We're Burning Tokens and Calling It Progress
Jensen Huang says more tokens equals more money. The supply-side math checks out. But supply without measurement is just spending.
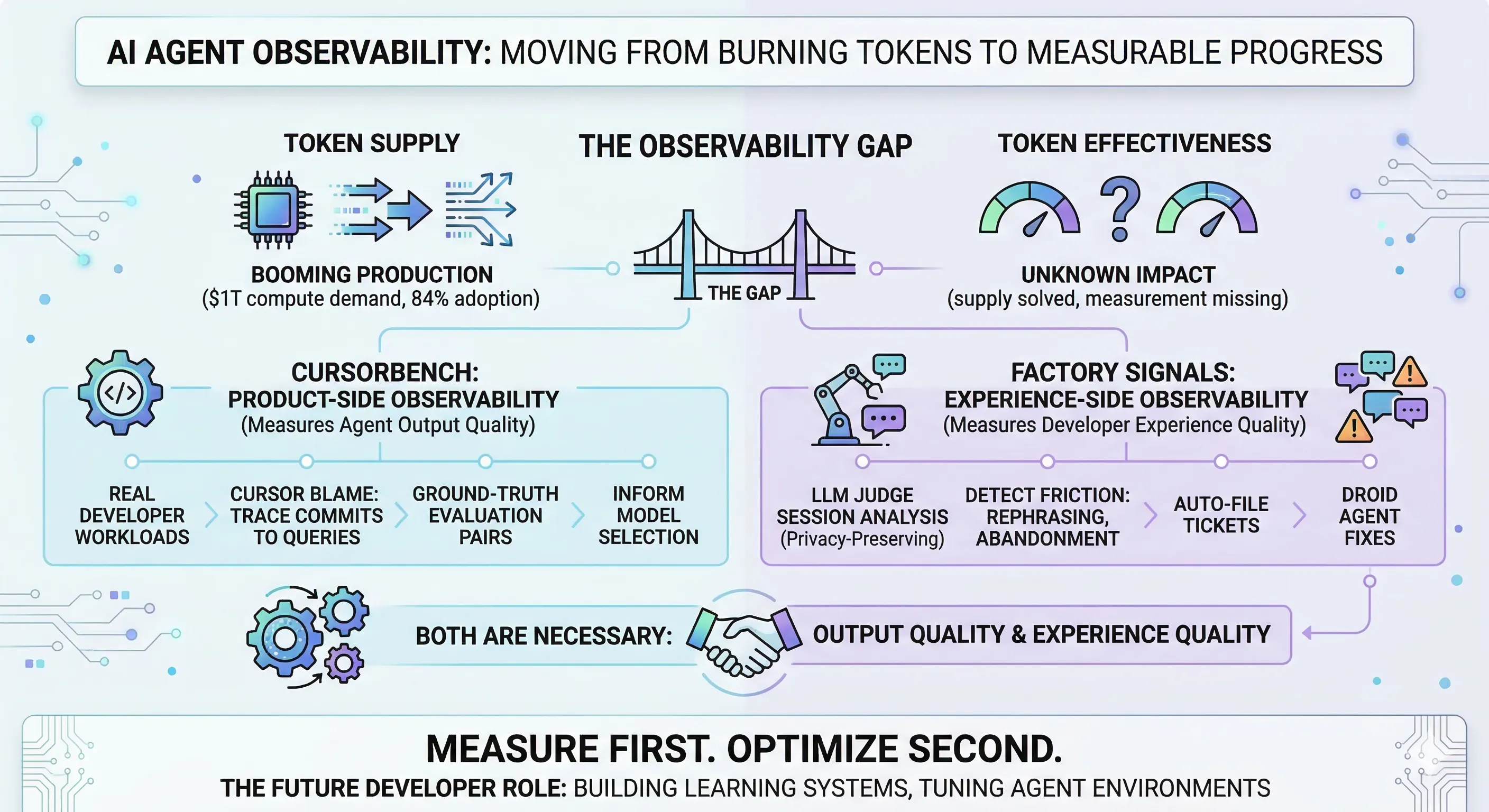
At GTC 2026, Huang framed data centers as “token factories” and projected $1 trillion in compute demand through 2027. Meanwhile, 84% of developers now use AI coding tools. The infrastructure to generate tokens is scaling on schedule.
The infrastructure to measure what those tokens produce doesn’t exist yet. That’s the gap that actually matters.
Key Takeaways
- Token supply is scaling, but measurement infrastructure is not. 84% of developers use AI coding tools and almost nobody is measuring whether they work — the METR study’s control group couldn’t even stop using AI long enough to measure its impact.
- Product-side observability is now possible. CursorBench traces committed code back to agent queries via Cursor Blame, creating continuously refreshed evals from real engineering work that can’t be gamed like public benchmarks.
- Experience-side observability catches what code quality metrics miss. Factory Signals detects developer friction patterns — rephrasing, context churn, abandon-and-restart — without reading conversations, then auto-resolves 73% of issues in under 4 hours.
- Neither dimension alone is sufficient. An agent can ship clean code while frustrating the developer, or feel effortless while producing code that needs manual fixes downstream. Teams need both product-side and experience-side observability.
- The engineer’s role is shifting toward building feedback loops. The job is becoming less about writing code and more about building the environments where coding agents learn and improve on your specific systems.
The bottleneck was never code generation
The supply side is solved. GPUs ship. Models improve. Tokens get cheaper. Jensen’s trillion-dollar projection is a reasonable bet on continued scaling of the thing that already works.
The demand side has a different problem.
METR’s developer productivity study tried to measure whether AI coding tools actually make developers faster. The control group collapsed — participants found it nearly impossible to stop using AI tools even when asked to code without them. The tool is so embedded in workflows that we can’t cleanly measure its impact anymore.
That’s not evidence that AI coding tools work. It’s evidence that we can’t tell.
Teams are shipping AI-generated code at scale without knowing which agent workflows produce value and which ones burn tokens for nothing. No attribution. No quality signal. No feedback loop.
Two companies are building fundamentally different approaches to closing this gap. One measures the agent’s output quality. The other measures the developer’s experience quality. Both are necessary. Neither is sufficient alone.
CursorBench: did the agent ship good code?
Cursor built CursorBench, an evaluation system that answers a question most teams can’t: did the agent actually produce code worth committing?
The core mechanism is Cursor Blame. It traces committed code back to the agent request that produced it, creating natural pairings of developer queries with ground-truth solutions. No synthetic tasks. No contrived benchmarks. Every evaluation entry is a real engineering problem that a real developer solved with agent assistance.
The eval refreshes every few months against real engineering work. This matters. Public benchmarks go stale the moment models start training on them. CursorBench can’t be gamed because the dataset is private and continuously regenerated from actual developer output.
The results expose a gap that public benchmarks hide. Cursor found that Haiku can match GPT-5 on public benchmarks, but CursorBench reveals meaningful separation that tracks how developers actually experience quality in practice. The public leaderboard rankings and the CursorBench rankings diverge — and CursorBench is the one that predicts which model developers actually prefer.
This is product-side observability. It answers one question: is the agent good at its job, measured against the work developers actually do?
Factory Signals: did the developer feel productive?
Factory built Signals, an observability system that measures the other half — developer experience quality, even when the code compiles fine.
Signals analyzes thousands of agent sessions daily using LLMs as judges. It does this without reading a single user conversation. Sessions decompose into structured facets — languages used, developer intent, success versus abandonment — while preserving complete privacy.
Seven friction signals get tracked. Repeated rephrasing. Context churn. Abandon-and-restart patterns. Escalation to manual work. These are the signals that indicate a developer is struggling, even when the agent is technically producing output.
When friction patterns cross a threshold, Signals auto-files Linear tickets. Factory’s own Droid agent picks them up, implements fixes, and submits PRs. 73% of issues auto-resolve in under 4 hours.
The system literally improves itself.
This is experience-side observability. It answers a different question: is the developer productive — not just did the code compile?
Both are necessary
An agent can ship code that passes every test but frustrate the developer with five rounds of rephrasing to get there. An agent can feel effortless to use but consistently produce code that needs manual fixes downstream.
CursorBench catches quality problems you’d only see at commit time. Factory Signals catches experience problems you’d never see in the code at all.
| Dimension | CursorBench | Factory Signals |
|---|---|---|
| Measures | Agent output quality | Developer experience quality |
| Signal source | Committed code traced to agent queries | Session behavior patterns |
| Refresh cycle | Every few months (new eval from real work) | Daily (continuous session analysis) |
| Feedback loop | Informs model selection | Auto-files tickets, agent self-resolves |
| Blind spot | Doesn’t capture developer frustration | Doesn’t assess shipped code quality |
Neither alone is sufficient. Together, they define the minimum viable observability for a team that’s serious about knowing whether its AI investment is working.
The role that’s emerging
Cursor and Factory aren’t just building developer tools. They’re building learning systems.
CursorBench feeds real developer outcomes back into model selection — the eval results directly inform which model gets used for which type of task. Factory Signals detects friction patterns and auto-resolves them without human intervention. Both systems close the loop between agent output and agent improvement.
This is where the role of the software engineer starts to change.
The job isn’t writing code line by line. It’s building the environments where coding agents learn, adapt, and get better at your specific systems. Setting up the feedback loops. Tuning the observability. Curating the context that makes agents productive on your codebase, not just any codebase. OpenAI is already hiring for exactly this — “Software Engineer, Agent Infrastructure.”
And here’s the economic pressure that will make this non-optional: tokens won’t be free forever. At some point, engineers will operate on token budgets the way teams operate on cloud budgets today. When that happens, you’ll need to know exactly which agent workflows produce value and which ones burn tokens for nothing.
Measure first. Optimize second.
Before better prompts. Before better models. Before better context management. You need to know what’s working and what’s not.
The teams that build agent observability now — product-side and experience-side — will be the ones that know where their tokens go. Everyone else will be spending tokens and calling it progress.
Sources
- Jensen Huang GTC 2026 Keynote — $1T compute demand projection, token factory framing
- AI Coding Assistant Adoption Statistics — 84% developer adoption rate
- METR Developer Productivity Study — Control group collapse findings
- CursorBench — Product-side evaluation methodology, Cursor Blame system
- Factory Signals — Experience-side observability, 73% auto-resolve rate
- OpenAI Agent Infrastructure Role — Hiring for agent environment engineering
Stay in the loop
New posts delivered to your inbox. No spam, unsubscribe anytime.