The Memory Wall Is Coming Down — What It Means for Coding Agents
Key Takeaways
- The memory wall is a primary constraint on coding agents, not model intelligence. Quadratic attention costs, KV cache growth, and “lost in the middle” degradation create a hard ceiling on how long agents can maintain coherent reasoning.
- Research breakthroughs compose: 30x+ KV memory reduction is within reach. TriAttention’s intelligent pruning and TurboQuant’s 3-bit quantization are complementary techniques that stack naturally, while Latent Briefing cuts multi-agent context sharing costs by 49%.
- Fundamentally different theories of agent memory are emerging. For example, MemPalace bets on structured archival with spatial retrieval; Hippo Memory bets on intelligent forgetting with decay-based consolidation. The field hasn’t converged on what wins or perhaps it changes depending on the use case.
- The harness is becoming an operating system for agent memory. Claude Code’s three-layer compaction, four-tier persistence hierarchy, and self-healing query loop reveal that production coding agents are already memory management systems — and this pattern will only deepen.
One of the biggest constraints on coding agents is memory.
Specifically, it’s the quadratic cost of attention — the mechanism that lets models weigh the relevance of every token against every other token. This single architectural bottleneck determines how long an agent can think, how much context it can hold, and how complex the tasks it can tackle before it starts forgetting what it was doing.
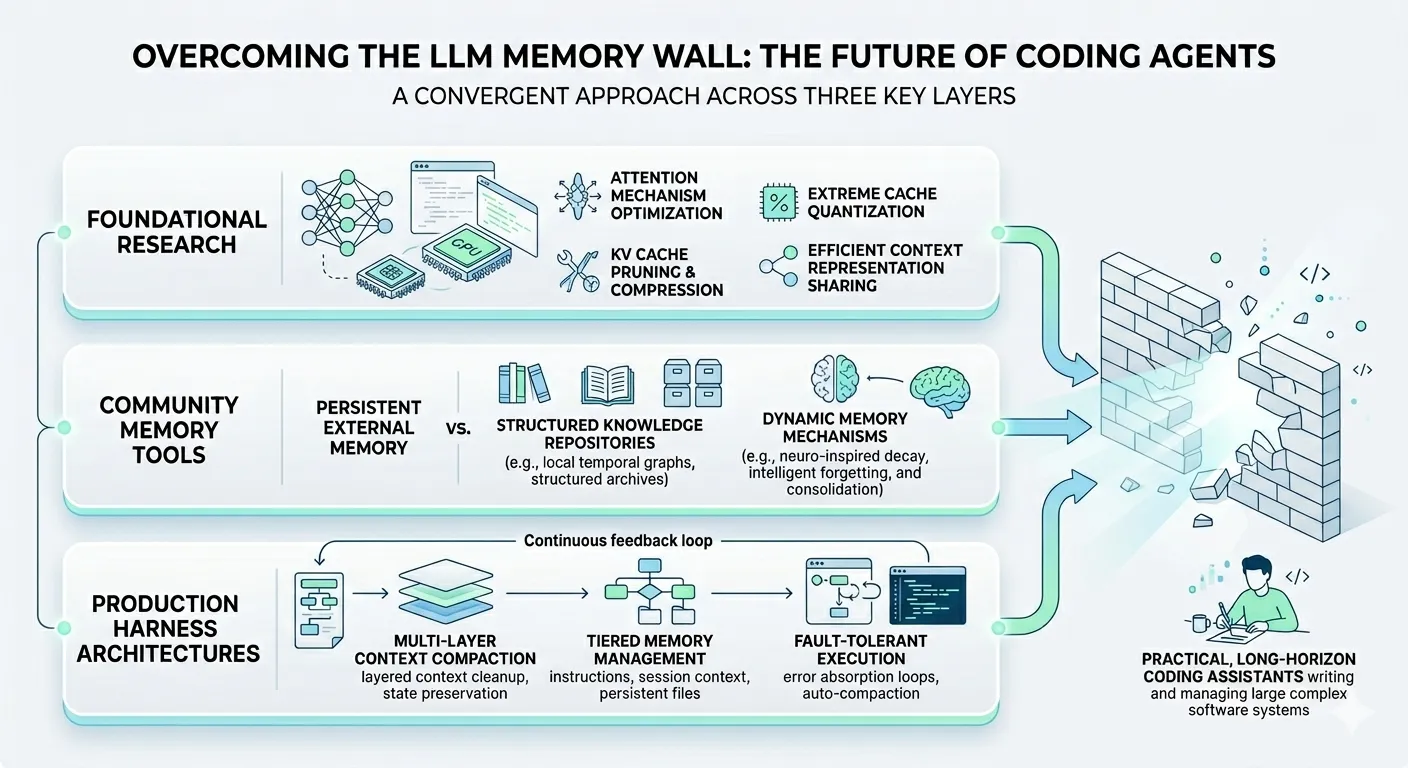
Three layers of innovation are converging on this problem simultaneously: foundational research that slashes the memory cost of attention itself, community-built tools that give agents persistent memory across sessions, and production harness architectures that manage context as a first-class engineering concern. These aren’t isolated efforts. They’re solving the same problem at different altitudes. Understanding how they connect — and where they’re heading — is essential for anyone building with or for coding agents today.
The attention tax every coding agent pays
Before getting into solutions, it’s worth understanding the constraint clearly. If you’ve worked with coding agents, you’ve felt this — even if you didn’t have a name for it.
Transformers process input through an attention mechanism. For every new token the model generates, it computes a relevance score against every previous token in the context window. This is what makes language models powerful: they can relate distant pieces of information. It’s also what makes them expensive: the computation scales quadratically with sequence length. Double the context, quadruple the cost.
In practice, this means a 200K token context window is not 200K tokens of useful capacity. Claude Code’s 200K window shows measurable degradation around 147K–152K tokens. System prompts alone can consume 30K–40K tokens before the user types anything. The “lost in the middle” phenomenon — where models deprioritize information in the middle of long contexts — compounds the problem. More context doesn’t mean better understanding. Past a threshold, it means worse understanding.
For coding agents, this creates a hard ceiling. A long refactoring session accumulates tool results, file reads, error traces, and intermediate reasoning. Each step adds to the context. Eventually, the agent is spending more compute re-attending to stale history than reasoning about the current problem. This is the memory wall, and it’s the primary reason coding agents degrade on long tasks.
Research is breaking the wall
This isn’t one paper. It’s a wave. Multiple research teams are attacking the memory wall from different angles simultaneously: compressing the KV cache through structural insights, quantizing it to extreme bit-widths, and making multi-agent context sharing efficient at the representation level.
TriAttention: compressing the KV cache without losing quality
The KV (key-value) cache stores the attention state for every token the model has processed. As context grows, this cache becomes the dominant memory consumer. Existing compression methods like SnapKV try to prune unimportant keys, but they estimate importance using attention scores from recent queries — and those scores are distorted by a positional encoding called RoPE (Rotary Position Embedding), making them unreliable.
TriAttention[1], from researchers at MIT, NVIDIA, and Zhejiang University, takes a different approach. It exploits a structural property the authors call Q/K concentration: in the pre-RoPE representation space, query and key vectors cluster tightly around fixed centers regardless of input or position. Approximately 90% of attention heads in tested models show this property. These stable centers determine which token distances each head preferentially attends to via a trigonometric distance-preference function.
Instead of dynamically guessing which keys matter, TriAttention scores each key against these fixed centers using the trigonometric function, then keeps only the top-scoring keys. The scoring runs as a fused Triton kernel with a protected window of recent tokens that are never evicted.
The results are striking:
- 10.7x KV memory reduction
- 2.5x throughput on long reasoning tasks (32K token generation), with accuracy matching full attention (40.8 on AIME25 for both)
- 6.3x throughput on MATH-500 with only 1.2 percentage points of accuracy loss
- Existing baselines (SnapKV, R-KV) collapse to roughly half the accuracy at the same memory budget
The practical implication: reasoning models that previously required multi-GPU setups can run on a single consumer GPU. For coding agents, this means longer reasoning chains within the same hardware constraints — more time thinking about your refactoring task before the memory wall hits.
TurboQuant: extreme compression, zero accuracy loss
While TriAttention prunes which keys to keep, Google’s TurboQuant[2] (ICLR 2026) attacks the same problem from a complementary angle: making each key smaller. It quantizes the KV cache down to 3 bits per parameter — training-free — using two techniques: PolarQuant, which rotates key/value vectors into a representation that quantizes more uniformly, and Quantized Johnson-Lindenstrauss compression, which reduces dimensionality while preserving distance relationships.
The result: no measurable accuracy loss across LongBench, RULER, and Needle-in-a-Haystack benchmarks. In practice, this means ~3x longer effective context on the same GPU memory. Stack TurboQuant with TriAttention’s pruning and you’re looking at 30x+ memory reduction — enough to hold a substantial codebase’s worth of context on hardware that currently struggles with a single long conversation.
These aren’t competing approaches. Pruning (which keys to keep) and quantization (how much space each key needs) compose naturally. The research community is converging on a layered compression stack for attention, much like how image codecs layer spatial compression, quantization, and entropy coding.
Latent Briefing: efficient memory sharing between agents
Multi-agent systems have a compounding token problem. When an orchestrator delegates tasks to worker agents, each worker needs context about what the orchestrator has already figured out. The naive approach — passing the full reasoning trajectory as text — causes token usage to explode with each successive call. Summarization is slow and lossy. RAG retrieval is brittle.
Latent Briefing[3], from Ramp Labs, operates at a different level entirely. Instead of compressing text, it compresses the model’s internal representations.
The mechanism: the orchestrator’s accumulated reasoning is forward-passed through the worker model. The attention scores between the task prompt’s query vectors and the trajectory’s KV cache keys reveal which parts of the context the worker considers relevant — and crucially, this relevance is task-adaptive. Different queries compress the same context differently. The method then constructs a compact KV cache using the important keys, bias corrections for missing keys, and reconstructed values via ridge regression.
Tested with Claude Sonnet 4 (orchestrator) and Qwen-14B (worker) on 126 LongBench v2 questions:
- 49% median token savings on medium-length documents (32K–100K tokens)
- +3 percentage point accuracy gain at the right compaction threshold — it actually performs better with less context
- Compaction takes ~1.7 seconds, roughly 20x faster than sequential attention merging and 10–30x faster than LLM summarization
That accuracy gain is the telling result. Removing irrelevant context doesn’t just save tokens — it helps the model focus.
A practically important finding from the paper: different compaction thresholds win in different regimes. Longer documents (32K–100K tokens) benefit from lighter compaction — the information is dispersed and broad coverage matters, but even light pruning still saves 57% of worker tokens. Harder questions benefit from aggressive compaction (79% of context removed) because the orchestrator’s speculative reasoning generates noise that dilutes the worker’s signal. Moderate compaction works best for short, focused documents.
This isn’t just a tuning knob. It’s a design principle: the right amount of context depends on the task, not just the budget. Compaction should be task-aware, not one-size-fits-all. This validates a principle that experienced harness engineers already know intuitively: less context, better directed, beats more context.
Products are building on top
While researchers optimize what happens inside the model’s context window, community builders are attacking the problem from the other direction: giving agents external memory that persists beyond any single session.
MemPalace: structured recall through spatial organization
MemPalace[4] maps the ancient Method of Loci to a data architecture for AI agents. Wings are top-level categories (a person, a project). Rooms are specific topics within a wing. Halls connect rooms by type. Tunnels automatically link the same room across different wings. Drawers are the atomic unit: verbatim text chunks that are never summarized.
The technical backbone is dual storage: ChromaDB for semantic vector search and SQLite for a temporal knowledge graph that tracks facts over time. A four-layer memory stack minimizes token cost:
- L0 (identity, ~50 tokens) and L1 (critical facts, ~120 tokens) load on every startup
- L2 (room recall) and L3 (deep search) fire only on demand
In benchmarks, wing+room metadata filtering improves retrieval from 60.9% to 94.8% R@10 — though this leverages standard ChromaDB metadata filtering rather than a novel retrieval mechanism. The real value is the spatial organization model itself, which gives agents a structured way to scope queries. Everything runs locally with no cloud dependency.
Hippo Memory: forgetting as a feature
Hippo Memory[5] takes a neuroscience-inspired approach with a three-tier hierarchy mimicking human memory: a buffer (working memory, current session only), an episodic store (timestamped memories with a 7-day half-life that strengthens through retrieval), and a semantic store (stable patterns extracted during consolidation).
The key innovation is the sleep command — a consolidation pipeline that runs a decay pass to remove weak memories, a replay pass that finds three or more related episodes via embedding similarity and extracts common patterns into semantic memory, conflict detection for contradictions, and schema indexing to update topic clusters.
Memories decay by default. Persistence is earned through use. Errors get 2x the half-life. Breakthroughs get priority. This is the opposite of “store everything and search later.” It’s a bet that intelligent forgetting is as important as precise recall.
The key distinction
MemPalace and Hippo Memory represent two fundamentally different theories of agent memory. MemPalace is a structured archive — store everything verbatim, make it findable through spatial organization. Hippo is a dynamic brain — memories compete for survival through use, decay, and consolidation. MemPalace bets on retrieval precision. Hippo bets on forgetting as a feature. Both are valid. The field hasn’t converged on which approach wins yet — and the answer may be that different tasks demand different memory architectures.
Claude Code’s architecture: the harness layer
Claude Code reveals what a production coding agent does when it can’t wait for research to ship. Its architecture is a pragmatic, multi-layered response to the memory wall — and it’s instructive because it shows what works today.
The self-healing query loop
Claude Code doesn’t use standard request-response. It runs a continuous state machine designed to absorb failures. When the model exhausts its output budget mid-task, the loop doesn’t crash. It triggers compression automatically, carving out a buffer before the token ceiling and generating a structured summary. If the API returns a prompt_too_long error, reactive compression fires and retries. To prevent infinite loops, auto-compaction pauses after three consecutive failures.
Three-layer compaction
The compaction system uses progressively stronger cleanup:
- Rules engine cleanup — lightweight, no LLM call. Strips known low-value patterns: stale tool results, redundant messages.
- Session memory extraction — writes extracted facts to disk, removes them from context. Still avoids an LLM call.
- Full summary — when layers 1 and 2 are insufficient, an LLM-generated summary replaces older messages.
A critical design choice: Claude Code preserves the message prefix so Anthropic’s prompt cache remains valid. Naive oldest-first deletion would invalidate the entire cache on every compaction — a costly mistake that would negate the efficiency gains.
Four-tier memory hierarchy
Persistence across sessions uses four tiers:
- CLAUDE.md — project-level instructions, read on every session start, survives compaction by being re-read from disk
- Auto Memory — topic files in
.claude/that evolve with project knowledge - Session Memory — cross-session context extracted every ~5,000 tokens
/remember— promotes recurring patterns into permanent configuration
This architecture is fundamentally a memory management system that bridges finite context windows and unbounded tasks. The model handles what fits in attention. The harness handles everything else.
How the pieces map together
These three layers — research, product, harness — aren’t competing. They’re solving the same problem at different altitudes, and their relationship is structural.
The research layer makes the foundation wider. TriAttention and TurboQuant compose to achieve 30x+ memory reduction for the KV cache. Latent Briefing lets multiple agents share context at 50% of the token cost with better accuracy. These don’t change what models can do conceptually — they change the economics of how much they can hold while doing it.
The product layer extends reach beyond any single context window. MemPalace and Hippo Memory give agents access to knowledge that no context window, however large, could contain: months of project history, cross-session decisions, accumulated preferences. They’re building external memory systems because even with perfect attention, a context window is still a window.
The harness layer manages the interface between finite capacity and infinite demand. Claude Code’s compaction, memory hierarchy, and self-healing loop exist because even with better attention and external memory, someone still needs to decide what goes in the context window right now. The harness is the memory manager — it routes information between tiers, decides what to compress, and recovers when capacity runs out.
The layers are complementary because each one makes the others more effective:
- Better KV compression (research) means harness compaction can be less aggressive, preserving more context quality
- Richer external memory (product) means the harness can offload more confidently, knowing it can retrieve when needed
- Smarter harness routing means research-level efficiency gains translate into user-visible capability, not just lower API bills
Predictions: where this convergence leads
Near-term
The next wave of KV cache compression hits production. The first wave is already standard: Grouped Query Attention is baked into every major open-weight model, PagedAttention is the default memory manager in vLLM, FP8 KV quantization ships in both vLLM and TensorRT-LLM, and prefix caching is default-on at every major provider. What’s coming is more aggressive. TriAttention already ships as a vLLM plugin with community ports for llama.cpp and MLX. TurboQuant emerged from Google Research with community MLX implementations appearing within weeks. Within a year, sub-4-bit KV quantization and intelligent pruning will be default options in inference frameworks — not research experiments. This next wave directly extends how long coding agents can maintain coherent reasoning on a single task.
Multi-agent memory sharing moves from research to production. Latent Briefing’s representation-level compaction is one compelling approach, but it’s part of a broader wave. Teams are exploring shared KV cache pools across co-located agents, lightweight context distillation protocols, and hierarchical memory architectures where agents at different levels of an orchestration tree maintain context at different granularities. The common thread: making delegation cheap by solving context transfer at the systems level rather than through brute-force token passing. Expect multi-agent coding workflows to adopt one or more of these techniques, dramatically cutting the cost of orchestrator-to-worker handoffs.
External memory becomes expected, not optional. MemPalace and Hippo Memory are early but the pattern is clear: coding agents that remember project context across sessions will outperform those that don’t, and developers will demand this capability. Claude Code’s CLAUDE.md and Auto Memory are the first-party version of this trend.
Medium-term
Always-on agents become practical. The combination of compressed attention, efficient multi-agent sharing, and tiered external memory unlocks a new class of applications: coding agents that maintain continuous context over days or weeks. Not because the context window grows to millions of tokens, but because the system around it manages memory intelligently at every layer.
Memory consolidation becomes the norm. Hippo Memory’s bet — that forgetting is as important as remembering — is likely directionally right, even if the specific mechanisms evolve. As agents accumulate months of project history, storing everything becomes as costly as forgetting everything. The winning systems will almost certainly need some form of consolidation: compressing episodes into patterns, decaying noise, strengthening what’s used. Human memory works this way for a reason.
Models develop distinct memory tiers internally. Current models treat all tokens in the context window equally. Future architectures will likely differentiate between working memory (high-attention, recent, expensive) and reference memory (lower-attention, compressed, cheap) — mirroring what harnesses already do externally. When this happens, the external product layer and the internal model layer will start to merge.
What this means for harness engineering
This is where it gets concrete for builders.
Harnesses will manage multiple memory tiers, not just context windows. Today, a harness manages one thing: what’s in the context. Tomorrow, it manages in-context tokens, compressed KV cache segments, external vector stores, persistent project files, and cross-session summaries. The harness becomes a memory routing system.
Memory routing becomes a first-class discipline. For every piece of information an agent encounters, the harness will need to make a routing decision: does this go in active context? Compressed cache? External store? Disk? Nowhere? Getting this routing right — fast, at scale, without human intervention — is the defining challenge of next-generation harness engineering.
Compaction strategies become differentiating. Claude Code’s three-layer compaction is state-of-the-art for a single-agent coding tool today. But as tasks get longer and multi-agent workflows become standard, compaction will need to become task-aware (like Latent Briefing), importance-weighted (like Hippo’s decay model), and cache-preserving (like Claude Code’s prefix protection). The teams that ship the most capable agents won’t be the ones with the most sophisticated compaction pipeline in isolation — they’ll be the ones who understand what’s in development at each layer of the research stack, recognize where models are and aren’t capable of managing memory on their own, and synthesize all of that into a coherent strategy for how memory should work across long-horizon tasks.
The harness is becoming an operating system for agent memory. This isn’t hyperbole. An OS manages memory tiers (registers, L1/L2 cache, RAM, disk), makes routing decisions transparently, and provides a clean abstraction to the application layer. Harnesses are converging on the same architecture for agent memory.
Independent research is arriving at the same conclusion. A recent paper from Yu, Zhang, Ni et al. [6] explicitly frames multi-agent memory as a computer architecture problem — proposing a three-layer hierarchy (I/O, cache, memory) with shared vs. distributed paradigms and formal consistency protocols. Their central argument: multi-agent memory consistency is the most pressing unsolved problem in agent systems, just as cache coherence was for multiprocessor systems decades ago.
The parallel is exact. And it means the teams building harnesses today are, whether they realize it or not, building the memory management layer of a new computing paradigm.
The memory wall for coding agents isn’t permanent. It’s an engineering problem being solved at every layer simultaneously — in attention research, in community-built memory products, and in production harness architectures. The builders who understand where these layers connect will build the most capable agents. And the ones who realize that the harness isn’t just an execution wrapper but a memory management system — those are the ones building the infrastructure that everything else will run on.
References
[1] Weian Mao et al. “TriAttention: Efficient Tri-State KV Cache Compression for Long-Context Transformers.” MIT, NVIDIA, Zhejiang University, 2026. Code
[2] Google Research. “TurboQuant: Redefining AI Efficiency with Extreme Compression.” ICLR 2026. Blog Post
[3] Ramp Labs. “Latent Briefing: Efficient Multi-Agent Context Sharing via Representation-Level Compaction.” 2026. Announcement
[4] MemPalace. “MemPalace: Structured Spatial Memory Architecture for AI Agents.” Code
[5] Hippo Memory. “Hippo Memory: Neuroscience-Inspired Memory with Forgetting and Consolidation.” Code
[6] Yu, Zhang, Ni et al. “Multi-Agent Memory as a Computer Architecture Problem.” arXiv:2603.10062, 2026. Paper
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.