GPT-5.5: The Honest Take on OpenAI's Response to Opus 4.7
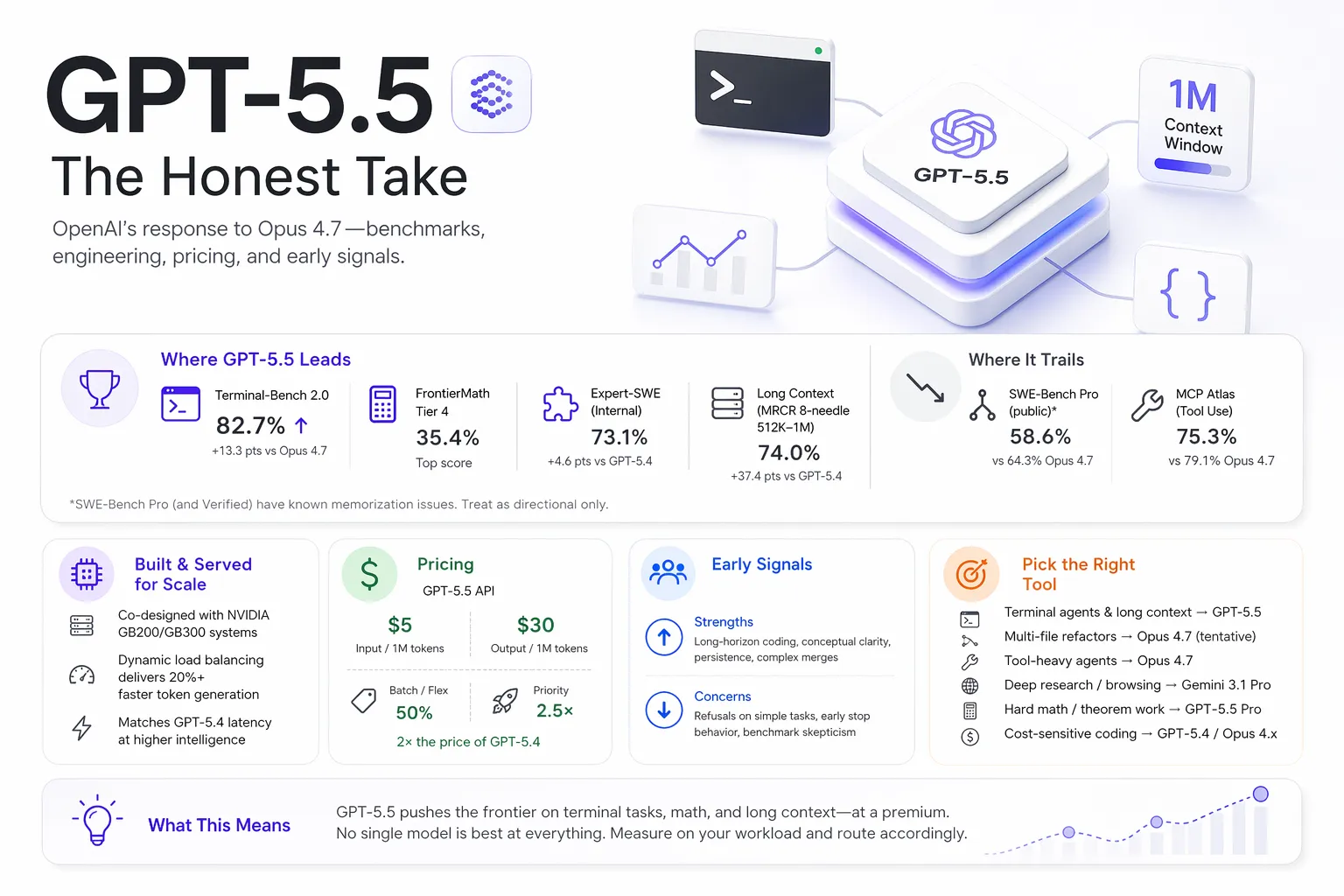
OpenAI released GPT-5.5 today, exactly one week after Anthropic shipped Claude Opus 4.7[5]. The timing is not subtle. Opus 4.7 took the SWE-Bench Verified crown at 87.6% and put Anthropic at the top of most third-party coding leaderboards; GPT-5.5 is the direct response[5]. Worth flagging upfront: SWE-Bench Verified scores at this tier should be read with heavy skepticism. Every frontier lab has plausibly trained on or adjacent to this data, and Anthropic itself has acknowledged memorization signals on related SWE-Bench splits. Treat any Verified or Pro number in this post as a directional signal, not a trustworthy measurement — we include them because they are what the labs report, not because we think they carry much weight.
The release is interesting for software engineers not because it “wins” — the verdict is more mixed than OpenAI’s launch post suggests — but because of the specific benchmarks it wins on, the specific ones it doesn’t, and the pricing decision that frames everything else. This post walks through what changed, how OpenAI built and served it, what the numbers actually say relative to Opus 4.7 and Gemini 3.1 Pro, and what the first day of real usage is surfacing.
The benchmark picture
The cleanest summary: GPT-5.5 is state-of-the-art on a subset of coding and math benchmarks, nominally behind Opus 4.7 on SWE-Bench Pro (a benchmark we’d largely discount given widespread memorization evidence), and behind both Opus 4.7 and Gemini 3.1 Pro on several agent/tool-use workloads[1][2].
| Benchmark | GPT-5.5 | GPT-5.4 | Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| SWE-Bench Pro (public)* | 58.6% | 57.7% | 64.3% | 54.2% |
| Expert-SWE (OpenAI internal) | 73.1% | 68.5% | — | — |
| OSWorld-Verified | 78.7% | 75.0% | 78.0% | — |
| MCP Atlas (tool use) | 75.3% | 70.6% | 79.1% | 78.2% |
| BrowseComp | 84.4% | 82.7% | 79.3% | 85.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 22.9% | 16.7% |
| Humanity’s Last Exam (no tools) | 41.4% | 39.8% | 46.9% | 44.4% |
| GDPval (wins or ties) | 84.9% | 83.0% | 80.3% | 67.3% |
All figures from OpenAI’s release[1]; asterisks and memorization caveats discussed below.
*We’d argue SWE-Bench Pro (and SWE-Bench Verified) should be heavily discounted at this point. Both benchmarks have known memorization issues: Anthropic’s own Opus 4.7 notes flag “evidence of memorization” on the benchmark[1][3], and Scale’s public leaderboard methodology documents this as a known failure mode[6]. When every frontier lab has plausibly seen the data, the scores tell you more about training set overlap than model capability. Use them as a floor, not a ranking — and weight Terminal-Bench 2.0, OSWorld-Verified, Expert-SWE, and your own task-specific evals far more heavily.
One real gap deserves attention: Terminal-Bench 2.0. A 13-point lead over Opus 4.7 is the largest single-benchmark gap between today’s frontier coding models, and this benchmark is newer and harder to pre-train against than the SWE-Bench family. If your agent workload is long-running terminal sessions — sandboxed CI jobs, reproduction scripts, multi-step shell workflows — GPT-5.5 leads it clearly. On MCP Atlas, Opus 4.7 still edges ahead, which matters more for tool-heavy agent workloads than the SWE-Bench Pro delta does.
As with the last several releases, the honest framing is that no single model is best at everything. Which model wins depends on which benchmark you pick, which scaffold runs the evaluation, and what your actual workload looks like.
How the model was built and served
OpenAI’s most concrete technical claim in the release is about serving, not training: GPT-5.5 matches GPT-5.4 per-token latency in production while performing at a higher level of intelligence[1]. For a larger, more capable model, holding latency flat is a non-trivial infrastructure result.
The stated method has two parts.
Co-designed with NVIDIA GB200 and GB300 NVL72 systems. OpenAI says GPT-5.5 was trained on and served from Blackwell-class hardware, and that the serving stack was optimized in lockstep with the model[1]. The release post specifically credits Codex and GPT-5.5 itself for helping identify infrastructure optimizations — model-assisted systems work, which is increasingly how frontier labs describe their inference stacks.
Dynamic load balancing replaced static chunking. Before GPT-5.5, OpenAI split requests on each accelerator into a fixed number of chunks. Codex analyzed weeks of production traffic and wrote custom heuristic algorithms to partition work dynamically based on request shape, reportedly increasing token generation speed by over 20%[1].
This doesn’t change anything about how you build with the model, but it’s worth internalizing: much of the per-token efficiency story is about the serving system, not the weights. It also explains the pricing: GPT-5.5 is a larger, more expensive model to serve than GPT-5.4, and the 2× API rate hike partially reflects that cost even after the dynamic batching wins.
One other architectural note worth flagging for engineers planning migrations: the 1M context window is now supported both in Codex (standard) and in the forthcoming API endpoint[1]. Long-context performance looks materially better than GPT-5.4. On OpenAI MRCR v2 8-needle from 512K–1M, GPT-5.5 scores 74.0% vs GPT-5.4’s 36.6%[1]. On Graphwalks BFS at 1M tokens, F1 goes from 9.4% (GPT-5.4) to 45.4%[1]. This is probably the largest generational jump in GPT-5.5 and gets less attention than the coding numbers.
That said: Opus 4.7 still beats GPT-5.5 on several mid-range long-context evaluations. And the honest caveat from prior GPT-5 releases still applies — a 1M window where the last 400K tokens are unreliable is functionally smaller than the marketing suggests. Treat the 1M number as a real improvement over GPT-5.4, not as a license to stop managing context.
Pricing, and why it’s the most-discussed part of the release
The pricing on gpt-5.5 is $5 per 1M input tokens and $30 per 1M output tokens, with batch and flex at half that rate and priority at 2.5×[1]. gpt-5.5-pro is $30 / $180. Compared to GPT-5.4 ($2.50 / $15), the base model is a flat 2× price increase[3].
This dominated the first day’s discussion. One Hacker News commenter summarized it bluntly: this is roughly 3× the price of GPT-5.1 released six months earlier[4]. OpenAI’s counter-argument, repeated several times in the release and by employees in community threads, is that GPT-5.5 uses meaningfully fewer tokens for the same task — so price per completed unit of work can be lower even when price per million tokens is higher[1][4].
Both things are true. The practical implication depends on where you’re running it:
- In Codex and ChatGPT subscriptions, OpenAI says the per-task token reduction is enough that most users get better results with fewer tokens at their existing tier[1]. This matches early reports from subscribers on the HN thread.
- In the API, the math is workload-dependent. If your app sends short prompts and GPT-5.5 produces 30% fewer output tokens than GPT-5.4, you’re still paying ~40% more per call. If you’re running long-horizon agent loops where GPT-5.5 cuts tokens by half, the net cost can drop.
The cleanest read is: assume API costs go up unless you measure otherwise. The Decoder’s coverage put it plainly — “despite the higher price tag, GPT-5.5 is more efficient and needs fewer tokens for comparable tasks” is marketing language for “you’ll pay more per token but possibly less per outcome”[3].
What early users are actually reporting
Day-one impressions are a mix of genuine enthusiasm from early-access partners and skepticism from the broader community.
Positive reports. Several early-access partners highlighted strong long-horizon coding results. Dan Shipper (CEO of Every) credited GPT-5.5 with unusual conceptual clarity, pointing to a refactor it produced that matched the solution one of his senior engineers eventually landed on — and that GPT-5.4 had not been able to find[1]. Pietro Schirano (MagicPath) reported GPT-5.5 merging hundreds of changes from a refactor branch into a main branch that had also moved significantly, in a single ~20-minute pass[1]. Michael Truell at Cursor emphasized persistence, noting the model stays on task materially longer before stopping early[1].
These are real signals — long-horizon coding and cross-branch reasoning are exactly where Expert-SWE (OpenAI’s internal benchmark) shows a 5-point lift over GPT-5.4.
Skeptical reports. The top Hacker News thread as of this writing flags the opposite failure mode: one developer reported GPT-5.5 refusing to perform a quick, benign subtask that GLM, Kimi, and MiniMax all completed — and dropping OpenAI as a result[4]. Another recurring complaint in the thread is around model “motivation” — GPT-5.5 and GPT-5.4 both yielding control mid-task or declining work that was explicitly requested. Benchmark fatigue was also visible: commenters pushed back on OpenAI’s “strongest and fastest model yet” framing as boilerplate launch language[4].
Coding verdict emerging. The pragmatic consensus in the HN thread is to hold off on swapping Claude out for coding work until independent SWE-Bench numbers are published and verified, with several commenters calling out Opus 4.7 as still the strongest option for long-horizon refactors[2]. That’s an overstatement given GPT-5.5’s Expert-SWE lead, but the underlying point — wait for independent evaluations — is correct. Vals.ai and Scale typically publish third-party numbers within a few weeks of release, and those numbers are what to watch for.
How it compares to the alternatives, task by task
Given the mixed benchmark picture, a single “which model is best” answer doesn’t exist. Based on first-day evidence, here’s a reasonable task-routing view.
| Workload | Best choice today | Why |
|---|---|---|
| Long-running terminal agents | GPT-5.5 | +13pt lead over Opus 4.7 on Terminal-Bench 2.0 |
| Real GitHub issue resolution (multi-file patches) | Opus 4.7 (tentative) | Nominally 64.3% vs 58.6% on SWE-Bench Pro, but memorization caveats mean this ordering is weak — run your own eval before committing |
| MCP tool-heavy agents | Opus 4.7 | 79.1% vs 75.3% on MCP Atlas |
| Deep research / web-browsing agents | Gemini 3.1 Pro or GPT-5.4 Pro | Both lead BrowseComp; GPT-5.5 Pro closes the gap to 90.1% but the Pro pricing is steep |
| Hard math / theorem work | GPT-5.5 Pro | 39.6% on FrontierMath Tier 4 — no close peer |
| Long-context (512K–1M tokens) | GPT-5.5 | MRCR 8-needle 512K–1M at 74.0% vs GPT-5.4’s 36.6% and Opus 4.7’s 32.2% |
| Cost-sensitive coding | GPT-5.4 or Opus 4.6/4.7 | GPT-5.5 is 2× GPT-5.4’s API price |
For teams running coding agents in production, the least controversial take is: Opus 4.7 is still the safer default for multi-file refactor work — though we’d emphasize that the SWE-Bench Pro lead driving that conclusion is the weakest part of the evidence, given the benchmark’s memorization problems. GPT-5.5 is the new default for terminal-heavy agent loops and for the long-context workloads where GPT-5.4 was unreliable. If you’re already routing between models, GPT-5.5 slots in without changing the overall shape of your stack — and if you care about multi-file coding specifically, the honest advice is to run a real eval on your own codebase rather than trusting the leaderboard.
What this release actually signals
Two things stand out beyond the benchmarks.
The pace has not slowed. Opus 4.7 shipped April 16. GPT-5.5 shipped April 23. Anthropic’s restricted Claude Mythos Preview is already being referenced in OpenAI’s comparison tables[5]. If you’re planning infrastructure, assume another frontier model drop within 4–8 weeks, and design so that swapping the model behind your scaffold is cheap.
Pricing is now a product decision, not just a cost. OpenAI doubling the API rate of its flagship while routing cheaper alternatives (GPT-5.4, GPT-4.1) through the same interface is a conscious segmentation. It matches Anthropic’s Opus/Sonnet split and Google’s Pro/Ultra split. For most engineering workloads, the right question is no longer “what’s the best model?” but “what’s the cheapest model that clears my quality bar for this specific task?”
GPT-5.5 doesn’t answer that question for you. But it changes the shape of the answer: on terminal agents and long-context work, it’s probably worth the premium. On most other shapes of coding work, Opus 4.7 or GPT-5.4 still wins on price-per-quality. As always, measure before migrating.
References
[1] OpenAI, “Introducing GPT-5.5.” April 23, 2026. Link
[2] Hacker News, “GPT 5.5 Released in Codex” discussion thread. April 21–23, 2026. Link
[3] The Decoder, “OpenAI unveils GPT-5.5, claims a ‘new class of intelligence’ at double the API price.” April 23, 2026. Link
[4] Hacker News, “GPT-5.5” discussion thread. April 23, 2026. Link
[5] VentureBeat, “OpenAI’s GPT-5.5 is here, and it’s no potato: narrowly beats Anthropic’s Claude Mythos Preview on Terminal-Bench 2.0.” April 23, 2026. Link
[6] Scale Labs, “SWE-Bench Pro Leaderboard.” Retrieved April 23, 2026. Link
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.