🖖 Hand Gesture Recognition

📚 Problem Definition
The problem is to recognize sign-language hand gestures from a video stream. This is useful because it can be used to create human computer interfaces that are more accessible to people with hearing disabilities. My analysis assumes that the background is relatively static and that the hand is the only moving object in the video stream.
Some difficulties that I anticipate are:
- The hand can be in different orientations and positions in the video stream.
- The hand can be in different lighting conditions.
- The hand can be occluded by other objects in the video stream.
- The hand can be in motion.
The gestures are defined as follows:
- One: The thumb is extended and the other fingers are closed.
- Two: The thumb and the index finger are extended and the other fingers are closed.
- Three: The thumb, index finger, and middle finger are extended and the other fingers are closed.
- Four: The thumb, index finger, middle finger, and ring finger are extended and the little finger is closed.
- Five: All fingers are extended.





🛠️ Method and Implementation
Classical Computer Vision Algorithms
I use binary image analysis followed by max contour detection for the segmentation of the hand. I also use template matching (with templates augmented via different scales and rotations to capture possible scales and orientations of the hand) with the maximum normalized correlation coefficient for classifying the hand movement as the digit 1, 2, 3, 4, or 5. More detailed analysis of the algorithms used is provided below.
Binary Image Conversion Using Skin Color
By utilizing thresholding of RGB, HSV, and YCRB color profiles utilizing a combination of bitwise AND along with bitwise OR operators (which can be seen in the color_model_binary_image_conversion function I created here in my code) of an image as described in this paper, I was able to segment skin in an image with high accuracy. Using this mask, I was able to convert the original image to a binary image where the skin is black and the background is white. This binary image is then used for contour detection and template matching in the following steps.
Contour Detection for Hand Segmentation
After converting the image to a binary format, the next step is to segment the hand from the background. This is achieved through contour detection, a process used to find the outlines of objects within binary images. The algorithm I employ for this purpose is based on the principle of finding continuous curves that delineate object boundaries in an image. The specific steps are as follows:
-
Find Contours: Utilize OpenCV’s
findContoursfunction, which implements the Suzuki85 algorithm, to detect the contours in the binary image. This function returns a list of contours found, with each contour represented as a vector of points. -
Select Max Contour: Among all detected contours, the one with the maximum area is considered to represent the hand. This is based on the assumption that the hand is the largest skin-colored object in the image. The area of a contour is calculated using OpenCV’s
contourAreafunction. -
Draw/Use Contour: The maximal contour is then used either to create a mask for the hand or to extract the hand’s outline for further processing. This step is crucial for isolating the hand from the rest of the image, ensuring that subsequent steps operate solely on the hand region.
Mathematically, contour detection can be seen as the process of identifying the boundaries of a region in the binary image where . The Suzuki85 algorithm efficiently traces these boundaries by examining the connectivity of edge pixels in the image.
Template Matching for Sign Language Digit Classification
Template matching is a technique in computer vision used for finding areas of an image that match a template image. In the context of classifying hand movements as digits 1 through 5, I leverage template matching to compare the segmented hand region against a set of pre-defined templates corresponding to each digit. The process involves:
- Template Preparation: Generate a set of template images for each digit (1-5), capturing various scales and orientations to account for different hand sizes and positions. This augmentation ensures a comprehensive set of references for matching.





- Normalized Correlation Coefficient: For each template, calculate the match with the segmented hand using the normalized correlation coefficient. This metric measures the similarity between the template and portions of the target image, with a range from -1 (no match) to 1 (perfect match). Mathematically, it is defined as:
- Matching and Classification: For each digit’s set of templates, compute the NCC across the hand region. The digit whose template yields the highest NCC is determined to be the hand’s sign. This approach effectively classifies the hand gesture by finding the most similar template in terms of shape and orientation.
By employing these algorithms, the system can segment the hand from the background and classify its gesture into one of the five digits, using the principles of binary image analysis, contour detection, and template matching.
🔬 Experiments
I conducted the following experiments to evaluate the performance of the hand gesture recognition system and logged the results in the ./experiments directory with hydra configuration files. See more details about this in the usage section of the README.
Different Region of Interest (ROI) Sizes
I experimented with different regions of interest (ROI) to evaluate the performance of the hand gesture recognition system. The ROI is defined as the location in each frame where the processing happens (visually depicted by a green rectangle in my GUI). Intuitively, I saw the best performance when the ROI was centered around the hand. I decided to use an ROI width and height of 640 pixels and 790 pixels respectively. This is because using the full frame as the ROI would skew the results of the segmentation of the hand as the background would be included in the processing. Another practical implication is that the user can move their face outside of the ROI and not have it interfere with the processing of the hand gesture recognition system. Finally, the implementation of an ROI allows for a more intuitive and user-friendly experience for the user as they can see where the processing is happening.
Different Gamma Levels for Source Image
I experimented with different gamma levels for the source image to evaluate the performance of the hand gesture recognition system. The gamma level is a parameter that controls the brightness of the source image. After experimenting with gamma levels from 0.1 to 1.2, I found that the best performance was achieved when the gamma level was set to 0.375. This is because it allowed there to be a greater contrast between the hand and the background. The gamma level can be changed based on the lighting conditions of the environment.
Template Matching
Different Scales and Rotations
Traditional template matching is very error prone because it relies on the exact match of the template with the image in terms of size and orientation. To overcome this, I experimented with different scales and rotations of the template images to evaluate the performance of the hand gesture recognition system. I found that the best performance was achieved when the template images were augmented with different scales and rotations. This is because it allowed the system to recognize the hand gesture even if the hand was in different orientations and positions in the video stream. The system was able to recognize the hand gesture even if the hand was occluded by other objects in the video stream.
I ended up using the following scales (scale factor) and rotations (in degrees) for the template images:
- Scales: [0.7, 0.8, 0.9, 1.0]
- Rotations: [-20.0, -10.0, 0.0, 10.0, 20.0]
Front and Back Camera Template Images
Another important experiment I conducted was to evaluate the performance of the system with template images taken with a front and back camera. I found that the system was able to perform better when the template image were taken with the same type of camera as the intended use. This is because the two different cameras lead to different orientations and shapes of the hand. I have included the template images taken with the front and back camera in the ./templates directory. The template image can be specified by the user depending on whether they are using the front or back camera in the GUI (see the advanced usage section of the README for more details about this).
Hand Template Image vs Finger Template Image
I experimented with using a hand template image and a finger template image to evaluate the performance of the hand gesture recognition system. I found that the system was able to perform much better with a hand template image. This is because the hand template image was able to capture the shape and orientation of the hand better than the finger template image.
📈 Results
I ran 20 trials with each finger to evaluate the performance of the hand gesture recognition system. For instance, I used the following command for the sign language digit 5 with 20 frames and a 5-second delay to start the camera and allow the user to prepare their hand for the gesture recognition system to capture the frames and process them for classification:
python main.py \hydra.job.name=class_5 \processing.ground_truth_label=5 \camera.num_frames=20 \camera.start_delay_seconds=5The following are the results of the experiments which I logged in the ./experiments directory. Then I used the ./tools/evaluate.py script to evaluate the performance of the hand gesture recognition system and logged the results in the ./reports directory.
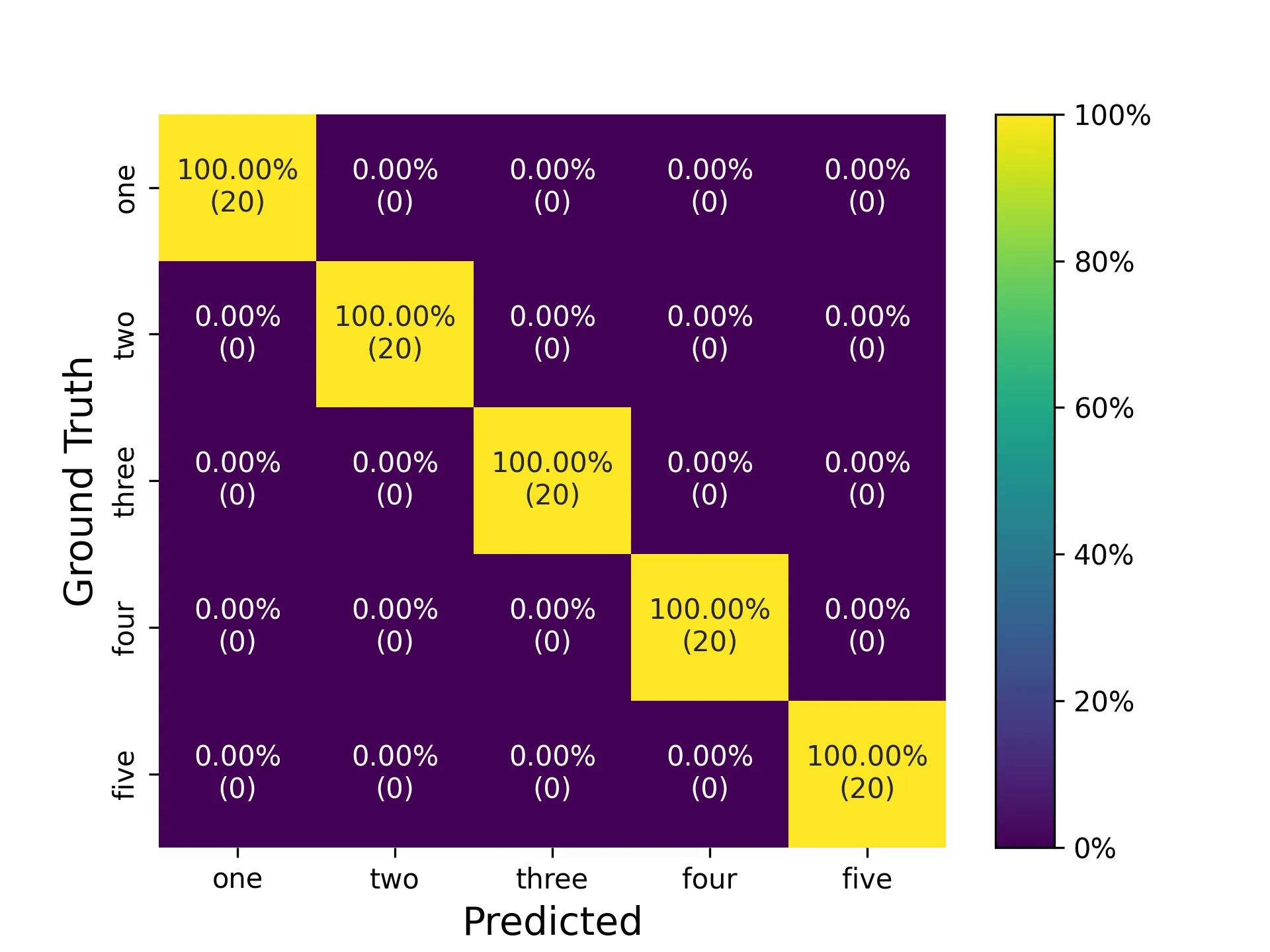
Confusion Matrix
🗣️ Discussion
The performance of the system is impressive given the simplicity of the algorithms used. In the experiments I ran, the system was able to classify the sign-language digit 5 with 100% accuracy. However, the environment I ran my experiments in was relatively controlled with a static background and good lighting conditions. Using binary image analysis, max contour detection for the segmentation of the hand, and template matching proved to be a basic system to recognize sign-language hand gestures from a video stream.
🏆 Conclusions
While it is possible to recognize sign-language hand gestures from a video stream using classical computer vision algorithms, the performance of the hand gesture recognition system is far from perfect. Additionally, the amount of processing that occurs per frame makes the algorithm very slow (re-implementing things in C++ could help 😊). The system works best when the user tries to shape their hand to mimic the template images for the sign-language digit (1-5) that they are trying to automatically classify. The hand should be still and the background should be relatively static with not too much overexposure or underexposure in the camera. The system will not work well if the hand is in motion or if the background is not relatively static. Future work could involve using machine learning or deep learning algorithms to improve the performance of the hand gesture recognition system.
🎬 Credits and Bibliography
👥 Collaborators
- None