t just generate better code — it follows tool-calling conventions more reliably, handles multi-step workflows with less hand-holding, and recovers from errors more gracefully. The harness becomes easier to build and more effective to run as model quality improves. The result: the gap between a polished cloud agent’s harness and what a motivated developer can assemble locally is closing from both directions.
This won’t be the default path for most developers. Cloud agents will retain clear advantages in frontier reasoning, massive-context synthesis, and zero-setup convenience. But the floor of “good enough for a full day’s work” is rising fast. By late 2027, a developer with a modern laptop and no internet connection will be able to run a coding agent that handles completions, refactors, test generation, documentation, and tool-calling — all locally, all free. For the populations where cost or compliance makes cloud untenable, that’s not a consolation prize. It’s a better fit.
A new layer in the stack
Every layer of the stack is converging on the same conclusion: edge AI is ready to be a real part of the development workflow. Compression researchers are proving you can shrink models 14x without meaningful quality loss. Google is releasing edge-first models under Apache 2.0. A startup valued at $25 billion is building locally-deployable coding AI. Apple’s own ML framework is being wired directly into local agent runtimes. A 350-million-parameter model can reliably call tools. And developers are increasingly asking for options beyond cloud-only.
These aren’t independent trends. They’re the emergence of a new market category: edge AI for software development.
For software engineers, the implication is practical. The coding agent stack you use a year from now will likely include both cloud and local models, each handling the tasks they’re best suited for. Cloud APIs aren’t going anywhere — frontier reasoning, massive-context synthesis, and the convenience of hosted inference remain valuable. But alongside them, a local layer will handle the fast, private, cost-free work that makes up the bulk of daily AI-assisted development.
The developers who thrive will be the ones who understand both layers — when to reach for cloud reasoning power and when local inference is the smarter choice. Edge AI isn’t the end of the cloud era. It’s the beginning of a more nuanced one.
References
[1] “Google says new TurboQuant compression can lower AI memory usage without sacrificing quality.” Ars Technica, March 2026. Link
[2] “Caltech Researchers Claim Radical Compression of High Fidelity AI Models.” Wall Street Journal, 2026. Link
[3] “Bonsai 8B: 1-bit models for mobile.” PrismML, 2026. Link
[4] Dave Friedman. “Closed Source vs Open Source AI: A Shrinking Moat.” Substack, 2026. Link
[5] “Gemma 4: Our most capable open models to date.” Google Blog, April 2, 2026. Link
[6] “Nvidia-backed Reflection AI eyes $25 billion valuation.” Reuters, March 2026. Link
[7] “LFM2.5-350M: No Size Left Behind.” Liquid AI Blog, 2026. Link
[8] “Ollama is now powered by MLX on Apple Silicon.” Ollama Blog, March 30, 2026. Link
[9] “2026 AI Index Report.” Stanford HAI, 2026. Link
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.