Meta Harnesses: How Coding Agents Learn to Optimize Their Own Scaffolding
Key Takeaways
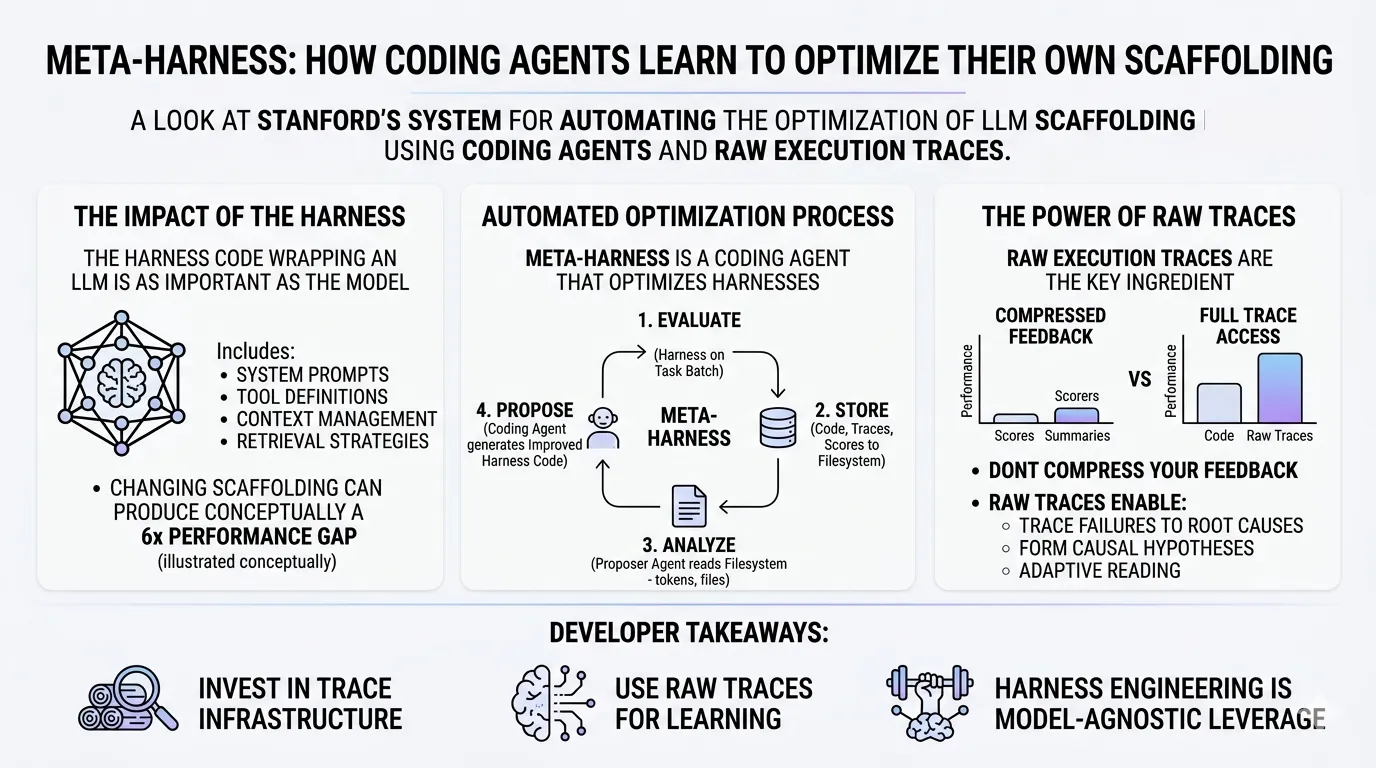
- The harness around an LLM matters as much as the model itself. Changing only the scaffolding code — system prompts, tool definitions, context management, retrieval strategies — can produce a 6x performance gap on the same benchmark with the same model.
- Meta-Harness automates harness optimization using coding agents. A coding agent reads prior candidates’ source code, execution traces, and scores from a filesystem, then proposes improved harness implementations — accessing up to 10 million tokens of diagnostic context per iteration.
- Raw execution traces are the key ingredient. Compressed feedback (scores + LLM summaries) barely improves over scores alone. Full trace access produces a 15-point accuracy jump. The information bottleneck in existing optimization methods is real and significant.
- Discovered harnesses transfer across models and datasets. Harness engineering is a high-leverage, model-agnostic investment — a single optimized harness benefits multiple underlying models.
Everyone talks about model capabilities. Bigger context windows. Better reasoning. Faster inference. There’s another major component of LLM systems that can deliver outsized impact on real-world performance: the harness.
A new paper from Stanford’s IRIS Lab — Meta-Harness: End-to-End Optimization of Model Harnesses [1] — formalizes what many practitioners have discovered through trial and error: the code wrapping the model often matters as much as the model itself. And they’ve built a system that optimizes it automatically.
This post breaks down what meta harnesses are, how they work, and why they represent a meaningful shift in how we think about building coding agents.
What Is a Model Harness?
A model harness is the code that wraps around a frozen language model — everything the model interacts with that isn’t its own weights. System prompts. Tool definitions. Completion-checking logic. Context management strategies. Retrieval pipelines. Memory update procedures.
If you’ve ever iterated on an agent’s system prompt, adjusted how it manages tool calls, or tuned its context window strategy, you’ve been doing harness engineering.
The Meta-Harness paper quantifies something practitioners have long suspected: changing only the harness around the same model can produce a 6x performance gap on the same benchmark. Same model weights. Same task. Wildly different results. The harness is not a thin wrapper — it’s a load-bearing component of agent performance.
How Meta-Harness Works
The core idea is deceptively simple: use a coding agent to optimize the harness of another coding agent. The “meta” in Meta-Harness means it’s a harness that optimizes harnesses — one level of abstraction above the agent scaffolding itself.
The search loop operates as follows:
- Initialize with a baseline harness (e.g., an existing open-source agent scaffold)
- Evaluate the harness on a batch of tasks
- Store everything — source code, execution traces, and scores — to a filesystem
- Propose improvements: a coding agent (Claude Code with Opus 4.6) reads the filesystem, analyzing prior candidates’ code, traces, and scores
- Validate that proposed harnesses meet the interface requirements
- Repeat for ~20 iterations, evaluating ~60 total harness candidates
The proposer reads a median of 82 files per iteration — roughly 41% source code, 40% execution traces, 6% scores, and 13% other files. This gives it up to 10 million tokens of diagnostic context per step, compared to at most 26K tokens for all prior text optimization methods [1].
This isn’t prompt tuning. The proposer modifies actual Python code — rewriting context management strategies, restructuring tool definitions, adding entirely new capabilities like environment bootstrapping or marker-based command polling.
Why Raw Traces Beat Compressed Feedback
The paper’s most compelling finding comes from an ablation study comparing different levels of information access for the proposer:
| Proposer Feedback | Median Accuracy | Best Accuracy |
|---|---|---|
| Scores only | 34.6% | 41.3% |
| Scores + LLM summaries | 34.9% | 38.7% |
| Full trace access | 50.0% | 56.7% |
Adding LLM-generated summaries to scalar scores barely helps — 34.6% to 34.9%. But giving the proposer full access to raw code and execution traces produces a 15.4-point jump in median accuracy.
Compressed summaries destroy the diagnostic signal that matters. When the proposer can read raw execution traces, it can:
- Trace failures to root causes — linking a downstream error to an earlier harness decision
- Form causal hypotheses — after observing six consecutive regressions from prompt modifications, the proposer explicitly hypothesized these were “confounded” interventions and isolated structural fixes from prompt rewrites
- Read adaptively — selectively inspecting only the files relevant to a specific hypothesis, rather than consuming a monolithic summary
This finding has implications beyond Meta-Harness. Any system that optimizes LLM behavior through compressed feedback — scalar rewards, LLM-generated summaries, or short textual critiques — is leaving significant performance on the table.
Results Across Three Domains
Meta-Harness was evaluated across three diverse domains, demonstrating that the approach generalizes beyond a single task type.
Agentic Coding (TerminalBench-2)
On TerminalBench-2 — 89 challenging terminal-based coding tasks — Meta-Harness achieved:
- 76.4% pass rate with Claude Opus 4.6 (ranked #2 on the leaderboard)
- 37.6% pass rate with Claude Haiku 4.5 (ranked #1 among all Haiku agents)
The key innovation discovered by the search: environment bootstrapping — gathering a system snapshot (installed languages, package managers, directory structure, available memory) before the first model call. This eliminates 2–5 exploratory turns the agent would otherwise spend running ls, which python3, etc.
Text Classification
Meta-Harness outperformed the prior state-of-the-art (Agentic Context Engineering) by 7.7 percentage points while using 4x fewer context tokens (11.4K vs 50.8K). The discovered “Label-Primed Query” strategy uses label primers, coverage blocks with representative examples per class, and contrastive pairs highlighting decision boundaries — a strategy no human had previously engineered.
Math Reasoning
A single discovered harness improved accuracy on 200 IMO-level problems by +4.7 points averaged across five held-out models. The proposer discovered a lexical router that categorizes problems by mathematical domain (combinatorics, geometry, number theory, algebra) and applies domain-specific retrieval parameters to each.
Critically, harnesses optimized with one model transferred effectively to models never seen during search. Harness improvements are not model-specific quirks — they encode genuinely better strategies.
The Bigger Picture: Three Layers of Agent Learning
LangChain’s recent analysis of continual learning for AI agents [2] provides useful framing for where meta harnesses fit in the broader landscape. They identify three distinct layers where agent learning can occur:
| Layer | What Changes | Example |
|---|---|---|
| Model | Weights (fine-tuning, RL) | Training Codex models specifically for coding tasks |
| Harness | Permanent scaffolding code | System prompts, tool definitions, context management |
| Context | Configurable external information | CLAUDE.md files, skill directories, MCP configs |
Meta-Harness operates at the harness layer — optimizing the permanent infrastructure that drives the agent. Context-level learning (updating memory, skills, and configuration files) is the fastest path to production improvements, but harness-level optimization offers higher ceiling gains.
The three layers aren’t independent. Traces — the full execution path of what an agent did — are the foundational infrastructure enabling learning at all three layers. Traces become training data for model fine-tuning, diagnostic input for harness optimization, and patterns for context updates. Without comprehensive trace collection, none of these learning mechanisms function effectively.
What This Means for Developers
Meta-Harness formalizes something the coding agent community has been doing informally: iterating on the scaffolding around LLMs until it works. But it also reveals that human intuition about what makes a good harness is limited. The Label-Primed Query strategy, the lexical math router, the environment bootstrapping technique — none of these were obvious prior to automated search.
Three practical implications:
-
Invest in trace infrastructure. Comprehensive execution traces are the universal currency of agent improvement. Whether you’re optimizing harnesses, fine-tuning models, or updating agent memory, traces are the input.
-
Don’t compress your feedback. If you’re building systems that learn from agent performance, give the optimizer access to raw data — not just scores or summaries. The 15-point accuracy gap from the ablation study is not subtle.
-
Harness engineering is model-agnostic leverage. A well-engineered harness improves every model you run through it. As models become increasingly commoditized, the harness becomes the differentiator.
The Meta-Harness search loop itself is not open-sourced (only the discovered artifacts are available), but the principles — rich trace access, code-level optimization, iterative evaluation — are implementable with existing tools. The paper demonstrates that coding agents are capable of meaningfully improving their own scaffolding when given the right information.
We’re entering an era where the most impactful engineering work on coding agents isn’t about making models smarter. It’s about making the code around them better — and letting agents do that work themselves.
References
[1] Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, Chelsea Finn. “Meta-Harness: End-to-End Optimization of Model Harnesses.” arXiv:2603.28052, March 2026. Paper | Code | Project Page
[2] Harrison Chase. “Continual Learning for AI Agents.” LangChain Blog, March 2026. Blog Post
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.